Hive Introduce 1
- 初步了解 Hadoop 生态圈
- 初步了解 Hive 架构图
1. Hive Introduce
1.1 Hive Preface
Hadoop
- Hadoop 生态系统 是 处理大数据集而产生的解决方案。
- Hadoop 实现计算模型 MapReduce, 可将计算任务分割成多个处理单元,这个计算模型下面是一个 HDFS。
Hive
- Hive 提供了一个 Hive查询语言 HiveQL, 查询转换为 MapReduce job
- Hive 适合做数据仓库,可离线维护海量数据,可对数据进行挖掘, 形成报告等
- Hadoop、HDFS 设计本身限制了 Hive 所能胜任的工作, Hive 不支持记录级别的更新、插入 或者 删除 操作。
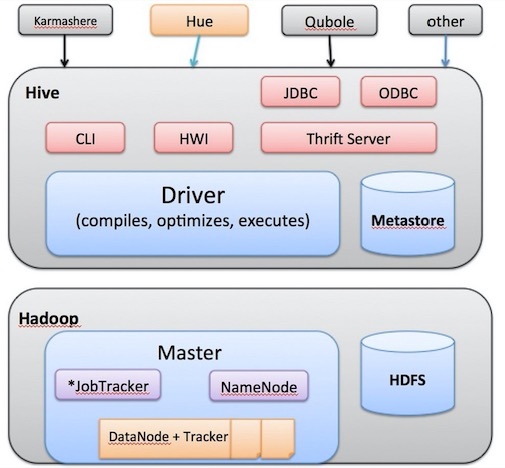
Hive 运行架构
- 使用 HQL 作为查询接口;
- 使用 MapReduce 作为执行层;
- 使用 HDFS 作为存储层;
1.2 Hadoop / Mapreduce
Input -> Mappers -> Sort,Shuffle -> Reducers -> Output
1.3 Hive 系统架构
2. Hive 架构组件分析
本章重点 :
- 初步了解 Hive 的工作流
- 初步了解 hive 的工作组件
2.1 元数据存储Metastore
-
Hive的数据由两部分组成:数据文件 和 元数据
1
2
3元数据存储,Derby只能用于一个Hive连接,一般存储在MySQL。
元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
2.2 驱动 (Driver)
- 编译器
- 优化器
- 执行器
用户通过下面的接口提交Hive给Driver,由Driver进行HQL语句解析,此时从Metastore中获取表的信息,先生成逻辑计划,再生成物理计划,再由Executor生成Job交给Hadoop运行,然后由Driver将结果返回给用户。
编译器(Hive的核心):1,语义解析器(ParseDriver),将查询字符串转换成解析树表达式;2,语法解析器(SemanticAnalyzer),将解析树转换成基于语句块的内部查询表达式;3,逻辑计划生成器(Logical Plan Generator),将内部查询表达式转换为逻辑计划,这些计划由逻辑操作树组成,操作符是Hive的最小处理单元,每个操作符处理代表一道HDFS操作或者是MR作业;4,查询计划生成器(QueryPlan Generator),将逻辑计划转化成物理计划(MR Job)。
优化器:优化器是一个演化组件,当前它的规则是:列修剪,谓词下压。
执行器:编译器将操作树切分成一个Job链(DAG),执行器会顺序执行其中所有的Job;如果Task链不存在依赖关系,可以采用并发执行的方式进行Job的执行。
2.3 接口
CLI、HWI、ThriftServer
-
CLI:为命令行工具,默认服务。bin/hive或bin/hive–service cli;
-
HWI:为Web接口,可以用过浏览器访问Hive,默认端口9999,启动方式为bin/hive --service hwi;
-
ThriftServer:通过Thrift对外提供服务,默认端口是10000,启动方式为bin/hive --service hiveserver;
** 连接hive-metastore(如mysql)的三种方式 **
- 单用户模式。此模式连到数据库Derby,一般用于Unit Test。
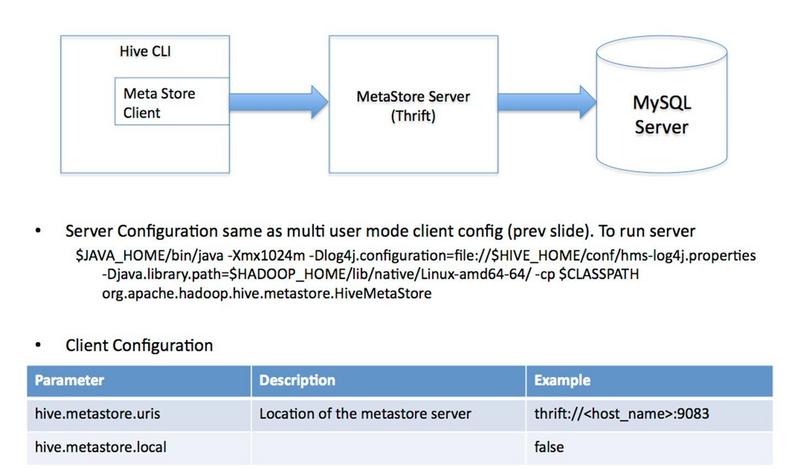
- 多用户模式。通过网络连接到一个数据库中,是最经常使用到的模式。
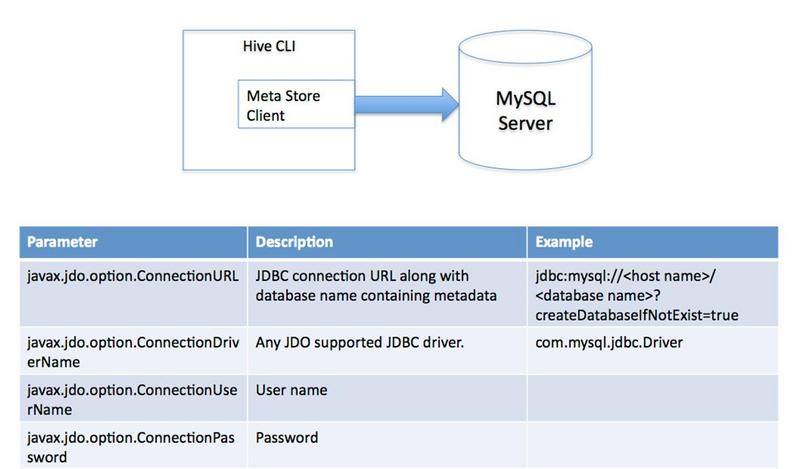
- 远程服务器模式。用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。
2.4 其他服务
bin/hive --service -help
-
metastore (bin/hive --service metastore)
-
hiveserver2(bin/hive --service hiveserver2)
HiveServer2
-
HiveServer2是HieServer改进版本,它提供给新的ThriftAPI来处理JDBC或者ODBC客户端,进行Kerberos身份验证,多个客户端并发
-
HS2还提供了新的CLI:BeeLine,是Hive 0.11引入的新的交互式CLI,基于SQLLine,可以作为Hive JDBC Client 端访问HievServer2,启动一个beeline就是维护了一个session.
Hive下载地址
-
cdh-hive : hive0.13.1-cdh5.3.6 jar 包 (没用)
-
apache-hive : Apache-Hive
Hive-Beeline 试验成功
1 | 下载 apache-hive-0.13.1-bin, apache-hadoop2.5,配置 HADOOP_HOME, 启动 |
Hive table
table 中的一个 Partition 对应表下的一个子目录
每一个 Bucket 对应一个文件;
Hive的默认数据仓库目录是/user/hive/warehouse
在hive-site.xml中由hive.metastore.warehouse.dir项定义;
reference article
参考 : CSDN - Hive Server 2 调研,安装和部署
参考 : 极豆技术博客 - Beeline连接hiveserver2异常
参考 : Hive学习之HiveServer2 JDBC客户端
参考 : HiveServer2 Clients beeline
参考 : Beeline连接hiveserver2异常
参考 : Hive学习之HiveServer2服务端配置与启动
other tmp
1 | ## Chap 7 HiveQL 视图 ## |
Checking if Disqus is accessible...