Spark Notes 2 - Core Concepts (SparkContext、RDD、Stage、Executor)
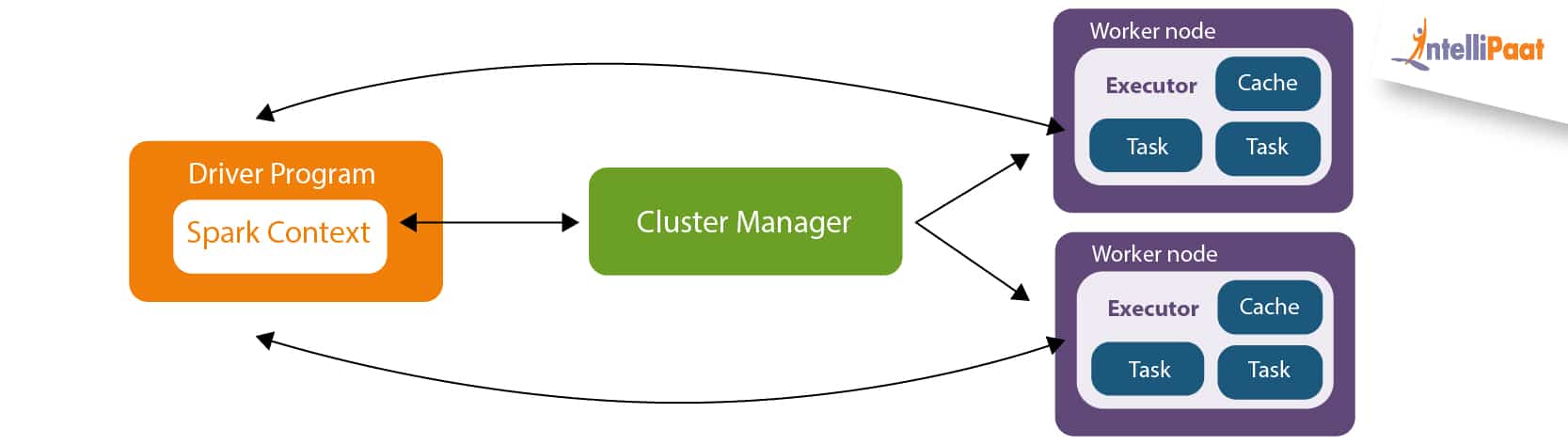
Recap Spark’s introduction and the word count program.
understanding SparkContext, Stages, Executors, and RDDs for effective Spark application development.
1. SparkContext
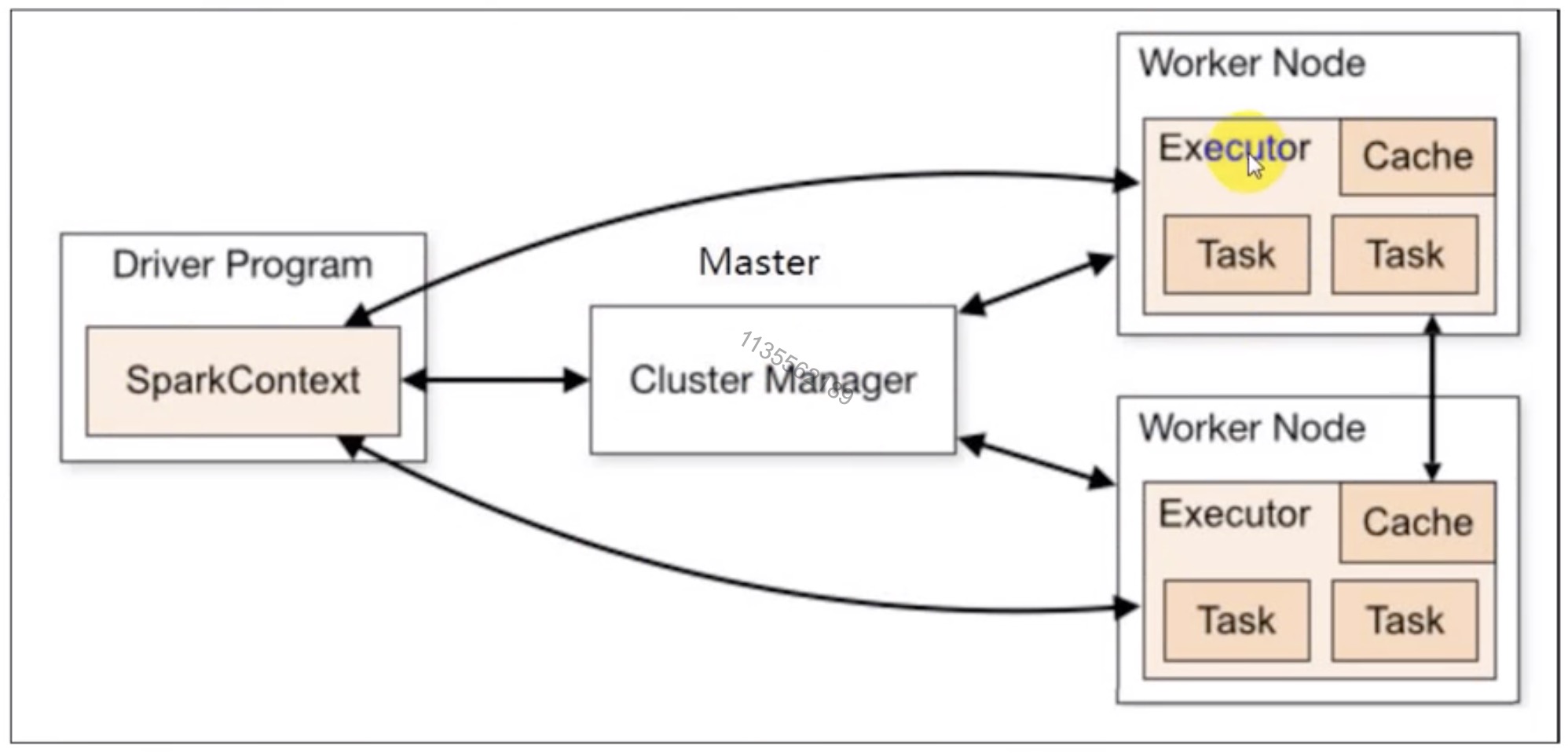
SparkContext provides the various functions in Spark like get the current status of Spark Application, set the configuration, cancel a job, Cancel a stage and much more.
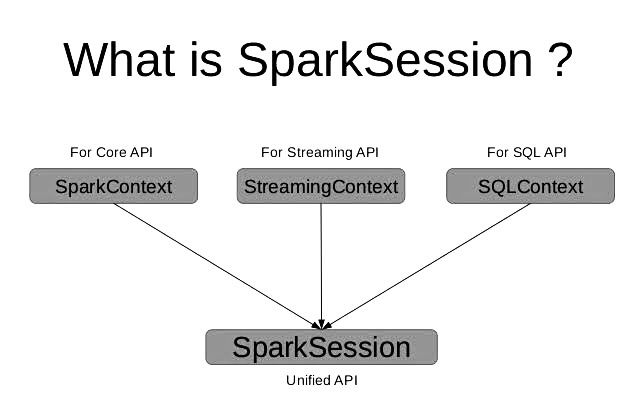
SparkContext vs SparkSession
| Feature | SparkContext (Spark 1.x ) | SparkSession (Spark 2.0) |
|---|---|---|
| Introduction | Spark 1.x as the entry point to Spark applications. | Spark 2.0 as the unified entry point to Spark features. Includes a reference to the underlying SparkContext. |
| Usage | Used mainly for RDD and low-level API operations. | Main interface for working with SparkSQL, DataFrame, and DataSet. |
| Advantages | Direct access to Spark’s core functionalities. | Simplified API for DataFrame and DataSet operations. Unified API access. |
2. Core Concepts
| Core Aspect | Description |
|---|---|
| Core Functions | SparkContext, Storage System, Execution Engine DAGScheduler, Deployment Modes SparkContext, 存储体系, 执行引擎 DAGScheduler, 部署模式 |
| Application | A user program built on Spark consisting of a driver program and executors on the cluster. 用户在Spark上构建的程序,包括驱动程序和集群上的执行器。 |
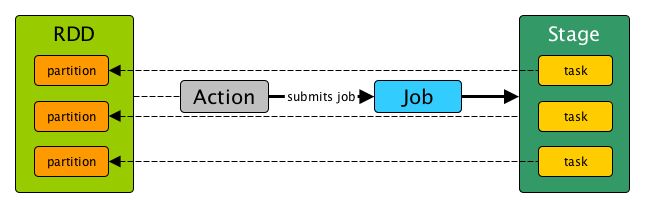
| Job | The set of transformations and actions on data; split based on actions. 数据的一系列转换和动作;基于动作进行切分。 |
| Stage | Jobs are divided into stages at shuffle boundaries; split based on wide dependencies. 作业在shuffle界限处被划分为阶段;基于宽依赖进行切分。 |
| Task | The smallest unit of work sent to an executor; types include ShuffleMapTask and ResultTask. 发送到执行器的最小工作单元;类型包括ShuffleMapTask和ResultTask。 |
| Driver Application | Acts as the client program converting any program into RDDs and DAGs, communicating with the Cluster Manager. 充当客户端程序,将任何程序转换为RDD和DAG,并与集群管理器通信。 |
| Programming Model | including loading data, applying transformations and actions, and processing results. |
1 | from pyspark.sql import SparkSession |
| No. | Action | Description |
|---|---|---|
| 1 | Obtain the programming entry point / 获取编程入口 | SparkContext |
| 2 | Load data to get a data abstraction / 通过编程入口使用不同的方式加载数据得到一个数据抽象 | RDD |
| 3 | Process the loaded data abstraction with different operators | Transformation + Action |
| 4 | Process the result data as RDD/Scala objects or collections | print or save |
2. RDD (resilient distributed dataset)
Apache Spark evaluates RDDs lazily. It is called when needed, which saves lots of time and improves efficiency. The first time they are used in an action so that it can pipeline the transformation. Also, the programmer can call a persist method to state which RDD they want to use in future operations.
2.1 Concept
RDD Concept an immutable, partitioned collection that allows for distributed data processing across a cluster.
- A list of partitions / 分区
- A function for computing on other RDDs / 作用在每个分区之上的一个函数
- A list of dependencies on other RDDs / 依赖: 宽依赖 & 窄依赖
- Optionally, a Partition for key-value RDDs (e.g. to say that the RDD is hash-partitioned) / KeyValueRDD 分区器
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
2.2 Attributes
2.3 Create RDD
- Parallelizing an existing collection:
1 | data = [1, 2, 3, 4, 5] |
- Referencing External Datasets
1 | rdd = spark.sparkContext.textFile("path/to/textfile") |
2.4 Operations
- Transformation. RDD -> RDD
- Action. RDD returns final result of RDD computations.
- Cronroller,(cache/persist)
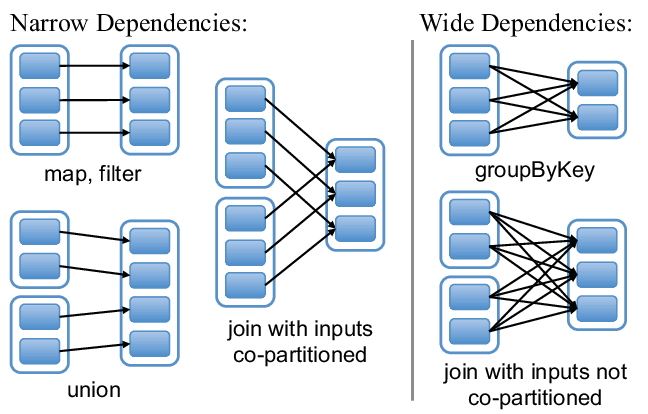
3. Stage & DAG
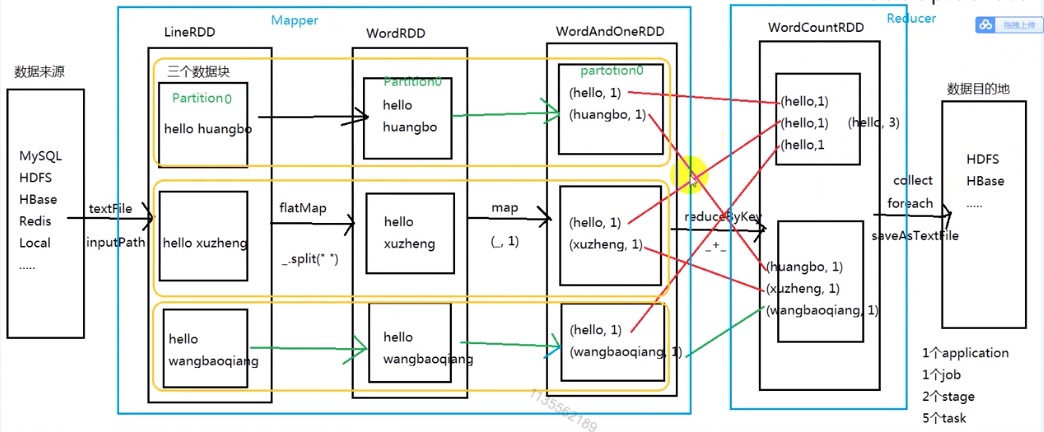
3.1 WordCount FlowChart
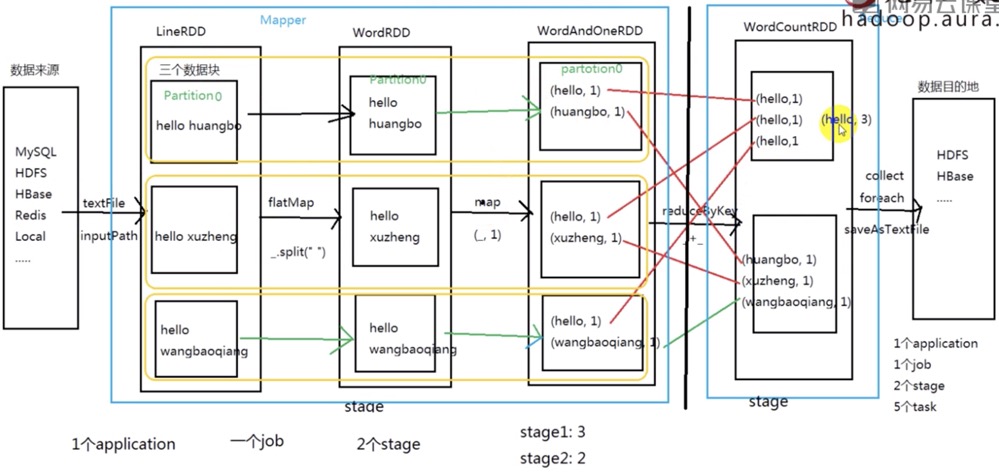
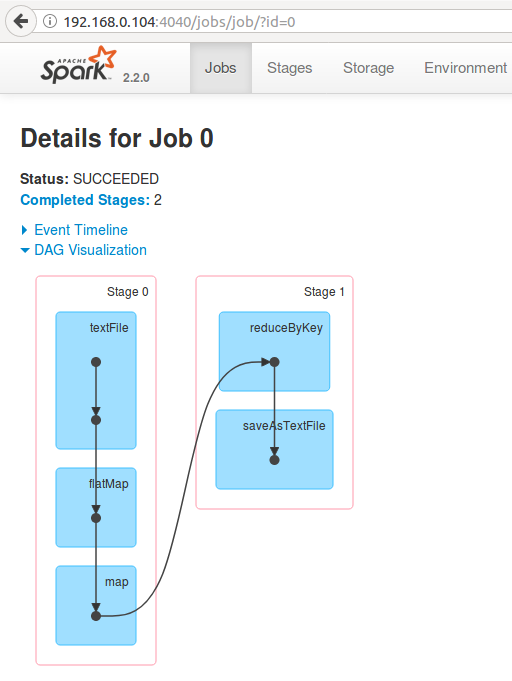
3.2 Stage & DAG
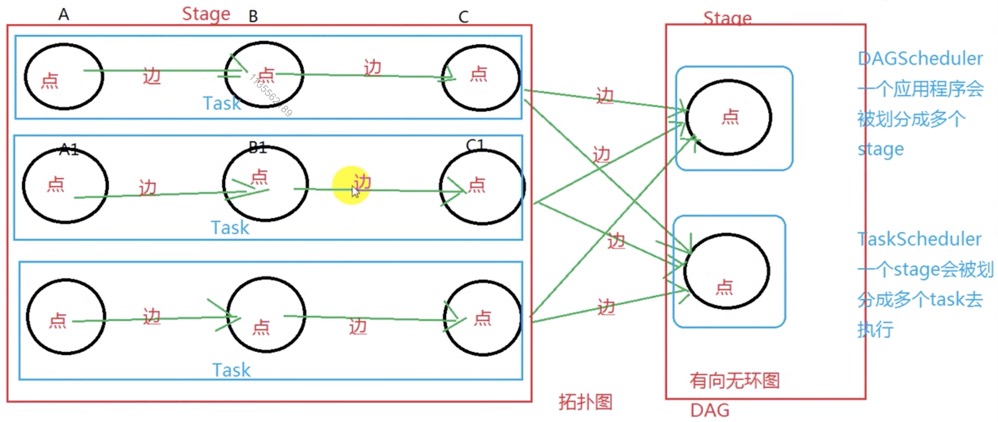
| Concept | Description |
|---|---|
| Application | A complete program built on Spark, consisting of a set of jobs |
| Job | A sequence of computations triggered by an action operation, split based on actions from front to back. A job is decomposed into multiple stages, with stages divided based on RDD’s wide dependencies (shuffle dependencies). Each action operation submits a job. A job consists of a series of stages that are executed in sequence based on RDD’s wide dependencies. Each stage encapsulates a group of tasks that can be executed in parallel, and the completion of a job is achieved by sequentially executing these stages. 由action操作触发的一系列计算,根据动作从前往后切分。Job被分解成多个Stage; Stage是基于RDD的宽依赖(shuffle依赖)来划分的。每个action操作会提交一个Job。Job是由一系列Stage组成的,这些Stage基于RDD的宽依赖被顺序执行; 每个Stage是对一组可以并行执行的任务的封装,而Job的完成则是通过顺序执行这些Stage来实现的。 |
| Stage | Jobs are divided into stages at wide dependencies, split from back to front. Stages are formed at shuffle type/wide dependencies, with narrow dependencies incorporating the RDD into the stage. The boundary of a stage is shuffle: wide dependencies are introduced when an operation needs to redistribute data, such as grouping by key. Therefore, the boundary of a stage is where the data shuffle occurs. 从后往前找shuffle类型/宽依赖的算子,遇到一个就断开,形成一个stage;遇到窄依赖就将这个RDD加入该stage中。当一个操作需要对数据进行重新分布,比如通过key进行分组时,这就引入了宽依赖。Spark会在这些宽依赖的位置切分Stage,因此,Stage的边界就是数据shuffle的地方。 |
| 关系 | A job contains multiple stages. Tasks within a stage can be executed in parallel, but there is a sequential order between multiple stages; the next stage will only start after all tasks in the current stage are completed. 一个Job包含多个Stage。Stage内的任务可以并行执行,但多个Stage之间是有先后顺序的;只有当一个Stage中的所有Task执行完成后,下一个Stage才会开始执行。 |
| Execution Process | During execution, each stage is decomposed into multiple tasks by the TaskScheduler, and these tasks are executed in parallel by Executors. The execution of stages is sequential, but tasks within a stage are parallel. The completion of a job relies on the sequential execution and completion of all stages. 执行过程中,每个Stage被TaskScheduler分解成多个Task,这些Task由Executor并行执行。Stage的执行是顺序的,但Stage内的Task是并行的。Job的完成依赖于所有Stage的顺序执行和完成。 |
| Task | The smallest unit of work in Spark, executed on the cluster. Each RDD can specify a different number of partitions. By default, each partition will be a Task. Spark中执行的最小工作单元。每个RDD可以指定不同的分区数。默认情况下:每个分区将是一个Task。 |
| 2 Task Types | Split into ShuffleMapTask and ResultTask: - ShuffleMapTask: Prepares data for a shuffle before the next stage. - ResultTask: Executes at the final stage for each partition’s result. 分为 ShuffleMapTask和ResultTask:- ShuffleMapTask:在下一个阶段之前准备shuffle的数据。 - ResultTask:在最后一个阶段为每个分区的结果执行;简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的 |
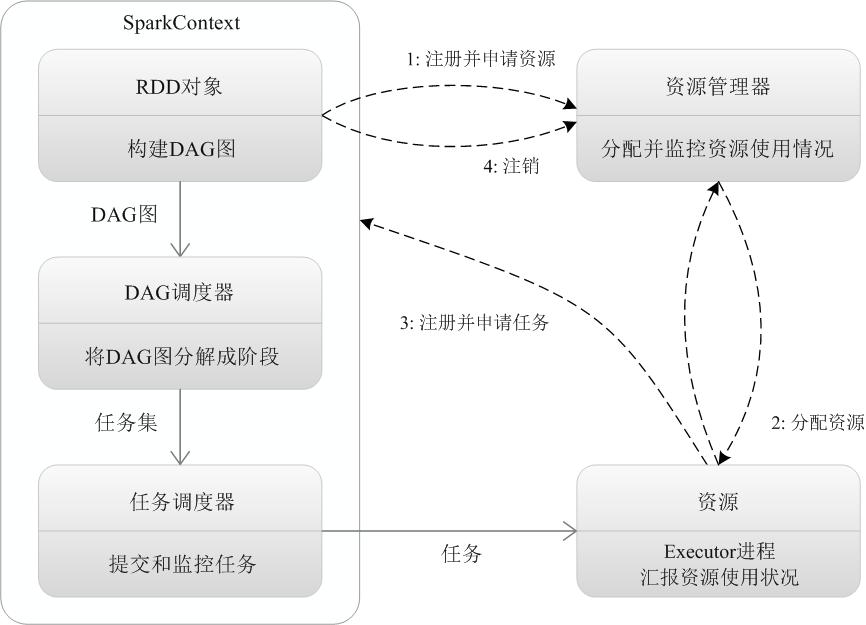
3.3 DAGScheduler Workflow
| No. | DAGScheduler Workflow |
|---|---|
| 1 | spark-submit submits the application. |
| 2 | Initializes DAGScheduler and TaskScheduler. |
| 3 | Upon receiving the application, DAGScheduler first abstracts the application into a DAG. |
| 4 | DAGScheduler splits this DAG (one of its jobs) into stages. DAGScheduler 对这个 DAG (DAG中的一个Job) 进行 stage 的切分。 |
| 5 | Each stage is submitted to TaskScheduler. |
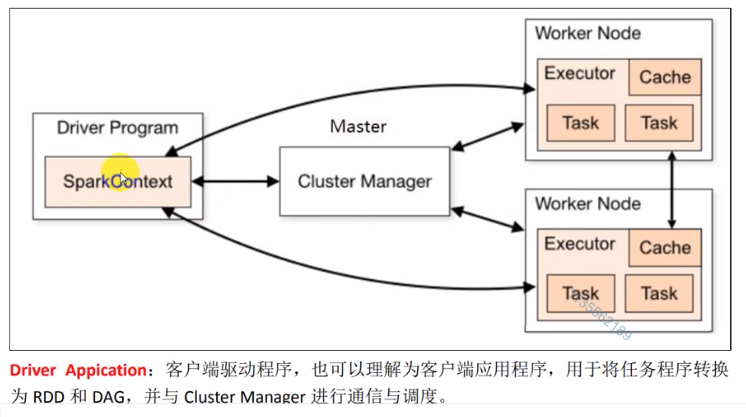
4. Executor
| Mode | Client vs. Cluster Submission Mode |
|---|---|
| Client Mode | In client mode, the driver program runs on the client node. |
| Cluster Mode | In cluster mode, the driver program runs within a worker node. |
Spark application with a simple example.
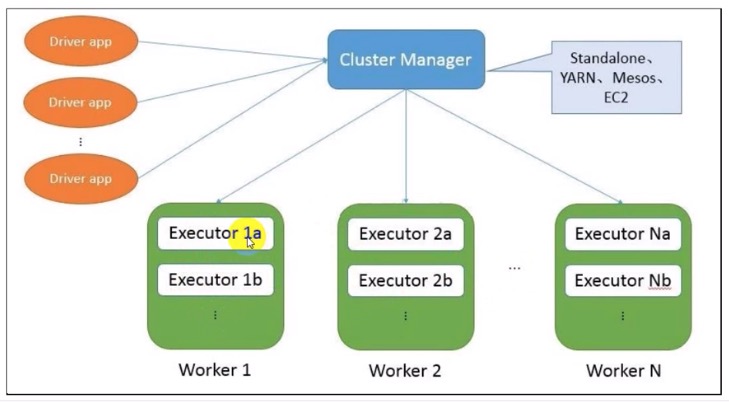
Spark Executors are helpful for executing tasks. we can have as many executors we want. Therefore, Executors helps to enhance the Spark performance of the system.
5. Application
Reference
- spark中如何划分stage
- Spark广播变量和累加器详解
- 马老师-Spark的WordCount到底产生了多少个RDD
- 大数据技术之_19_Spark学习_02_Spark Core 应用解析 实例练习
- 程序员虾说:Spark Transformation算子详解
- linsay Offer帮 英语学习包
- data-flair.training/blogs
- Spark RDD Operations-Transformation & Action with Example
- Spark RDD常用算子学习笔记详解(python版)
- Spark常用的Transformation算子的简单例子
Spark Notes 3 - RDD (Resilient Distributed Dataset) 【待完善】
Resilient Distributed Datasets (RDDs) are a fundamental data structure of Apache Spark designed...
Spark Notes 1 - Introduction, Ecosystem and WordCount
Apache Spark is a unified analytics engine for large-scale data processing 1. Spark - Introduc...
Checking if Disqus is accessible...