Probabilistic Graphical Model
Probabilistic Graphical Model
对于一个实际问题,目标: 能够挖掘隐含在数据中的知识。 怎样才能使用概率图模型挖掘这些隐藏知识呢?
用观测结点表示观测到的数据,用隐含结点表示潜在的知识,用边来描述知识与数据的相互关系,获一概率分布。
1. Probabilistic Graphical Model
概率图中的**节点**分为:
- 隐含节点
- 观测节点
概率图中的**边** 分为:
- 有向边
- 无向边
常见的概率图模型 : Native Bayes、最大熵、隐马尔科夫模型、CRF、LDA 等.
PGM 联合概率:
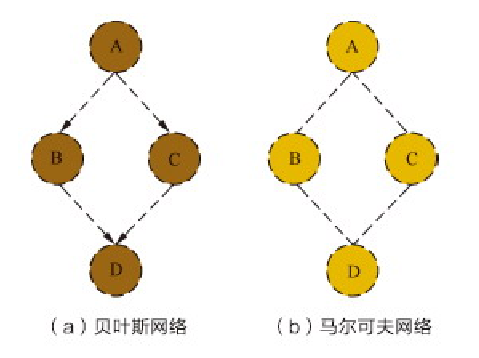
概率图模型最为“精彩”的部分就是能够用简洁清晰的图示形式表达概率生成的关系:
在给定A的条件下B和C是条件独立的,基于条件概率的定义可得:
P(C∣A,B)=P(BA)P(B,C∣A)=P(B∣A)P(B∣A)P(C∣A)=P(C∣A)
同理,在给定B和C的条件下A和D是条件独立的,可得:
P(D∣A,B,C)=P(A∣B,C)P(A,D∣B,C)=P(A∣B,C)P(A∣B,C)P(D∣B,C)=P(D∣B,C)
结合上面的两个表达式可得联合概率:
P(A,B,C,D)=P(A)P(B∣A)P(C∣A,B)P(D∣A,B,C)=P(A)P(B∣A)P(C∣A)P(D∣B,C)(6.3)
2. PGM Expression
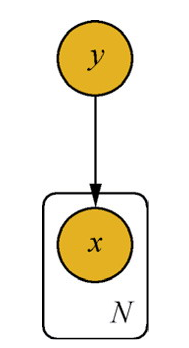
解释朴素贝叶斯模型的原理,并给出概率图模型表示:
通过预测指定样本属于特定类别的概率
y=max_y_iP(y_i∣x)
可以写成:
P(y_i∣x)=P(x)P(x∣y_i)P(y_i)
其中 x=(x_1,x_2,……,x_n), 为样本对应的特征向量, P(x) 为样本的先验概率。
3. Generative vs Discriminative
3.1 Generative
generative approach 由数据学习到联合概率分布 P(X,Y),然后求出条件概率分布 P(Y∣X) 作为预测的模型:
P(Y∣X)=P(X)P(X,Y)
典型的生成式模型包括: Native Bayes、HMM、Bayes Net
3.2 Discriminative
discriminative approach 由数据直接学到决策函数 f(X) 或条件概率分布 P(Y∣X) 作为预测的模型:
f(X),P(Y∣X)
判别式模型关心的是对于给定的输入 X, 应该预测什么样的输出 Y, 判别模型就是判别数据输出量的模型。
典型的判别式模型包括: LR、NN、SVM、CRF、CART
3.3 generative vs discriminative
| vs |
generative approach |
discriminative approach |
| 定义 |
由数据学习联合概率分布P(X,Y) 然后,
求出在X情况下,P(Y)作为预测的模型 |
决策函数f(x)或条件概率分布P(X)作为预测模型 |
| 特点 |
1. 可还原出P(X,Y);
2. 学习收敛速度更快;
3. 存在隐变量时仍可用 |
1. 直接面对预测,准确率更高些;
2. 便于数据抽象,特征定义使用; |
| 模型 |
native bayes、hidden markov |
Logistic Regression、SVM、Gradient Boosting、CRF… |
| Note |
给定输入 X 产生输出 Y 的生成关系 |
对给定的输入 X,应预测什么样的输出 Y |
Reference
Checking if Disqus is accessible...