Rondom Forest vs GBDT

1. Random Forest
Rondom Forest 是一个典型的多个决策树的组合分类器.
Rondom Forest, 的 Random 体现在 2 个方面:
- data random
- feature random
RF、bagging、boosting、GBDT、xgboost算法总结
Sample data Random:
<img class=“img-fancy” src="/images/ml/ensumble/ensumble-2.jpg", width=“600” border=“0px” %}
Feature Random:
与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
<img class=“img-fancy” src="/images/ml/ensumble/ensumble-3.jpg", width=“600” border=“0px” %}
2. GBDT
GBDT 是以决策树(CART)为基学习器的 GB算法,是迭代树,而不是分类树。
一般 Boosting 算法都是一个迭代的过程,每一次新的训练都是为了改进上一次的结果。
<img class=“img-fancy” src="/images/ml/ensumble/ensumble-4.jpg", width=“600px” %}
GBDT 的核心就在于:每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。
<img class=“img-fancy” src="/images/ml/ensumble/ensumble-5.jpg", width=“850px” %}
3. RF vs GBDT
- 组成 RF 的树可以是分类树,也可以是回归树;而GBDT只由回归树组成
- 组成 RF 的树可以并行生成;而 GBDT 只能是串行生成.
- 对于最终的输出结果而言,随机森林采用多数投票等;而 GBDT 则是将所有结果累加起来,或者加权累加起来.
- RF 对异常值不敏感,GBDT 对
异常值非常敏感.- RF 对训练集一视同仁,GBDT 是基于权值的弱分类器的集成.
- RF 是通过减少模型
方差提高性能,GBDT是通过减少模型偏差提高性能.
4. Xgboost vs GBDT
Xgboost相比于GBDT来说,更加有效应用了数值优化,最重要是对损失函数(预测值和真实值的误差)变得更复杂。目标函数依然是所有树的预测值相加等于预测值。
- 二阶泰勒展开,同时用到了一阶和二阶导数
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)
- 列抽样(column subsampling)。xgboost借鉴RF做法,支持列抽样(即每次的输入特征不是全部特征)
- 并行化处理: 预先对每个特征内部进行了排序找出候选切割点.各个feature的增益计算就可以开多线程进行.
<img class=“img-fancy” src="/images/ml/ensumble/ensumble-6.jpg", width=“600px” %}
好的模型需要具备两个基本要素:
- 是要有好的精度(即好的拟合程度)
- 是模型要尽可能的简单(复杂的模型容易出现过拟合,并且更加不稳定)
因此,我们构建的目标函数右边第一项是模型的误差项,第二项是正则化项(也就是模型复杂度的惩罚项)
常用的误差项有平方误差和逻辑斯蒂误差,常见的惩罚项有l1,l2正则,l1正则是将模型各个元素进行求和,l2正则是对元素求平方。
ID3、C4.5、CART、随机森林、bagging、boosting、Adaboost、GBDT、xgboost算法总结
5. Bagging vs Boosting
两种方法的采样和处理方式都不同,主要代表算法便是: Rondom Forest、 GBDT.
5.1 Bagging
Bagging 的思想比较简单,即每一次从原始数据中根据 均匀概率分布有放回的抽取和原始数据大小相同的样本集合,样本点可能出现重复,然后对每一次产生的训练集构造一个分类器,再对分类器进行组合。
5.2 Boosting
Boosting 的每一次抽样的 样本分布都是不一样 的。每一次迭代,都根据上一次迭代的结果,增加被错误分类的样本的权重,使得模型能在之后的迭代中更加注意到 难以分类的样本,这是一个 不断学习的过程,也是一个不断提升 的过程,这也就是boosting思想的本质所在。 迭代之后,将每次迭代的基分类器进行集成。那么如何进行样本权重的调整和分类器的集成是我们需要考虑的关键问题。
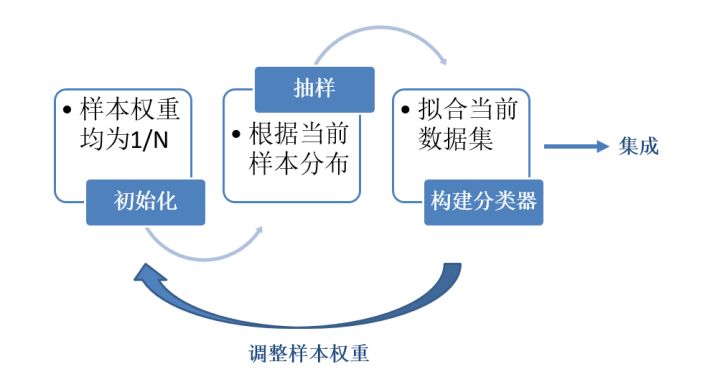
6. 特征重要度
6.1 RF 特征度量
(1)对每一颗决策树,选择相应的袋外数据(out of bag,OOB)计算袋外数据误差,记为errOOB1.
所谓袋外数据是指,每次建立决策树时,通过重复抽样得到一个数据用于训练决策树,这时还有大约1/3的数据没有被利用,没有参与决策树的建立。这部分数据可以用于对决策树的性能进行评估,计算模型的预测错误率,称为袋外数据误差。
这已经经过证明是无偏估计的,所以在随机森林算法中不需要再进行交叉验证或者单独的测试集来获取测试集误差的无偏估计。
(2)随机对袋外数据OOB所有样本的特征加入噪声干扰(可以随机改变样本在特征X处的值),再次计算袋外数据误差,记为errOOB2。
(3)假设森林中有N棵树,则特征X的重要性=∑(errOOB2-errOOB1)/N。这个数值之所以能够说明特征的重要性是因为,如果加入随机噪声后,袋外数据准确率大幅度下降(即errOOB2上升),说明这个特征对于样本的预测结果有很大影响,进而说明重要程度比较高。
6.2 GBDT 特征度量
主要是通过计算特征i在单棵树中重要度的平均值,计算公式如下:
其中,M是树的数量。特征i在单棵树的重要度主要是通过计算按这个特征i分裂之后损失的减少值.
其中,L是叶子节点的数量,L-1就是非叶子结点的数量。
6.3 Xgboost
XGboost是通过该特征每棵树中分裂次数的和去计算的,比如这个特征在第一棵树分裂1次,第二棵树2次……,那么这个特征的得分就是(1+2+…)。
Checking if Disqus is accessible...