Information Entropy
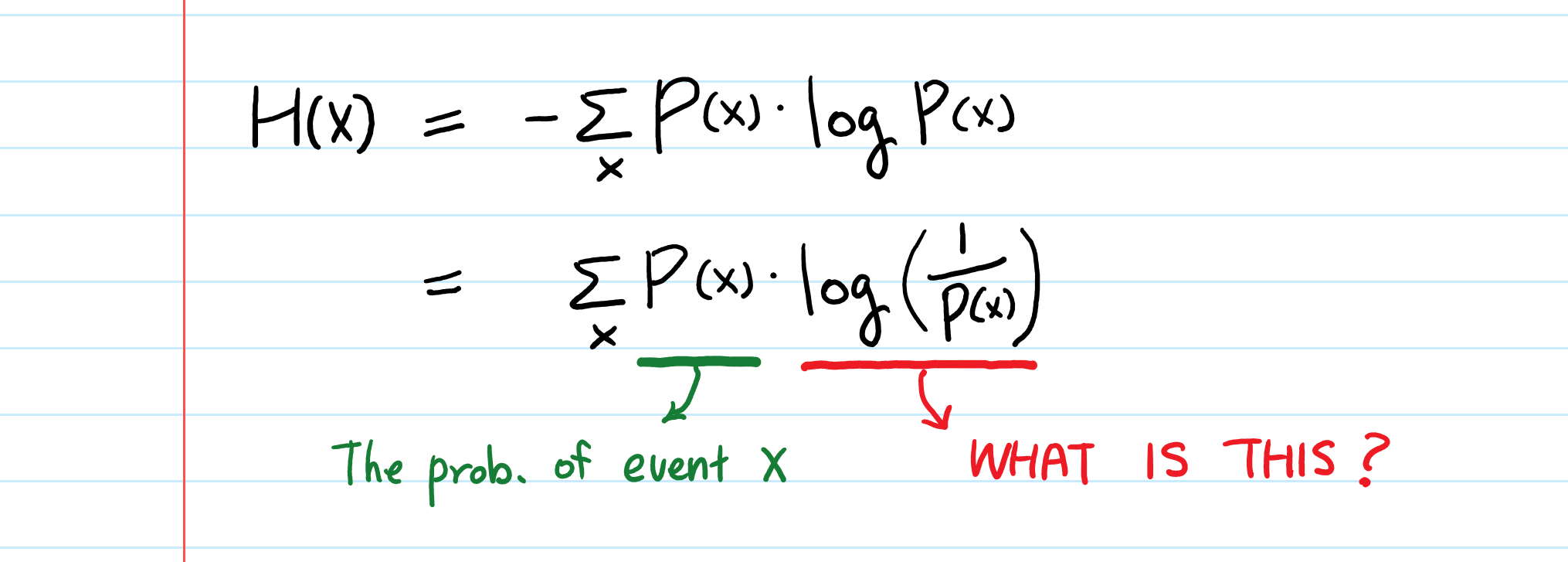
1. Infomation Entropy
2014 年举行了世界杯足球赛,大家都很关心谁会是冠军。假如我错过了看世界杯,赛后我问一个知道比赛结果的观众“哪只球队是冠军”?他不愿意直接告诉我,而让我猜,并且我每猜一次,他要收我一元钱才肯告诉我是否猜对了,那么我要掏多少钱才能知道谁是冠军呢?我可以把球队编上号,从 1 到 32,然后提问:“冠军在 1~16 号中吗?”假如他告诉我猜对了,我会接着提问:“冠军在 1~8 号中吗?”假如他告诉我猜错了,我自然知道冠军在 9~16 号中。这样我只需要 5 次,就能知道哪只球队是冠军。所以,谁是世界杯冠军这条消息的信息量只值 5 块钱。
其中 分别是这 32 支球队夺冠的概率。香农把它称为信息熵(Entropy),一般用符号 表示,单位比特。很容易计算出,当 32 支球队夺冠概率相同时,对应的信息熵等于 5 比特。
1.1 信息熵的定义
对于任意一个离散型随机变量 ,它的熵 定义为:
其中,约定 。 可以写为 。
变量的不确定性越大,熵也就越大,要把它搞清楚,所需信息量也就越大。
信息熵的物理含义是对一个信息系统不确定性的度量,和热力学中熵有相似之处,后者就是一个系统无序的度量。
从另一角度讲也是对一种 不确定性的度量。
1.2 信息熵的例子
设一次随机事件(用随机变量表示)它可能会有 共 m 个不同的结果,每个结果出现的概率分别为 ,那么 的不确定度,即信息Entropy为:
将一个立方体A抛向空中,记落地时着地的面为 , 的取值为{1,2,3,4,5,6}
四面体抛入空中 :
球体抛入空中 :
此时表示不确定程度为0,也就是着地时向下的面是确定的。
1.3 最大熵
“最大熵”这个名词听起来很深奥,但是它的原理很简单,我们每天都在用。说白了,就是要保留全部的不确定性,将风险降到最小。
最大熵原理指出,对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小。因为这时概率分布的信息熵最大,所以人们把这种模型称作“最大熵模型”。我们常说的,不要把所有的鸡蛋放在一个篮子里,其实就是最大熵原理的一个朴素的说法,因为当我们遇到不确定时,就要保留各种可能性。
2. Conditional Entropy
自古以来,信息和消除不确定性是相联系的。在英语里,信息和情报是同一个词(Infomation),而我们知道情报的作用就是排除不确定性。 (二战时期,斯大林无兵可派到欧洲战场,但在远东有60万大军,情报得知 Japan 不会北上)
一个事物内部会存有随机性,也就是不确定性,假定为 , 而从外部消除这个不确定性的唯一的方法是引入信息 , 而引入的信息量取决于这个不确定性的大小, 当 时,这些信息可以消除一部分不确定性.
新的不确定性:
几乎所有的自然语言处理、信息与信号处理的应用都是一个消除不确定性的过程。
自然语言的统计模型,其中的一元模型就是通过某个词本身的概率分布,来消除不确定性;二元及更高阶的语言模型则还使用了上下文的信息,那就能准确预测一个句子中当前的词汇了。在数学上可以严格地证明为什么这些“相关的”信息也能够消除不确定性。为此,需要引入条件熵(Conditional Entropy)的概念。
2.1 条件熵的定义
假定 和 是两个随机变量, 是我们需要了解的。假定我们现在知道了 的随机分布
,那么也就知道了 的熵:
那么它的不确定性就是这么大。现在假定我们还知道 的一些情况,包括它和 一起出现的概率,在数学上称为联合概率分布(Joint Probability),以及在 取不同值的前提下 的概率分布,在数学上称为条件概率分布(Conditional Probability)。定义在 条件下 的条件熵为:
\begin{align}H(X \mid Y) &= \sum\_{y\in Y}P(y)H(X \mid Y=y) \\\&=\sum\_{y\in Y}P(y)\big[-\sum\_{x\in X}P(x\mid y)\log P(x\mid y)\big]\\\&=-\sum\_{x\in X,y \in Y}P(x,y)\log P(x\mid y)\end{align}
可以证明 ,也就是说,多了 的信息之后,关于 的不确定性下降了!在统计语言模型中,如果把 看成是前一个字,那么在数学上就证明了二元模型的不确定性小于一元模型。同理,可以定义有两个条件的条件熵:
还可以证明 。也就说,三元模型应该比二元的好。
2.2 一个有意思的问题
思考一下,上述式子中的等号什么时候成立?等号成立说明增加了信息,不确定性却没有降低,这可能吗?
答案是肯定的,如果我们获取的信息与要研究的事物毫无关系,等号就成立。那么如何判断事物之间是否存在关系,或者说我们应该如何去度量两个事物之间的关联性呢?这自然而然就引出了互信息(Mutual Infomation)的概念。
3. Mutual Infomation
获取的信息和要研究的事物“有关系”时,这些信息才能帮助我们消除不确定性。当然“有关系”这种说法太模糊,太不科学,最好能够量化地度量“相关性”。为此,香农在信息论中提出了一个互信息(Mutual Infomation)的概念作为两个随机事件“相关性”的量化度量。
假定有两个随机事件 和 ,它们之间的互信息定义如下:
可以证明,互信息 就是随机事件 的不确定性(熵 与在知道随机事件
条件下 的不确定性(条件熵 )之间的差异,即:
所谓两个事件相关性的量化度量,就是在了解了其中一个 的前提下,对消除另一个 不确定性所提供的信息量。互信息是一个取值在 0 到 之间的函数,当 和 完全相关时,它的取值是 1;当二者完全无关时,它的取值是 0。
4. Relative Entropy
相对熵也用来衡量相关性,但和变量的互信息不同,它用来衡量两个取值为正数的函数的相似性。它的定义如下:
大家不必关心公式本身,只需记住下面三条结论就好:
(1). 对于两个完全相同的函数,它们的相对熵等于零。
(2). 相对熵越大,两个函数差异越大;反之,相对熵越小,两个函数差异越小。
(3). 对于概率分布或者概率密度函数,如果取值均大于零,相对熵可以度量两个随机分布的差异性。
第 (3) 条: 可以对标,CrossEntropy 的意义.
注意,相对熵是不对称的,即:
为了让它对称,詹森和香农提出一种新的相对熵的计算方法
相对熵最早用在信号处理上。如两个随机信号,它们相对熵越小,说明这两个信号越接近,否则信号的差异越大。
Reference
- 吴军《数学之美》
- 宗成庆《统计自然语言处理》
- 信息的度量和作用
Checking if Disqus is accessible...