Evaluation Metric
选择与问题相匹配的评估方法,才能快速发现在 模型选择和训练过程 中可能出现的问题,迭代地对模型进行优化. 针对 分类、排序、回归、序列预测 等不同类型的机器学习问题,评估指标的选择也有所不同:
本文将谈谈机器学习中,常用的性能评估指标:
<img class=“img-fancy” src="/images/ml/metric/metric-2.jpg", width=“600” border=“0px”, alt=""%}
关于模型评估的基础概念:
【误差(error)】:学习器的预测输出与样本的真实输出之间的差异。根据产生误差的数据集,可分为:
- Training error:又称为经验误差(empirical error),学习器在训练集上的误差。
- Test error:学习器在测试集上的误差。
- Generalization error:学习器在未知新样本上的误差。
需要注意的是,上述所说的“误差”均指误差期望,排除数据集大小的影响。
应该从训练样本中尽可能学出适用于所有 潜在样本的“普遍规律”,这样才能在遇到新样本时做出正确的判别。因为,泛化误差无法测量,因此,通常我们会将 Test error 近似等同于 Generalization error。
1. Classification Metric
1.1 Accuracy
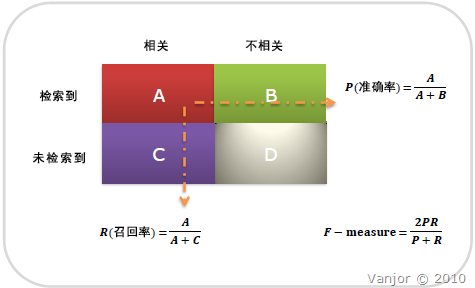
准确率:指的是分类正确的样本数量占样本总数的比例,定义如下:
正反比例严重失衡,则没意义,存在 accuracy paradox 现象.
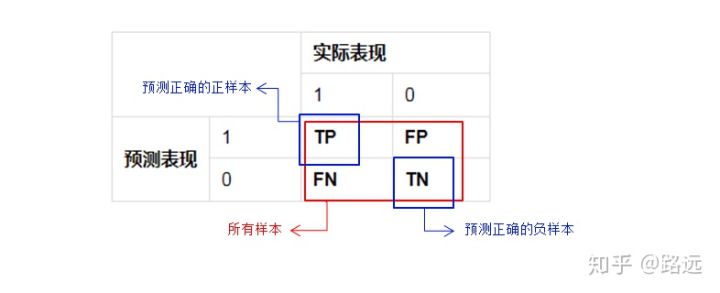
accuracy 准确率 = (TP+TN)/(TP+TN+FP+FN), 准确率可以判断总的正确率
1.2 Precision
precision 查准率 (80% = 你一共预测了100个正例,80个是对的正例)

Precision = TP/(TP+FP)
1.3 Recall
recall (样本中的正例有多少被预测正确 TPR = TP/(TP+FN))

1.4 F1-score
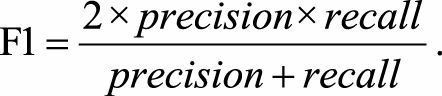
multi-class classification
如果非要用一个综合考量的 metric 的话,
- macro-average(宏平均)- 分布计算每个类别的F1,然后做平均(各类别F1的权重相同)
- micro-average(微平均)- 通过先计算总体的TP,FN和FP的数量,再计算F1
macro-average(宏平均) 会比 micro-average(微平均)好一些哦,因为 macro 会受 minority class 影响更大,也就是说更能体现在 small class 上的 performance.
precision & recall
precision 是相对你自己的模型预测而言
recall 是相对真实的答案而言
1.5 P-R curve
P-R曲线的横轴是召回率,纵轴是精确率。对于一个排序模型来说,其P-R曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本, 小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。
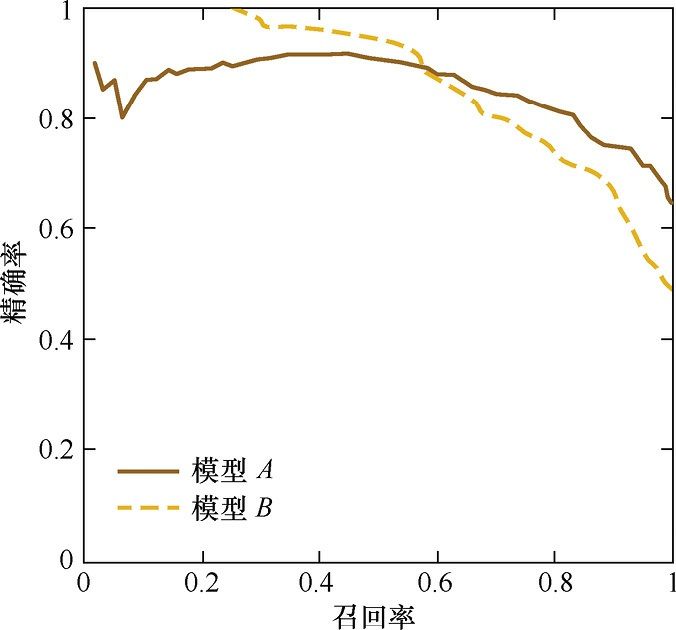
整条 P-R 曲线是通过将阈值从高到低移动而生成的。 实线:A model, 虚线:B model
上面说的阈值从高到低原因:阈值高,精确率高,阈值低,召回率高
1.6 ROC
Q1: 什么是ROC曲线?
ROC curve (TPR 纵轴,FPR 横轴,TP(真正率)和 FP(假正率),设一个阈值)
ROC(Receiver Operating Characteristic Curve)曲线。 ROC 曲线 是基于混淆矩阵得出的。
TPR = recall = 灵敏度 = P(X=1 | Y=1), FPR = 特异度 = P(X=0 | Y=0)
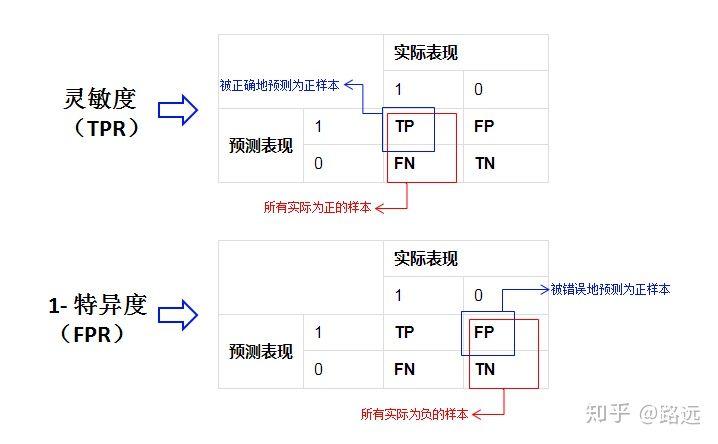
注意: ROC 曲线是 FPR 越小,TPR 越大 最好. (也就是曲线 x 轴越小,y轴越大 最好)
ROC曲线的适用场景更多,被广泛用于排序、推荐、广告等领域
Q2: 如何绘制ROC曲线?
与前面的P-R曲线类似, ROC曲线是通过不断移动分类器的“截断点”来生成曲线上的一组关键点的, 截断点指的是区分正负预测结果的阈值:
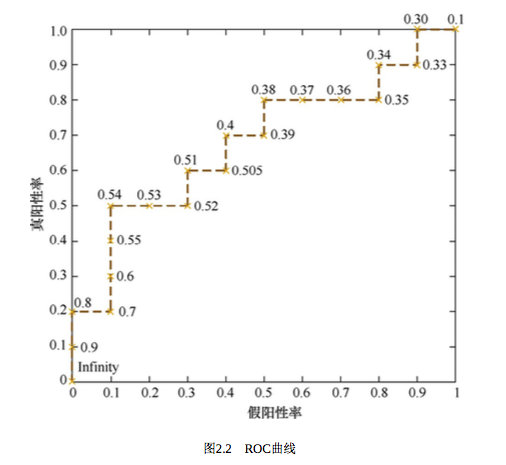
(1). 还有一种更直观地绘制ROC的方法。根据样本标签统计正负样本数量,假设正样本数量 P,负样本数量 N.
(2). 接下来把横轴刻度间隔设置为 1 / N, 纵轴的刻度间隔设置为 1 / P。
(3). 再根据模型输出的预测概率对样本进行排序(从高到低);依次遍历样本,同时从零点开始绘制ROC曲线,每遇到一个正样本就沿着纵轴方向绘制一个刻度间隔的曲线,每遇到一个负样本就沿横轴方向绘制一个刻度间隔的曲线,直到遍历完所有样本,曲线最终停在(1,1)整个ROC曲线绘制完成。这样就很好理解为什么面积越大,分类性能越好了,想象这个过程即可。
ROC曲线无视样本不平衡
1.7 AUC
AUC = 0.5,跟随机猜测一样, ROC 纵轴 TPR 越大, 横轴 FPR 越小 模型越好
0.5 - 0.7:效果较低,但用于预测股票已经很不错了
0.7 - 0.85:效果一般
0.85 - 0.95:效果很好real world data 经常会面临 class imbalance 问题,即正负样本比例失衡。
根据计算公式可以推知,在 testing set 出现
imbalance 时 ROC曲线 能保持不变,而 PR 则会出现大变化。
2 Regression Metric
2.1 MSE
MSE (Mean Squared Error)称为均方误差,,又被称为 L2范数损失:
2.2 RMSE
均方根误差(Root Mean Squared Error, RMSE),定义如下:
2.3 MAE
缺点:因为它使用的是平均误差,而平均误差对异常点较敏感,如果回归器对某个点的回归值很不合理,那么它的误差则比较大,从而会对RMSE的值有较大影响,即平均值是非鲁棒的。
2.4 MAPE
全称是 Mean Absolute Percentage Error(WikiPedia), 也叫 mean absolute percentage deviation (MAPD),在统计领域是一个预测准确性的衡量指标。
3. 余弦相似度 vs 欧式距离
余弦相似度 : 坐标系中两个向量,来计算两向量之间的夹角, 值域 [-1, 1]
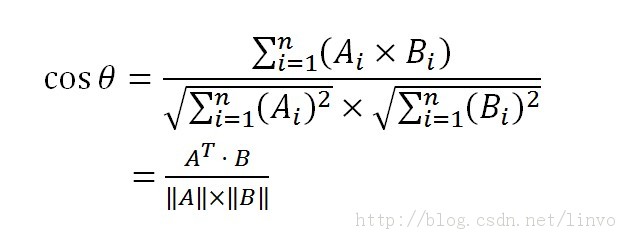
余弦距离 : 值域 [0, 1]
欧式距离 : 坐标系中两个点,来计算两点之间的距离;
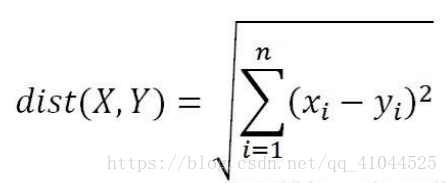
假设二维空间两个点:

然后归一化为单位向量:

余弦相似度就是:

欧式距离就是:

化简后就是:

很明显,是一个单调函数(图像类似于单位元的第一象限部分),也就意味着,两者在归一化为单位向量的时候计算相似度结果完全一样。只不过余弦相似度是值越大月相似,欧式距离是值越小越相似。
知识点 : 余弦相似度、余弦距离、欧式距离、距离的定义
4. A/B 测试的陷阱
Q1:在对模型进行充分的离线评估之后,为什么还要进行在线A/B测试?
(1)离线评估无法完全消除模型过拟合的影响。
(2)离线评估无法完全还原线上的工程环境。线上的工程环境包括数据延迟、数据缺失、标签缺失等情况。
(3)线上系统的某些商业指标在离线评估中无法计算。 离线模型评估的指标包括准确率,召回率和ROC曲线等。 而线上评估可以全面了解该推荐算法带来的用户点击率、留存时长、PV访问量等的变化。这些都要由A/B测试来进行全面的评估。
Q2:如何进行线上AB测试?
答:进行AB测试的主要手段是进行用户分桶,即将用户分成实验组和对照组,对实验组的用户施以新模型,对对照组的用户施以旧模型。
分桶的过程中,要注意 样本的独立性 和 采样方式的无偏性.
5. 模型评估方法
Q1: 在模型评估过程中,有哪些主要的验证方法,它们的优缺点是什么?
- Holdout检验
- 交叉检验 (k-fold交叉验证, 在实际实验中,经常取10。)
- 自助法
Q2:在自助法的采样过程中,对n个样本进行n次自助抽样,当n趋于无穷大时,最终有多少数据从未被选择过?
根据重要极限,当样本量很大时,大约有 0.368 的样本从未被选择过,可做为验证集。
6. 超参数调优
- 网格搜索
- 随机搜索
- 贝叶斯优化 (未研究)
7. 过拟合/欠拟合
防止 overfiting 的 8 条
1). get more data
2). Data augmentation
3). Regularization(权值衰减). (L1 拉普拉斯先验, L2 高斯先验)
4). Dropout (类似 RF bagging 作用,最后以投票的方式降低过拟合;)
5). Choosing Right Network Structure
6). Early stopping
7). Model Ensumble
8). Batch Normalization
8. 其他评价指标
- 计算速度:模型训练和预测需要的时间;
- 鲁棒性:处理缺失值和异常值的能力;
- 可拓展性:处理大数据集的能力;
- 可解释性:模型预测标准的可理解性,比如决策树产生的规则就很容易理解,而神经网络被称为黑盒子的原因就是它的大量参数并不好理解。
Reference
- 精确率、召回率、F1 值、ROC、AUC 各自的优缺点是什么?
- 机器学习之类别不平衡问题 (2) —— ROC和PR曲线
- sklearn中 F1-micro 与 F1-macro 区别和计算原理
- Bias-Variance Tradeoff
- 程序员大本营-百面
- CSDN 模型评估
- 简单聊聊模型的性能评估标准
- 从0开始机器学习-为什么要做A/B Test
- 百面模型评估
Checking if Disqus is accessible...