data-warehouse review 1 - 数仓认识
漫谈系列:
| No. | Question | Flag |
|---|---|---|
| 1. | good - 漫谈大牛带你从0到1构建数据仓库实战 | |
| 2. | good - 数据模型设计(推荐收藏) | |
| 3. | 数据仓库(二), 数据仓库(一) | |
| 4. | Hadoop的元数据治理–Apache Atlas | |
| 5. | 1. 漫画:什么是数据仓库? | |
| 6. | 2. 传统数仓和大数据数仓的区别是什么? ✔️ | |
| 7. | 4. 数仓那点事:从入门到佛系 | |
| 8. | 5. 从8个角度5分钟搞定数据仓库 | |
| 9. | 6. 滴滴数据仓库指标体系建设实践 | |
| 11. | 9. 手把手教你如何搭建一个数据仓库 | |
| 12. | 10. 基于spark快速构建数仓项目(文末Q&A) | |
| 13. | 11. 数据湖VS数据仓库之争?阿里提出大数据架构新概念:湖仓一体! | |
| 14. | 12. 数据仓库(离线+实时)大厂优秀案例汇总(建议收藏) | |
| 15. | Good - Hive 拉链表实践 |
1. 漫谈系列 | 数仓第一篇NO.1 『基础架构』
2. 漫谈系列 | 数仓第二篇NO.2 『数据模型』
3. 漫谈系列 | 数仓第三篇NO.3 『数据ETL』
4. 漫谈系列 | 数仓第四篇NO.4 『数据应用』
5. 漫谈系列 | 数仓第五篇NO.5 『调度系统』
6. 漫谈系列 | 数仓第六篇NO.6 『数据治理』
7. 漫谈系列 | 漫谈数仓第一篇NO.7 『面试真经』
1. DWH, Concept
| OLTP (on-line transaction processing) | OLAP(On-Line Analytical Processing) |
|---|---|
| 数据在系统中产生 | 本身不产生数据,基础数据来源于产生系统 |
| 基于交易的处理系统 | 基于查询的分析系统 |
| 牵扯的数据量很小 | 牵扯的数据量庞大 (复杂查询经常使用全表扫描等) |
| 对响应时间要求非常高 | 响应时间与具体查询有很大关系 |
| 用户数量大,为操作用户 | 用户数量少,主要有技术人员与业务人员 |
| 各种操作主要基于索引进行 | 业务问题不固定,数据库的各种操作不能完全基于索引进行 |
DW 4 大特征: Subject Oriented、Integrate、Non-Volatil、Time Variant .
数仓分层
- STG Stage (不做任何加工, 禁止重复进入)
- ODS(Operational Data Store)不做处理,存放原始数据 (该层在stage上仅数据格式到标准格式转换)
- DWD(Data Warehouse Summary 明细数据层)进行简单数据清洗,降维
- DWS(Data Warehouse Summary 服务数据层)进行轻度汇总(做宽表)
- ADS(Application Data Summary 数据应用层)为报表提供数据
1.1 DWH basic
data warehouse 逻辑分层架构:
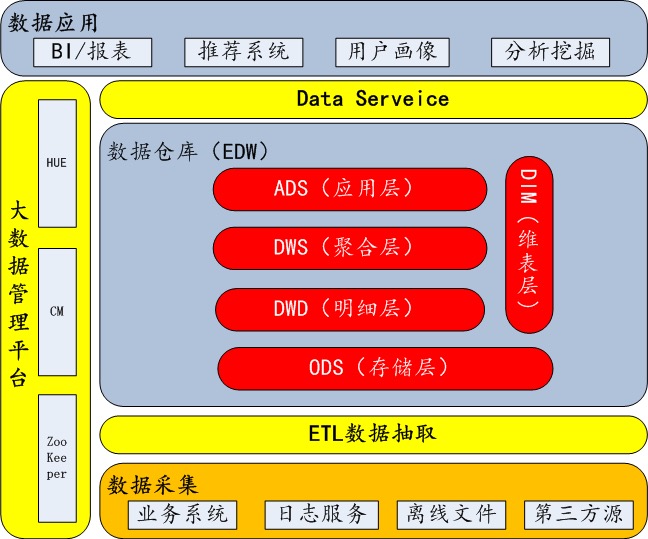
1.2 data modeling
| Title_Kimball | 深入浅出数据模型(推荐收藏) |
|---|---|
| 流程 | 架构是自下向上,即从数据集市(主题划分)–>数据仓库–> 数据抽取,是以需求为导向的,一般使用星型模型 |
| 事实表和维表 | 架构强调模型由事实表和维表组成,注重事实表与维表的设计 |
| 数据集市 | 数据仓库架构中,数据集市是一个逻辑概念,只是多维数据仓库中的主题域划分,并没有自己的物理存储,也可以说是虚拟的数据集市。是数据仓库的一个访问层,是按主题域组织的数据集合,用于支持部门级的决策。 |
data modeling 的几种方式:
| No. | 数据建模方式 | type |
|---|---|---|
| 1. | ER模型 | 三范式 |
2. |
维度建模 |
1. 星型模型 2. 雪花模型 3. 星座模型 |
| 1. | 事实表 | 事实表生于业务过程,存储业务活动或事件提炼出来的性能度量。从最低的粒度级别来看,事实表行对应一个度量事件 (1)事务事实表 (2)周期快照事实表 (3)累积快照事实表 |
| 2. | 维度表 | (1)退化维度(DegenerateDimension) (2)缓慢变化维(Slowly Changing Dimensions) 维度的属性并不是始终不变的,这种随时间发生变化的维度我们一般称之为缓慢变化维(SCD) |
1.3 data ETL
| No. | Title | desc |
|---|---|---|
| 1. | 数仓建模工具哪一个好? | powerDesigner 勉强推一个吧 |
| 2. | DWS 轻度聚合及(汇总 == group by) | 是按照 Topic 划分的 |
| 3. | DWD join 成宽表 by ODS | 事实表基本都在 DWD 层. |
| 4. | App 层也是在 Hive 中么? | 尽量不要 |
| 5. | 数据仓库的数据质量如何保障? | 需要从源头管控,业务系统进行细致的字段的校验 |
| 6. | 如何保证你的计算的指标结果准确性? | 1. 有测试人员 2. 我们公司有做小样本数据集的抽取开发 |
| 7. | 数据存储格式 | orc / Parquet |
| 8. | 数据压缩方式 | snappy / LZO |
| 9. | 数据存储格式 + 压缩 | 服务器的磁盘空间可以变为原来的 1/3 |
| 10. | beeline 客户端支持远程连接 | |
| 11. | lzo 支持切分么? | snappy 不支持切分, 给lzo文件建立索引后,则支持切分 |
create_time, update_time, 使用拉链表解决历史数据变更的问题
1 | # 设置输出数据格式压缩成为LZO |
1.4 Tool-App
| No. | Tool |
|---|---|
| 1. | Apache_Druid Druid是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,用于解决如何在大规模数据集下进行快速的、交互式的查询和分析。 |
| 2. | Apache Kylin™ 一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。 |
| 3. | Clickhouse是一个用于在线分析处理(OLAP)的列式数据库管理系统(DBMS) |
| 4. | ADB(AnalyticDB_for_MySQL) 分析型数据库MySQL版(AnalyticDB for MySQL),是阿里巴巴自主研发的海量数据实时高并发在线分析(Realtime OLAP)云计算服务,使得您可以在毫秒级针对千亿级数据进行即时的多维分析透视和业务探索。 |
| 5. | 花未全开*月未圆 1.1 presto 是Facebook开源的,完全基于内存的并⾏计算(MPP),分布式SQL交互式查询引擎 1.2 数据治理: 在ETL过程中开发人员会对数据清洗这其实就是治理的一部分 1.3 元数据是记录数仓中模型的定义、各层级的映射关系、监控数仓的数据状态及 ETL 的任务运行状态 1.4 DW-DM层是采用Kimball的总线式的数据仓库架构,针对部门(比如财务部门)或者某一主题(比如商户、用户),通过维度建模(推荐星型模型),构建一致性维度,原子粒度的数据是DW层,按照实体或者主题经过一定的汇总,建设数据集市模型。数据集市可以为OLAP提供服务。 |
Ad-hoc 查询或报告(即席查询或报告)是 商业智能的一个次要的话题,它还经常与OLAP、数据仓库相并论.
2. SQL
(1). 主键 / FOREIGN KEY
1 | 身份证号、手机 这些看上去可以唯一的字段,均不可用作主键。 |
(2). INDEX
1 | 可以对一张表创建多个索引。索引的优点是提高了查询效率 |
(3). SQL查询
1 | 3.1 基础查询 |
3. Hive
1.1 3NF vs Dim modeling
1 | 3NF: |
Input -> Mappers -> Sort,Shuffle -> Reducers -> Output
Hive 系统架构
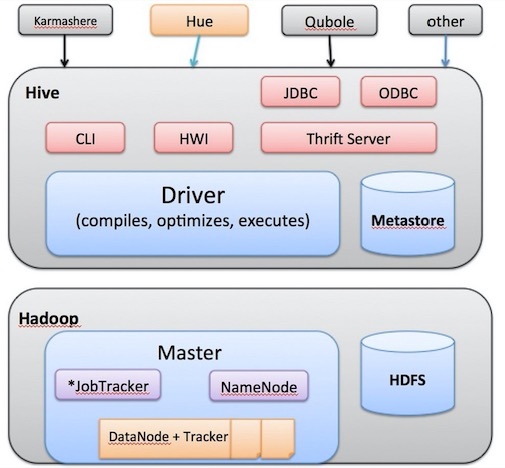
1. Hive 原理
1 | 1. 用户提交查询等任务给Driver。 |
2. hadoop处理数据的过程,有几个显著的特征
1 | 1.不怕数据多,就怕数据倾斜。 |
4. Sqoop 问题
1 | function import_data_hdfs() { |
数据湖 vs 数据仓库 vs 数据中台
| No. | Title | desc |
|---|---|---|
| 0. | https://delta.io/ | |
| 1. | 数据湖如何为企业带来9%的高增长?可否取代数据仓库? | ✔️ |
| 2. | 数据湖(Data Lake)-剑指下一代数据仓库 | ✔️ |
| 3. | IOTA架构、数据湖、Metric Platform,终于有人讲清楚了! | |
| 4. | Delta Lake 数据湖的诞生与案例实践 |
至此,我们也可以对比一下数据湖、数据仓库、数据中台,简明扼要概括为:
1)数据湖: 无为而治,目标AI
2)数据仓库:分而治之,目标BI
3)数据中台:一统天下,目标组织架构
Data Lake是一个存储库,可以存储大量结构化,半结构化和非结构化数据。它是以原生格式存储每种类型数据的地方,对帐户大小或文件没有固定限制。它提供高数据量以提高分析性能和本机集成。
Data Lake就像一个大型容器,与真正的湖泊和河流非常相似。就像在湖中你有多个支流进来一样,数据湖有结构化数据,非结构化数据,机器到机器,实时流动的日志。
数据湖相对于以往的关系型数据库、传统式数据仓库,更多体现的是一种数据存储技术上的融合。数据湖的提出,改变了用户使用数据的方式,同时,数据湖也整合了各种类型数据的分析和存储,用户不必为不同的数据构建不同数据存储库。
但是,现阶段数据湖更多是作为数据仓库的补充,它的用户一般只限于专业数据科学家或分析师。数据湖概念和技术还在不断演化,不同的解决方案供应商也在添加新的特性和功能,包括架构标准化和互操作性、数据治理要求、数据安全性等。
未来,数据湖可能会进一步发展,作为一种云服务随时按需满足对不同数据的分析、处理和存储需求,数据湖的扩展性,可以为用户提供更多的实时分析,基于企业大数据的数据湖正在向支持更多类型的实时智能化服务发展, 将会为企业现有的数据驱动型决策制定模式带来极大改变。
即席查询(Ad Hoc)用户据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表
dw
| No. | 主题名称 | 主题描述 |
|---|---|---|
| 1. | 客户 (USER) | 当事人, 用户信息, 非常多, 人行征信信息, 个人资产信息 |
| 2. | 机构 (ORG) | 线下有哪些团队, 浙江区,团队长,客户经理, 有 600+ 个. 只有维度表 |
3. |
产品 (PRD) |
签协议 产生 产品, 业务流程, 只有维度表 产品维度表: 产品编号(分好几级), 产品名称, dim_code, dim_name, 上架, 下架 京东金条, code, 展示给财务 |
| 4. | 渠道 (CHL) | |
| 5. | 事件 (EVT) | 1. 业借 / 注册&认证 2. 授信 3. 支用 4. 放款 5. 支付 6. 还款 |
| 6. | 协议 (AGR) | 合约 |
| 7. | 营销 (CAMP) | 营销之后的,商务经理和渠道,谈下来之后, 后端 渠道, 资产, 账务 |
| 8. | 财务 (RISK) | |
| 9. | 风险 (FINANCE) | 风险部 |
Reference
- HDFS基本架构、原理、与应用场景、实践(附ppt)
- Hive存储格式对比
- very good - igDataGuide/面试-all
- Apache Druid 简介
- 操作系统之堆和栈的区别
- 漫谈数据仓库之拉链表(原理、设计以及在Hive中的实现)
- 2020大数据/数仓/数开面试题真题总结(附答案)
Checking if Disqus is accessible...