Spark Notes 3 - RDD (Resilient Distributed Dataset) 【待完善】
Resilient Distributed Datasets (RDDs) are a fundamental data structure of Apache Spark designed for efficient distributed data processing.
Apache Spark evaluates RDDs lazily. It is called when needed, which saves lots of time and improves efficiency. The first time they are used in an action so that it can pipeline the transformation. Also, the programmer can call a persist method to state which RDD they want to use in future operations.
1. Concept
RDD Concept an immutable, partitioned collection that allows for distributed data processing across a cluster.
- A list of partitions / 分区
- A function for computing on other RDDs / 作用在每个分区之上的一个函数
- A list of dependencies on other RDDs / 依赖: 宽依赖 & 窄依赖
- Optionally, a Partition for key-value RDDs (e.g. to say that the RDD is hash-partitioned) / KeyValueRDD 分区器
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
2. Attributes
- Immutability: Once created, the data in RDD cann’t changed. This ensures data consistency & fault tolerance.
- Resilience: RDDs are fault-tolerant, meaning they can recover quickly from failures using lineage information.
- Distributed: The data in RDDs is distributed across the cluster, allowing parallel processing on multiple nodes.
- Partitioning: RDDs are divided into partitions, which can be processed in parallel across the cluster.
- Lazy Evaluation: RDDs are lazily evaluated, meaning computations on them are delayed until an action is performed, optimizing overall data processing efficiency.
3. Creating RDDs
RDDs can be created in two main ways:
- Parallelizing an existing collection:
1 | data = [1, 2, 3, 4, 5] |
- Referencing External Datasets
1 | rdd = spark.sparkContext.textFile("path/to/textfile") |
4. Persistence and Caching
Persistence and caching are critical for optimizing the performance of RDDs. The cache() method defaults to storing RDDs in memory (MEMORY_ONLY), while persist() allows for choosing among different storage levels.
What is RDD persistence, Why do we need to call cache or persist on an RDD, What is the Difference between Cache() and Persist() method in Spark

What is RDD Persistence and Caching
The difference between cache() and persist() is that using cache() the default storage level is MEMORY_ONLY while using persist() we can use various storage levels (described below).
- Time efficient
- Cost efficient
- Lessen the execution time.
Storage levels of Persisted RDDs
- MEMORY_ONLY
- MEMORY_AND_DISK
- MEMORY_ONLY_SER
- MEMORY_AND_DISK_SER
- DISK_ONLY
How to Unpersist RDD in Spark?
using RDD.unpersist() method.
in spark is designed as each dataset in RDD is divided into logical partitions. Further, we can say here each partition may be computed on different nodes of the cluster.
cache:
正常情况下: 一个RDD中是不包含真实数据的,只包含描述这个RDD的源数据信息
如果对这个RDD调用 cache 方法
那么这个rdd中的数据,现在依然还是没有真实数据
直到第一次调用一个action的算子出发了这个RDD的数据生成,那么cache 操作
cache()
persist() == persist(StorageLevel.MEMORY_ONLY)
persist(StorageLevel.XXXX)
一个 RDD 代表一系列的“记录”(严格来说,某种类型的对象)。
这些记录被分配或分区到一个集群的多个节点上(在本地模式下,可以类似地理解为单个进程里的多个线程上)。
3. RDD缓存策略
Spark最为强大的功能之一便是能够把数据缓存在集群的内存里。这通过调用RDD的cache函数来实现:
1 | scala> rddFromTextFile.cache |
在RDD首次调用一个执行操作时,这个操作对应的计算会立即执行,数据会从数据源里读出并保存到内存。因此,首次调用cache函数所需要的时间会部分取决于Spark从输入源读取数据所需要的时间。但是,当下一次访问该数据集的时候,数据可以直接从内存中读出从而减少低效的I/O操作,加快计算。多数情况下,这会取得数倍的速度提升。
Spark支持更为细化的缓存策略。通过persist函数可以指定Spark的数据缓存策略。关于RDD缓存的更多信息可参见:http://spark.apache.org/docs/latest/programming-guide.html#rdd-persistence。
1 | def cache(): this.type = persist() |
一个普通的文件 file ===》 内存
该 file 被序列化了 ===》 内存
JVM 最大的区域是 Head 内存, OffHeap 堆外内存
各种 byKey 操作 (重要)
----union, join, coGroup, subtract, cartesian----
- groupByKey
- reduceByKey
- aggregateByKey
- sortByKey
- combineByKey
Storage Levels:
- MEMORY_ONLY
- MEMORY_AND_DISK
- MEMORY_ONLY_SER
- MEMORY_AND_DISK_SER
- DISK_ONLY
Unpersisting RDDs:
To release the resources used by an RDD, you can use the unpersist() method.
5. Broadcast and Accumulators
Spark的另一个核心功能是能创建两种特殊类型的变量:广播变量 和 累加器。
广播变量(broadcast variable)为只读变量,它由运行SparkContext的驱动程序创建后发送给会参与计算的节点。对那些需要让各工作节点高效地访问相同数据的应用场景,比如机器学习,这非常有用。
Spark下创建广播变量只需在SparkContext上调用一个方法即可:
1 | scala> val broadcastAList = sc.broadcast(List("a", "b", "c", "d", "e")) |
广播变量 也可以被非驱动程序所在的节点(即工作节点)访问,访问的方法是调用该变量的value方法:
1 | scala> val broadcastAList = sc.broadcast(List("a", "b", "c", "d", "e")) |
注意,collect 函数一般仅在的确需要将整个结果集返回驱动程序并进行后续处理时才有必要调用。如果在一个非常大的数据集上调用该函数,可能耗尽驱动程序的可用内存,进而导致程序崩溃。
高负荷的处理应尽可能地在整个集群上进行,从而避免驱动程序成为系统瓶颈。然而在不少情况下,将结果收集到驱动程序的确是有必要的。很多机器学习算法的迭代过程便属于这类情况。
累加器(accumulator)也是一种被广播到工作节点的变量。累加器与广播变量的关键不同,是后者只能读取而前者却可累加。
Broadcast variables allow the program to efficiently send a large, read-only variable to all worker nodes for use in one or more Spark operations.
Accumulators are variables that are only “added” to, using an associative and commutative operation, so they can be efficiently supported in parallel.
5.1 广播变量
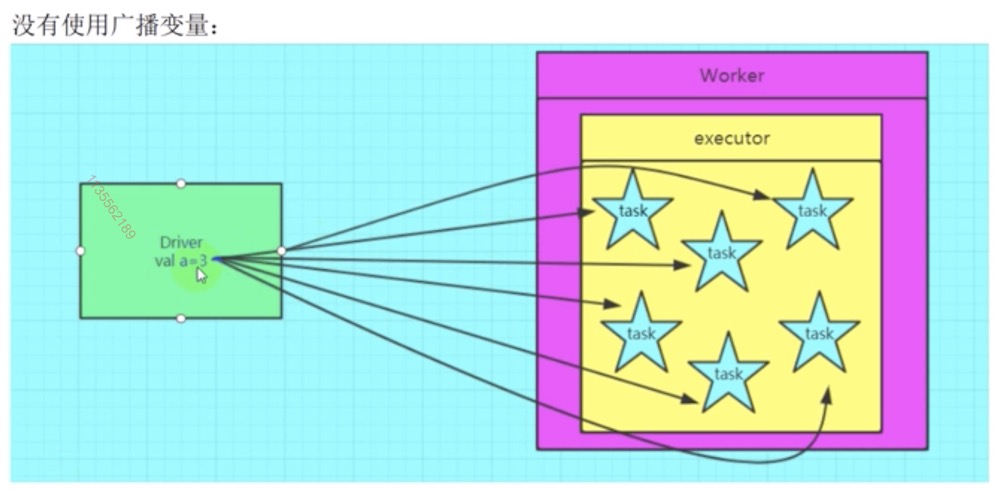
线程可以共享变量的思路
广播变量:
(1) 在默认情况下,每一个task都会维持一个全局变量的副本
有一个集合:100M 在 driver 中生成, 但是在所有的task中都需要使用
那么,每一个 task 都会维持一个当前这 100M 数据的副本
如果一个 executor 中启动了 6 个 task,最终消耗 600M 内存
(2). 如果使用广播变量的话
那么可以把当前这个100M的数据,就编程一个广播变量的值
用 driver 中的 sparkcontext 进行 全局所有 executor 广播
最后的效果:每个 executor 中只存在一份这个广播变量的副本
而不是原先的每一个task都保持一个副本
所以最终的内存消耗量: 100m
(3) 最后的效果:
- 减少了网络数据传输的量
- 减少了executor的内存使用
如果一个值很小,那么几乎没有广播的必要。
广播的值的大小越大,效果越明显
5.2 累加器
1 | val a = sc.accumulator(0) |
还原一个累加器
1 | val b = a.value |
spark 的累加器 和 mapreduce编程模型的全局计数器是一个道理。
map mapPartitions
join mapjoin reducejoin
cogroup
coalesce
repartition
repartitionAndSortWithinPartitions
重新分区, 并且分区内数据进行排序
1 | val acc = sc.accumulator(0) |
Advanced RDD Features
RDD Operations: Transformation and Actions
Spark evaluates RDDs lazily, only executing transformations when an action is called. This approach enhances efficiency and allows for complex computational pipelines.
RDD Attributes
Immutability and Fault Tolerance: Once an RDD is created, it cannot be changed. This design ensures data consistency and makes RDDs fault-tolerant.
Partitioning: Data in an RDD is divided into partitions, allowing for distributed processing.
Lazy Evaluation: RDD operations are lazily evaluated, optimizing processing efficiency.
RDD Operations{: width=“500px”}
RDD Caching Strategies
Caching or persisting RDDs can significantly improve the performance of Spark applications by reducing the need to recompute intermediate results.
Conclusion
RDDs are a powerful component of Apache Spark, offering robust capabilities for distributed data processing. Understanding how to create, persist, and manipulate RDDs is essential for developing efficient Spark applications.
Reference
- Spark Transformations
- 关于累加器的更多信息,可参见《Spark编程指南》
- Spark广播变量和累加器详解
- 马老师-Spark的WordCount到底产生了多少个RDD
- 大数据技术之_19_Spark学习_02_Spark Core 应用解析+ RDD 概念 + RDD 编程 + 键值对 RDD + 数据读取与保存主要方式 + RDD 编程进阶 + Spark Core 实例练习
- Offer帮 英语学习包
- spark combinebykey?
- pyspark中combineByKey的两种理解方法
- Spark原理篇之RDD特征分析讲解
- PySpark 3.0.1 documentation »
- data-flair.training/blogs
- Spark RDD Operations-Transformation & Action with Example
- Spark RDD常用算子学习笔记详解(python版)
- Spark常用的Transformation算子的简单例子
Checking if Disqus is accessible...