Sequence Models (week3) - Attention mechanism
能够将序列模型应用到自然语言问题、音频应用 等,包括文字合成、语音识别和音乐合成。
1. Basic models
假设需要翻译下面这句话
“简将要在 9 月访问中国”
我们希望得到的结果是
"Jane is visiting China in September”
在这个例子中输入的数量是 10 个中文汉字,输出为 6 个单词, 与 数量不一致,就需要用到 Sequence to sequence model RNN
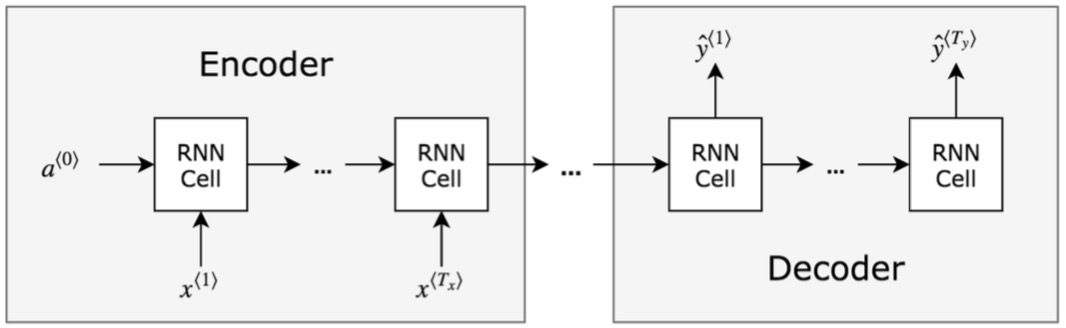
类似的例子还有用机器为下面这张图片生成描述

只需要将 encoder 部分用一个 CNN模型 替换就可以了,比如 AlexNet,就可以得到“一只(可爱的)猫躺在楼梯上”
2. Picking the most likely sentence
下面将之前学习的语言模型和机器翻译模型做一个对比, P 为概率
语言模型:
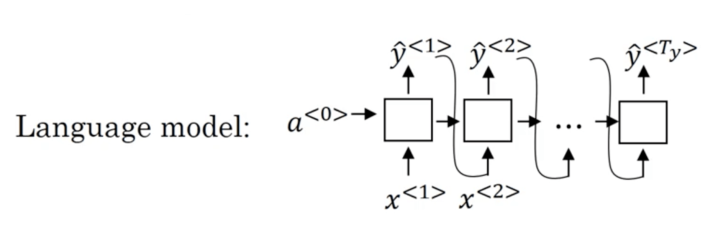
机器翻译模型:

可以看到,机器翻译模型的后半部分其实就是语言模型,Andrew 将其称之为 “条件语言模型”,在语言模型之前有一 个条件也就是被翻译的句子:
但是我们知道翻译是有很多种方式的,同一句话可以翻译成很多不同的句子,那么我们如何判断哪一个句子是最好的呢?
还是翻译上面那句话,有如下几种翻译结果:
- “Jane is visiting China in September.”
- “Jane is going to visit China in September.”
- “In September, Jane will visit China”
- “Jane’s Chinese friend welcomed her in September.”
- …
与语言模型不同的是,机器模型在输出部分不再使用 softmax 随机分布的形式进行取样,因为很容易得到一个不准确的翻译,取而代之的是使用
Beam Search做最优化的选择。这个方法会在后下一小节介绍,在此之前先介绍一下**贪婪搜索(Greedy Search)**及其弊端,这样才能更好地了解Beam Search的优点。
2.1 Greedy Search
得到最好的翻译结果,转换成数学公式就是:
那么 Greedy Search 是什么呢?
通俗解释就是每次输出的那个都必须是最好的。还是以翻译那句话为例。
现在假设通过贪婪搜索已经确定最好的翻译的前两个单词是:"Jane is "
然后因为 “going” 这个单词出现频率较高和其它原因,所以根据贪婪算法得出此时第三个单词的最好结果是 “going”。
所以据贪婪算法最后的翻译结果可能是下图中的第二个句子,但第一句可能会更好(不服气的话,我们就假设第一句更好).
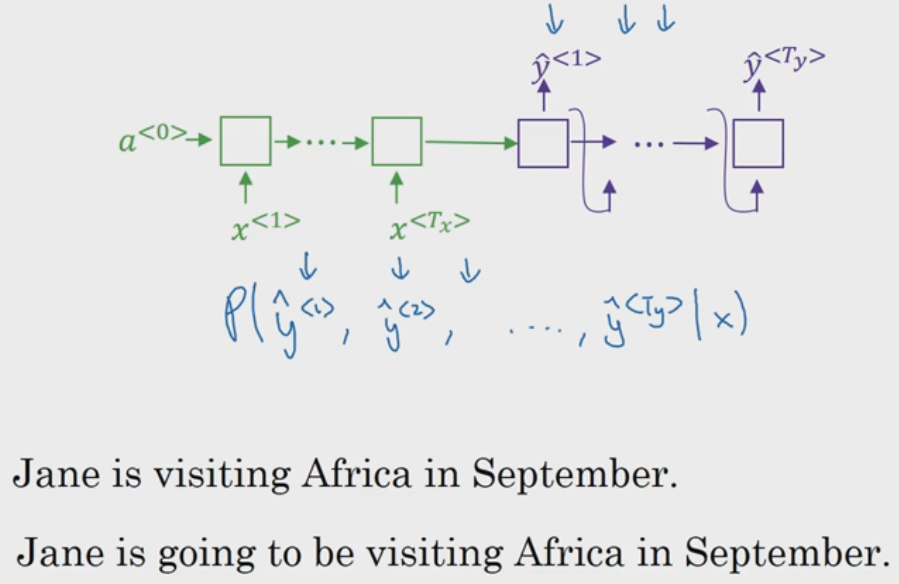
所以贪婪搜索的缺点是局部最优并不代表全局最优,就好像五黑,一队都是很牛逼的,但是各个都太优秀,就显得没那么优秀了,而另一队虽然说不是每个都是最优秀,但是凑在一起就是能 carry 全场。
更形象的理解可能就是 Greedy Search 更加短视,看的不长远,而且也更加耗时。假设字典中共有 10000 个单词,如果使用 Greedy Search,那么可能的组合有 1000010 种,所以还是挺恐怖的 2333~~
3. Beam Search
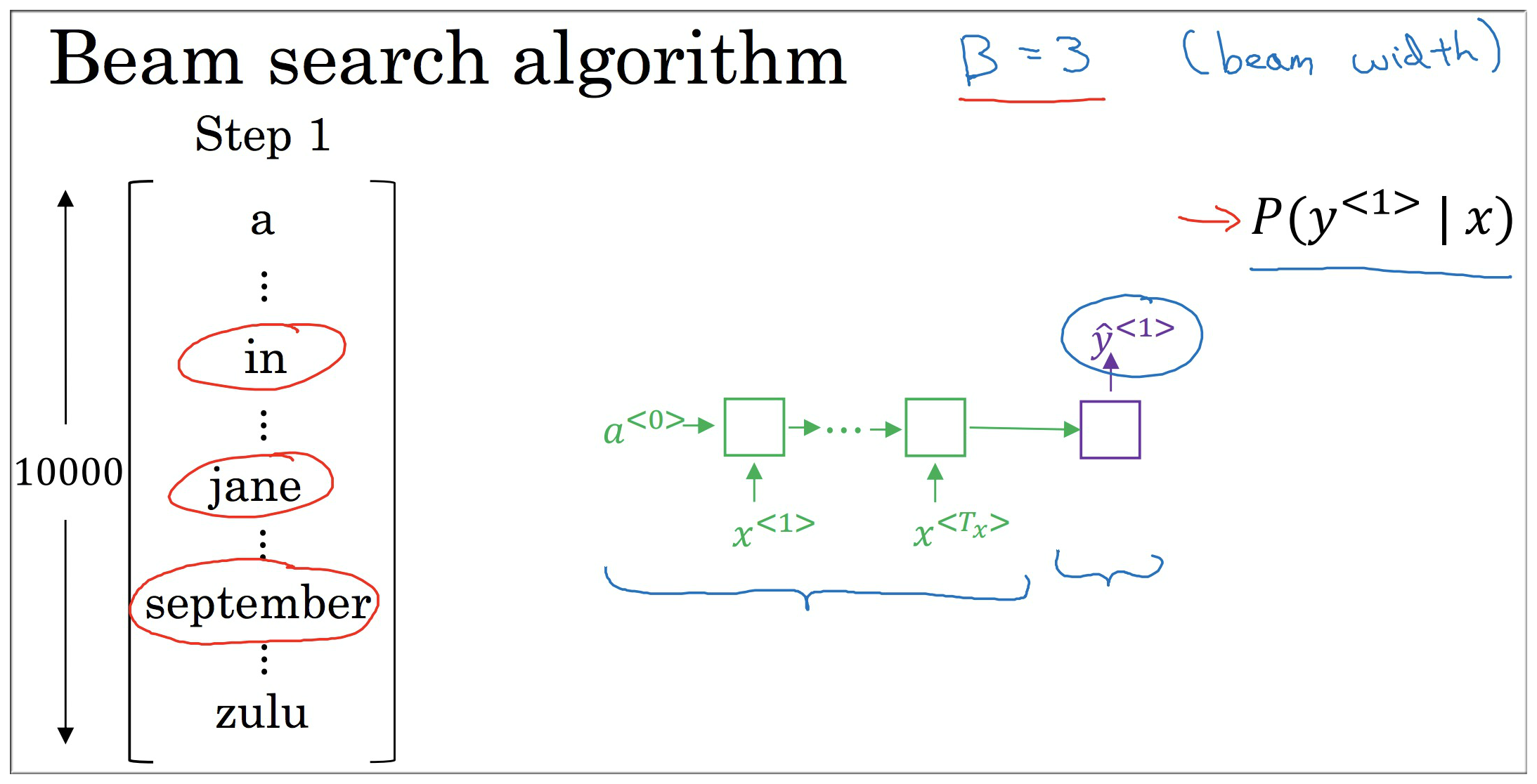
Beam Search 是 greedy search 的加强版本,首先要预设一个值 beam width,这里等于 3 (如果等于 1 就是 greedy search)。然后在每一步保存最佳的 3 个结果进行下一步的选择,以此直到遇到句子的终结符.
3.1 步骤一
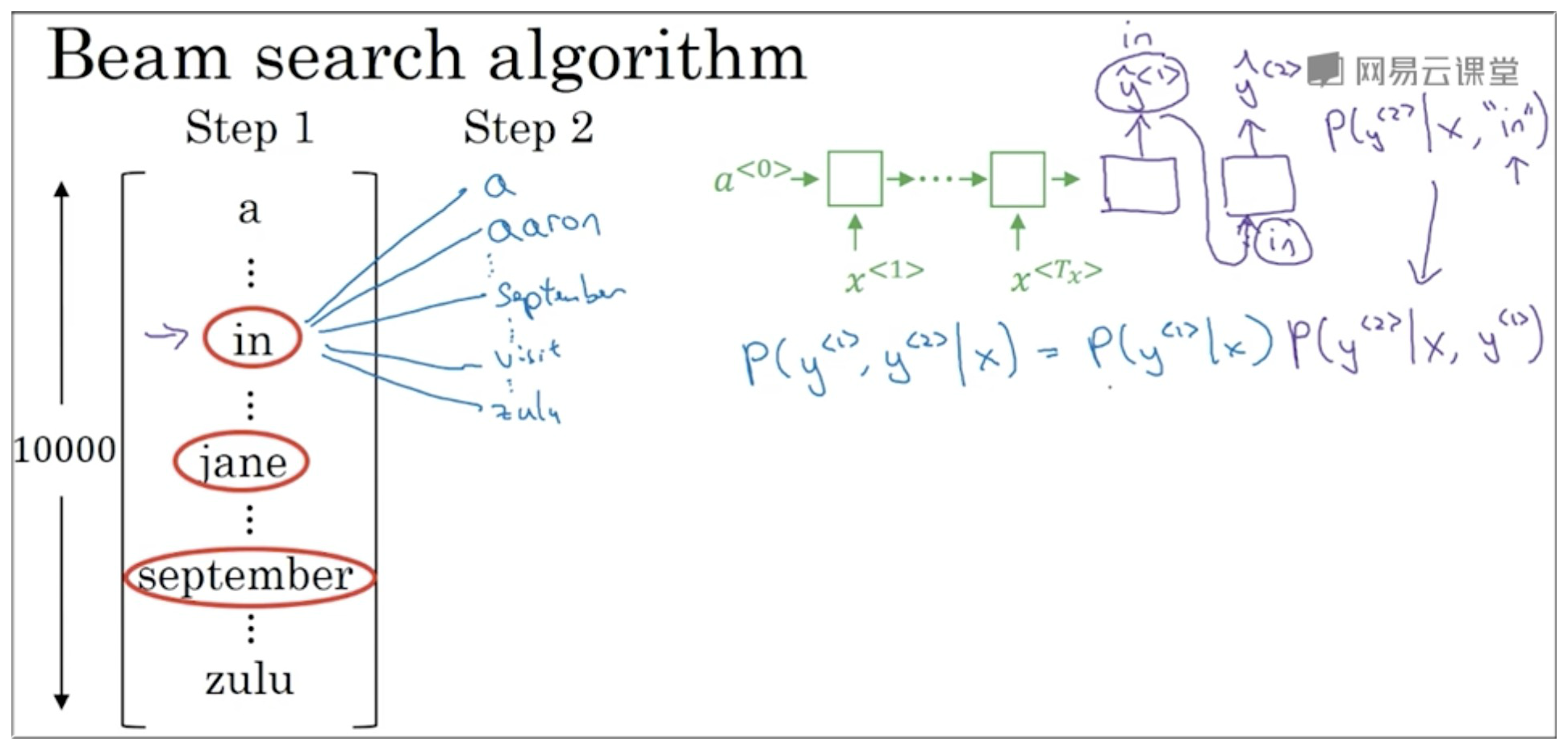
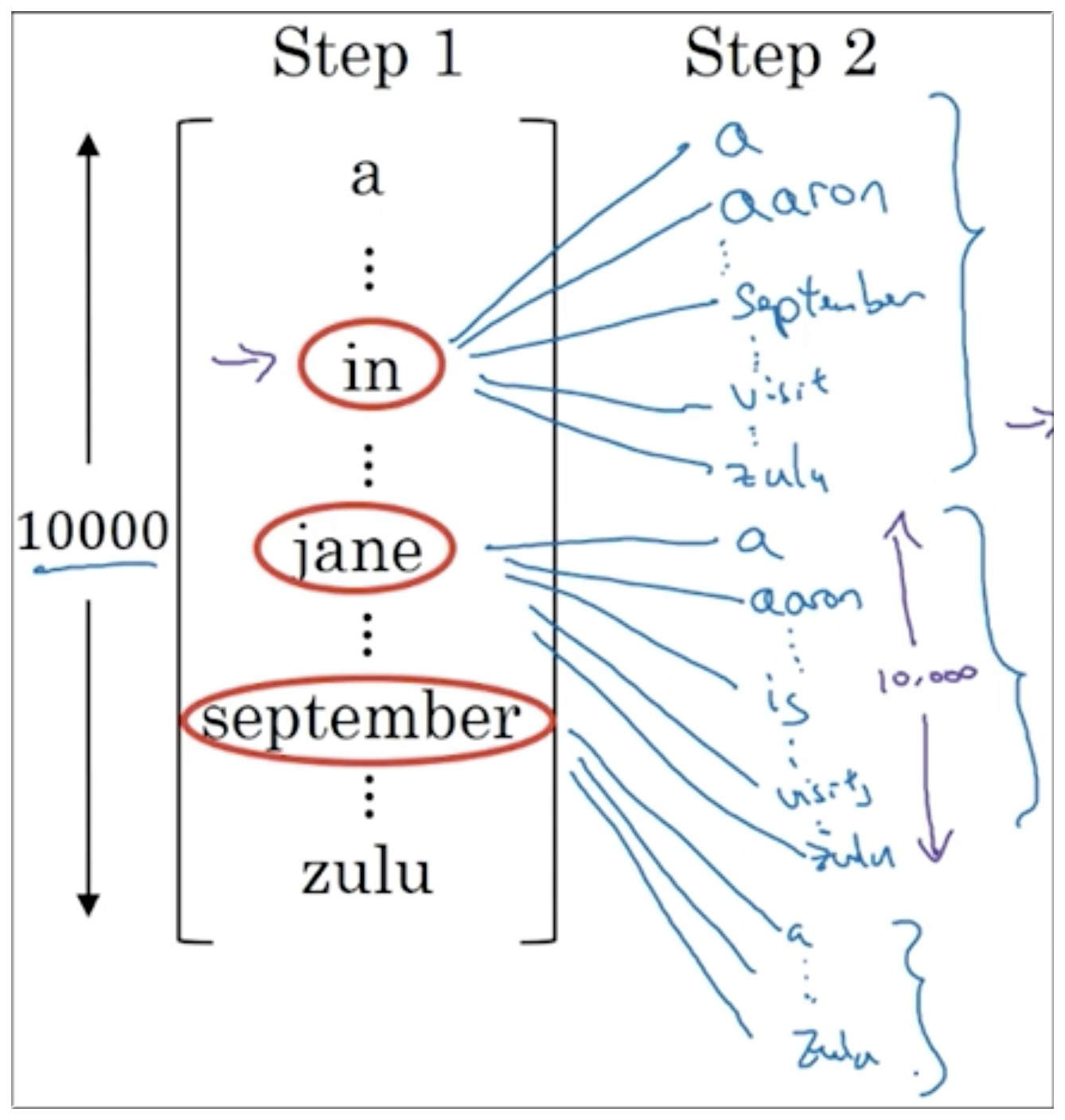
如下图示,因为beam width=3,所以根据输入的需要翻译的句子选出 3 个 最可能的输出值,即选出最大的前3个值。假设分别是"in",“jane”,“september”
3.2 步骤二
以"in"为例进行说明,其他同理.
如下图示,在给定被翻译句子 和确定 = “in” 的条件下,下一个输出值的条件概率是 。此时需要从 10000 种可能中找出条件概率最高的前 3 个.
又由公式 , 我们此时已经得到了给定输入数据,前两个输出值的输出概率比较大的组合了.
另外 2 个单词也做同样的计算
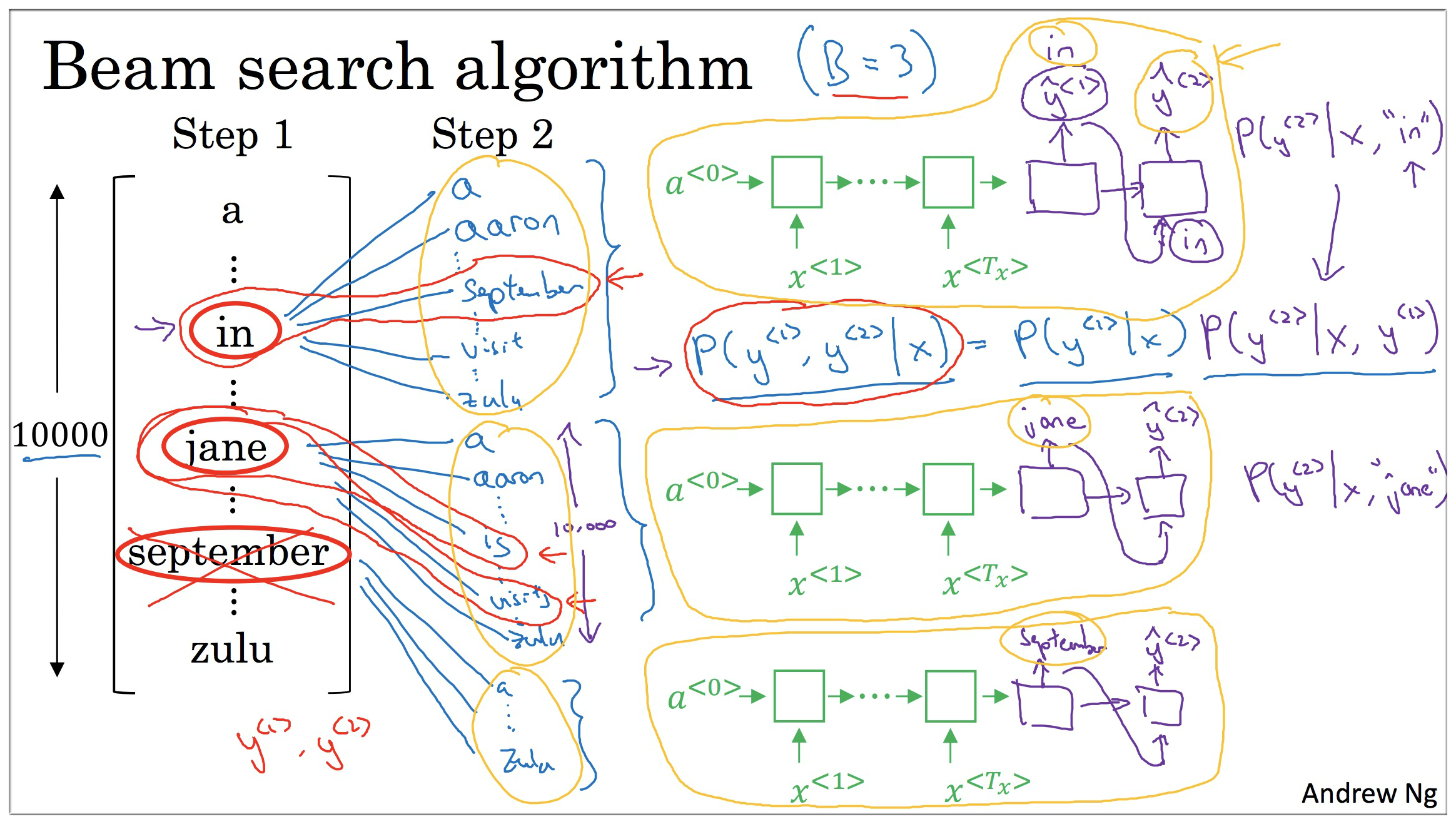
此时我们得到了 9 组 , 此时我们再从这 9组 中选出概率值最高的前 3 个。如下图示,假设是这3个:
- “in september”
- “jane is”
- “jane visits”
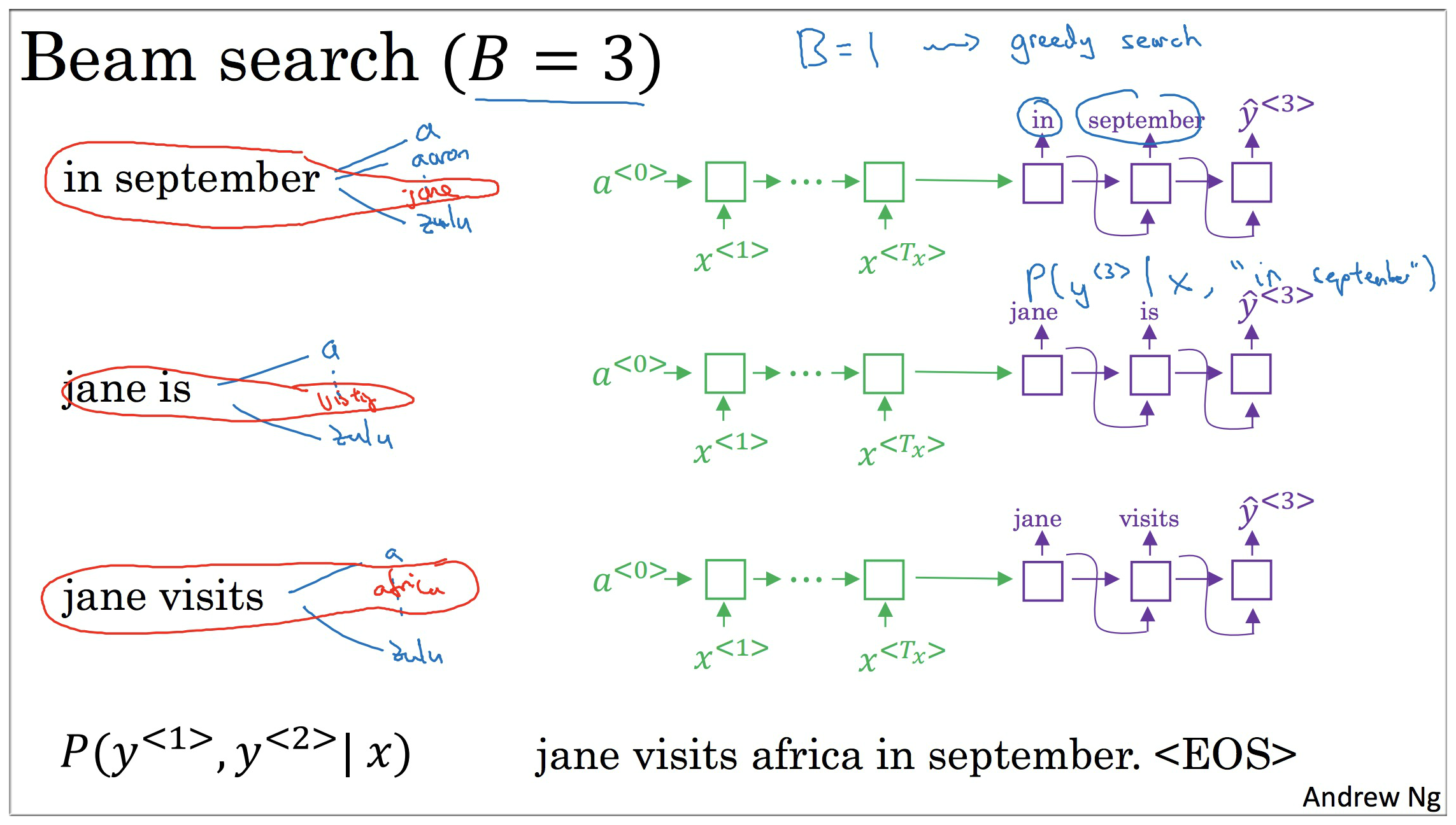
3.3 步骤三
继续步骤2的过程,根据 选出 最大的前3个组合.
后面重复上述步骤得出结果.
3.4 总结
总结一下上面的步骤就是:
- (1). 经过 encoder 以后,decoder 给出最有可能的三个开头词依次为 “in”, “jane”, “september”
- (2). 经过将第一步得到的值输入到第二步中,最有可能的三个翻译为 “in september”, “jane is”, “jane visits”
(这里,september开头的句子由于概率没有其他的可能性大,已经失去了作为开头词资格)
- (3). 继续这个过程…
4. Refinements to beam search
所以要满足 , 也就等同于要满足
但是上面的公式存在一个问题,因为概率都是小于1的,累乘之后会越来越小,可能小到计算机无法精确存储,所以可以将其转变成 log 形式(因为 log 是单调递增的,所以对最终结果不会有影响),其公式如下:
But!!!上述公式仍然存在bug,观察可以知道,概率值都是小于1的,那么log之后都是负数,所以为了使得最后的值最大,那么只要保证翻译的句子越短,那么值就越大,所以如果使用这个公式,那么最后翻译的句子通常都是比较短的句子,这显然不行。
所以我们可以通过归一化的方式来纠正,即保证平均到每个单词都能得到最大值。其公式如下:
通过归一化的确能很好的解决上述问题,但是在实际运用中,会额外添加一个参数 , 其大小介于 0 和 1 之间,公式如下:
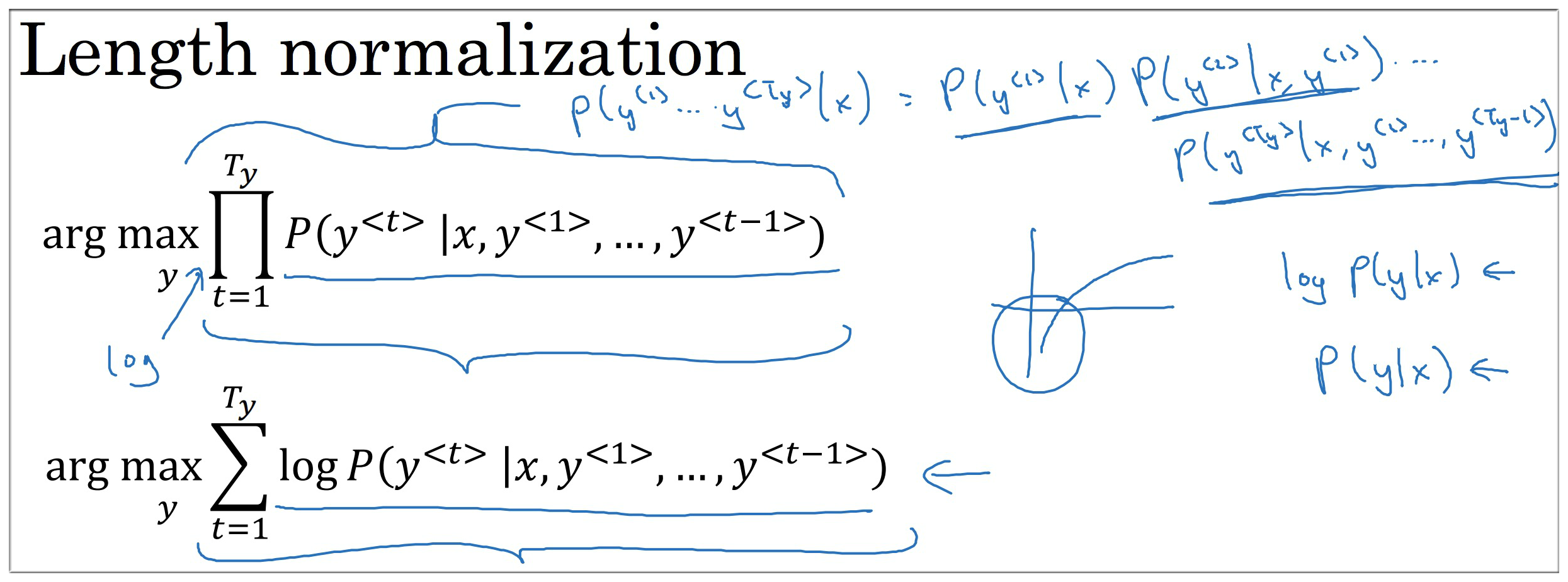
为输出句子中单词的个数, 是一个超参数 (可以设置为 0.7)
== 1. 则代表 完全用句子长度归一化
== 0. 则代表 没有归一化
== 0~1. 则代表 在 句子长度归一化 与 没有归一化 之间的折中程度.beam width = B = 3**10**100 是会有一个明显的增长,但是 B 从 1000 ~ 3000 是并没有一个明显增长的.
5. Error analysis on beam search
仔细想想 beam search,我们会发现其实它是近似搜索,也就是说可能使用这种方法最终得到的结果并不是最好的。当然也有可能是因为使用的 RNN 模型有缺陷导致结果不是最好的。
所以我们如何判断误差是出在哪个地方呢?
还是以翻译这句话为例:“简在9月访问中国”。
- 假设按照人类的习惯翻译成英文是“Jane visits China in September.”,该结果用 y^\* 表示。
- 假设通过算法得出的翻译结果是:“Jane visited China in September.”,该结果用 表示。
要判断误差出在哪,只需要比较 P(y^\*|x) 和 的大小即可.
下面分两种情况讨论:

RNN 实际上是 encode 和 decode 的过程.
两种情况:
(1).
上面的不等式的含义是 beam search 最后选出的结果不如人类,也就是 beam search 并没有选出最好的结果,所以问题出在 beam search
(2).
上面不等式表示 beam search 最后选出的结果要比人类的更好,也就是说 beam search 已经选出了最好的结果,但是模型对各个组合的预测概率值并不符合人类的预期,所以 RNN模型 at fault.
上面已经介绍了误差分析的方式,但时仅凭一次误差分析就判定谁该背锅肯定也不行,所以还需要进行多次误差分析多次。
如下图示已经进行了多次的误差分析,每次分析之后都判定了锅该谁背,最后计算出beam search和模型背锅的比例,根据比例作出相应的调整。
例如:
- 如果 beam search 更高,可以相应调整 beam width.
- 如果模型背锅比例更高,那么可以考虑增加正则化,增加数据等操作.

6. Bleu score (optional)
主要介绍了如何给机器翻译结果打分,因为是选修内容, 所以 balabala…
7. Attention model intuition
之前介绍的 RNN 翻译模型存在一个很明显的问题就是:
机器翻译的翻译过程是首先将所有需要翻译的句子输入到 Encoder 中,之后再通过 Decoder 输出翻译语句.
7.1 Why Attention model
如下图示机器算法将法语翻译成英语的模型.
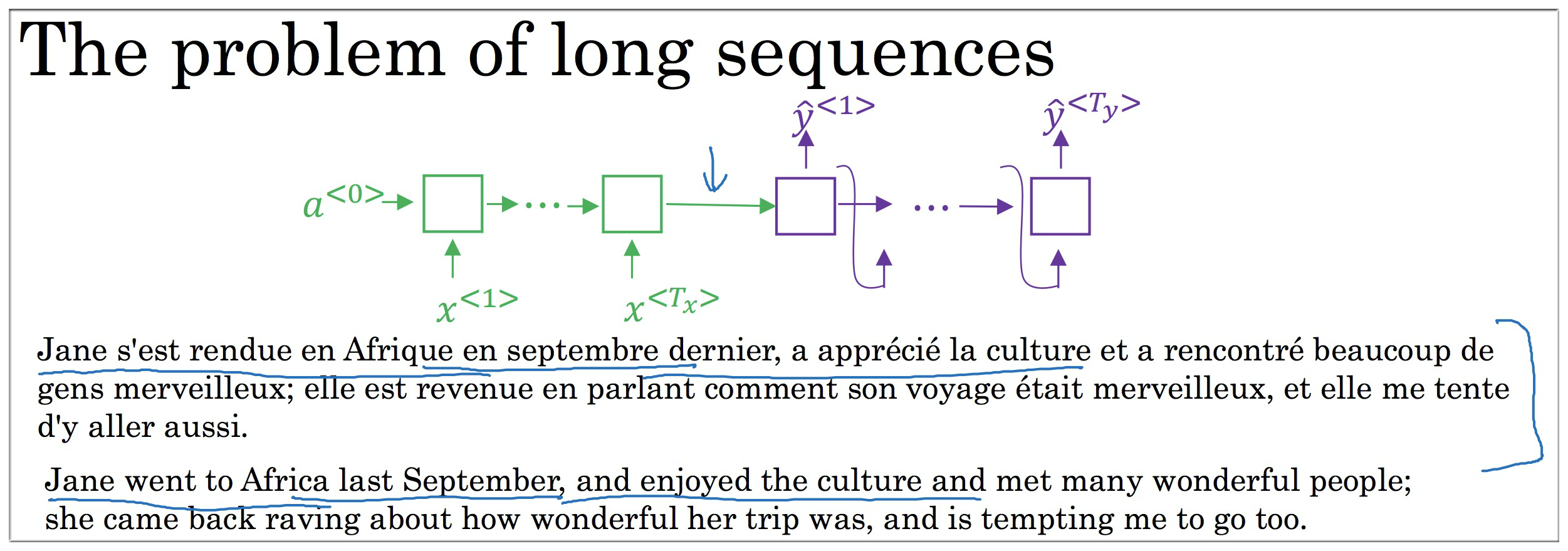
机器翻译与人类的翻译过程不太相同。因为人类翻译一般是逐句翻译,或者是讲一段很长的句子分解开来进行翻译。
所以上述模型的翻译结果的 Bleu评分 与被翻译句子的长短有很大关系,句子较短时,模型可能无法捕捉到关键信息,所以翻译结果不是很高;但是当句子过长时,模型又抓不到重点等原因使得结果也不是很高。
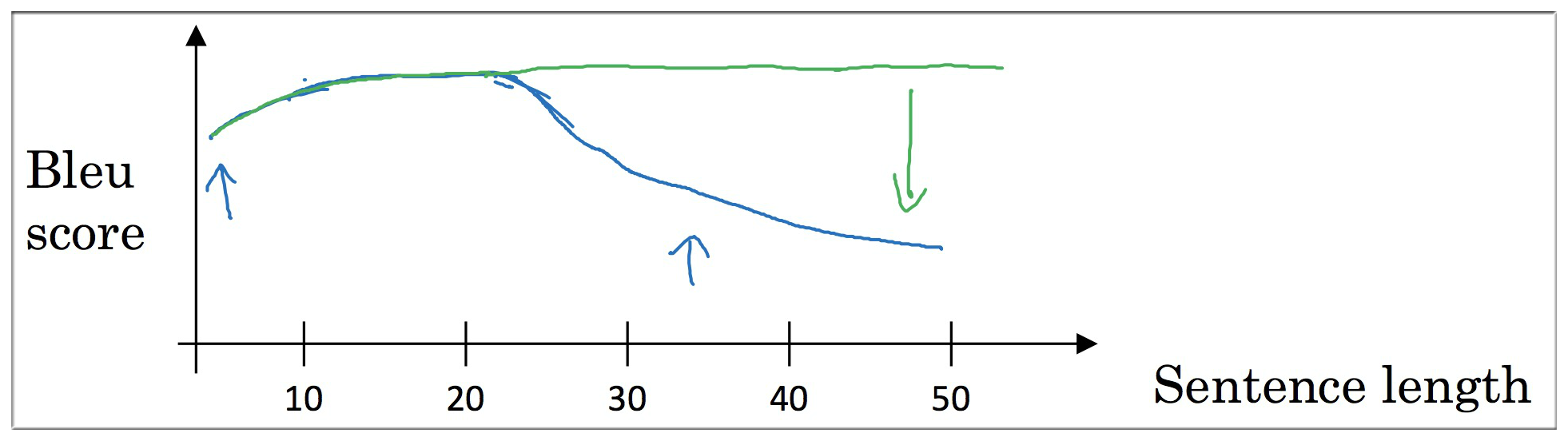
见上图,如果机器能像人一样逐句或者每次将注意力只集中在一小部分进行翻译,那么翻译结果将不受句子长度的影响。下图中的绿色线即为使用了注意力模型后的翻译句子得分。
7.2 Attention model intro
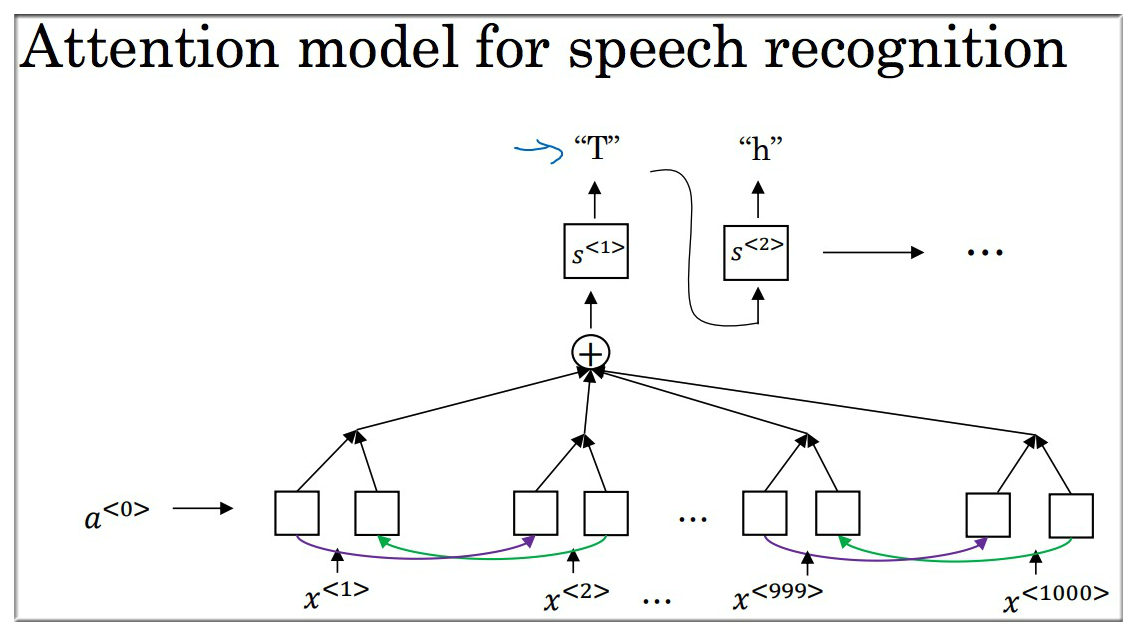
下图展示了普通的翻译模型双向 RNN 结构,该结构可根据输入 直接得到输出 .
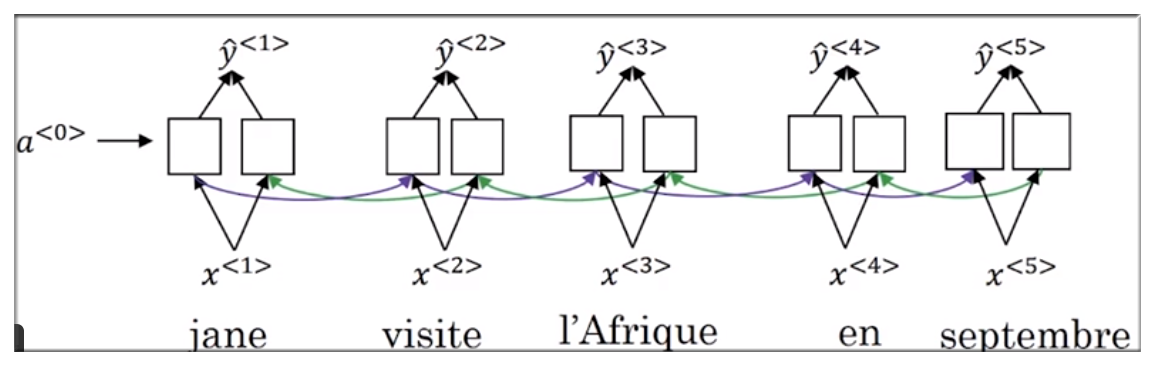
Attention model 在此基础上做进一步处理。
为避免误解,使用另一个符号 来表示节点。
如下图示,根据下面一层的 双向RNN 计算结果可得到节点 与其他节点权重 通过这些权重可以知道该节点与其他节点的相关联程度,从而可以达到将注意力集中到部分区域的效果。
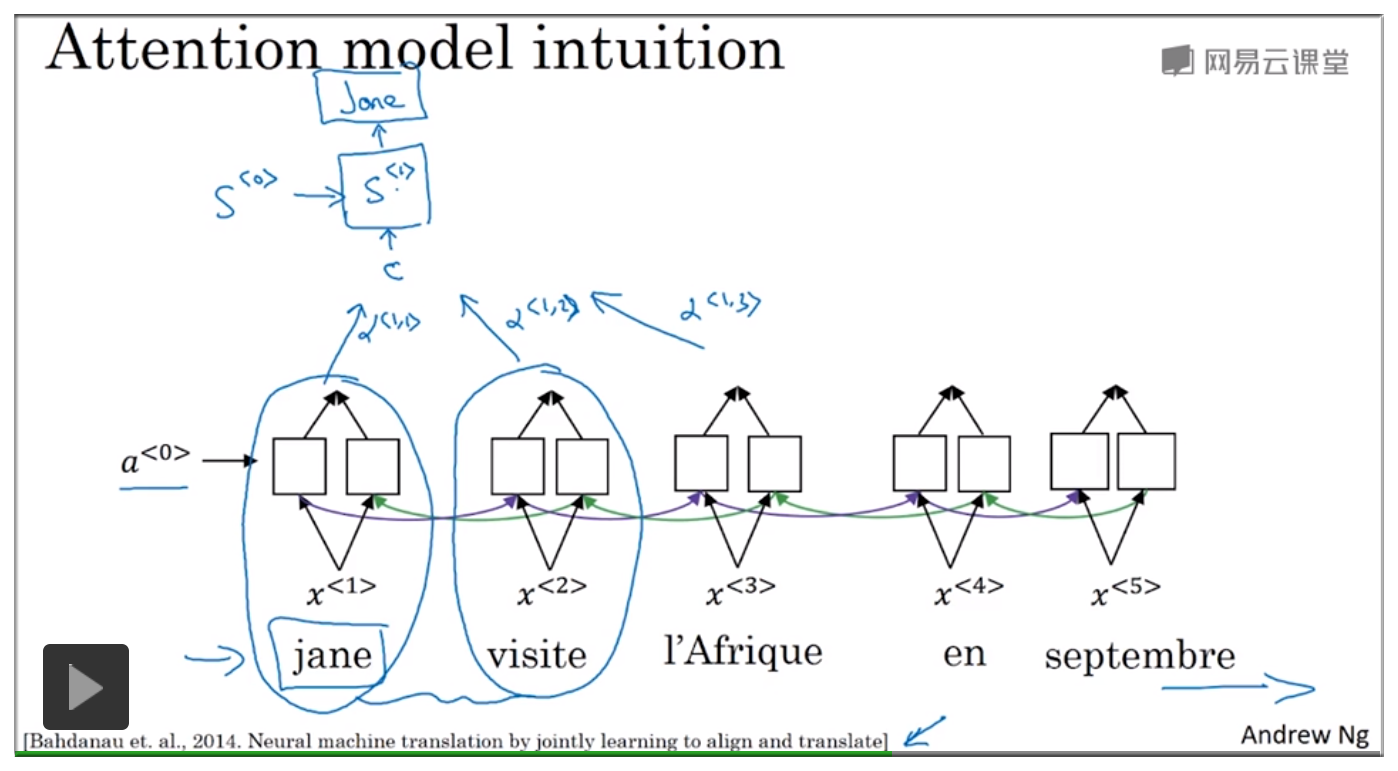
其他节点同理。整个注意力模型结构如下图示
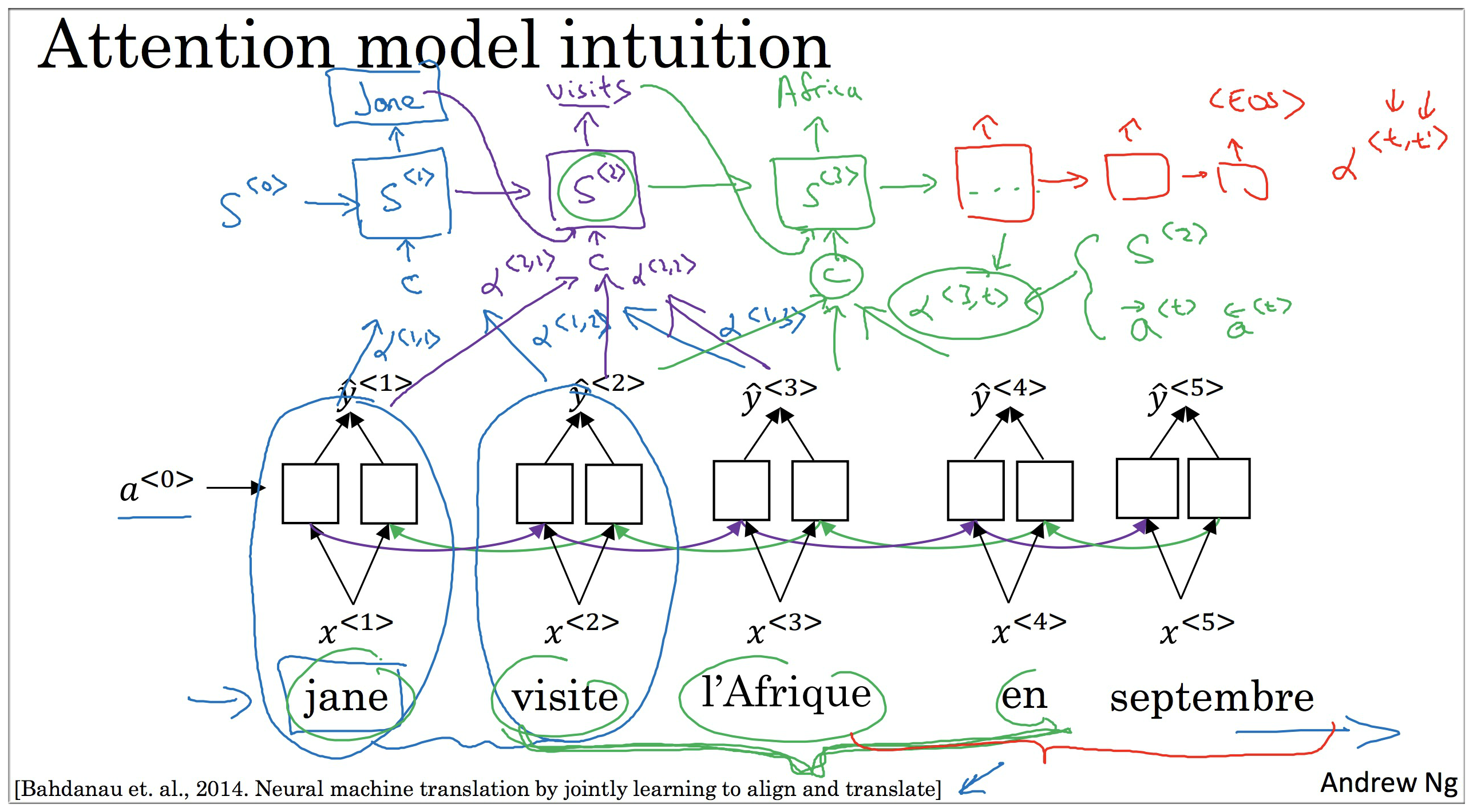
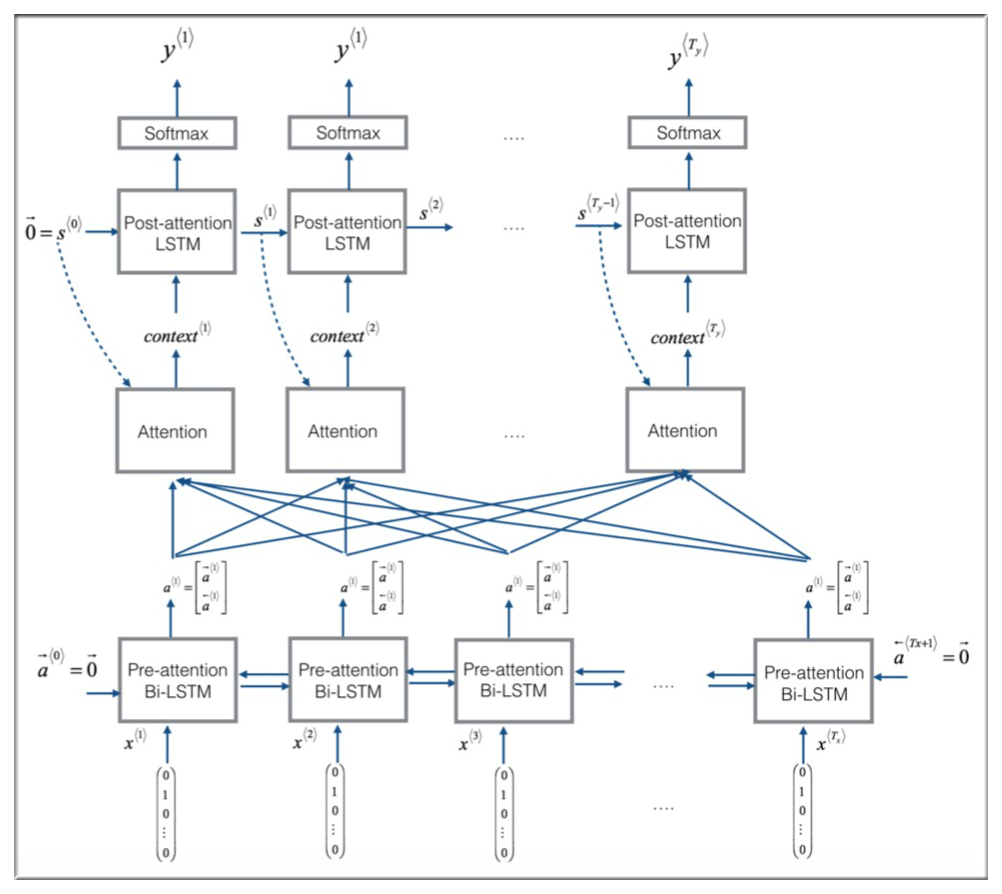
8. Attention model
特别要区分 (字母a) 和 (alpha)。前者表示特征节点,后者表示注意力权重。
8.1 参数介绍
如下图示,注意力模型采用双向 RNN 结构,所以每个节点有两个值,用 表示,为了使公式更简化,令 。其中 表示输入数据的索引。
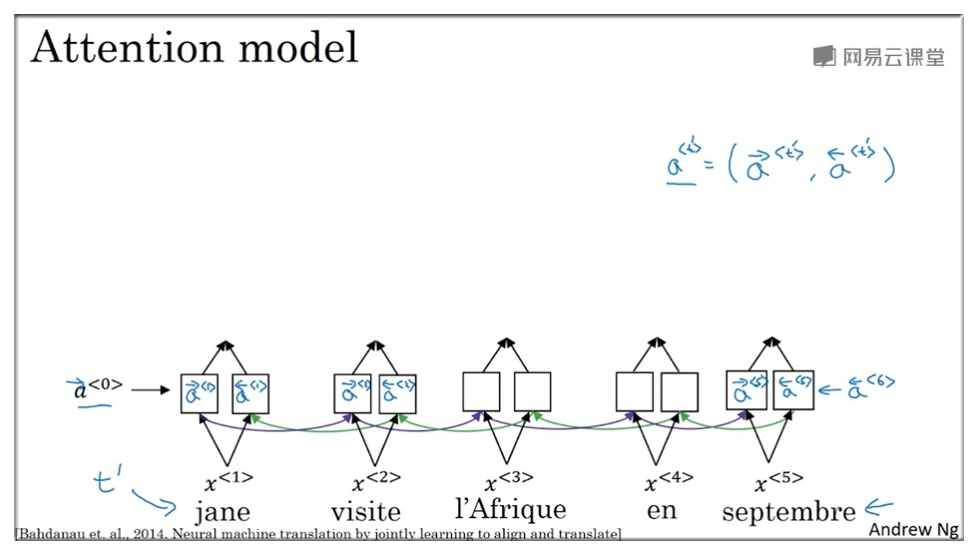
上一节已经介绍了注意力权重 ,以第一个节点为例,它的权重值可以用 表示,且所有权重值满足
所有权重与对应节点的线性之和用 表示(为方便书写,用 表示), 表示 context,即上下文变量.
还是以第一个节点为例,c 的计算公式如下:
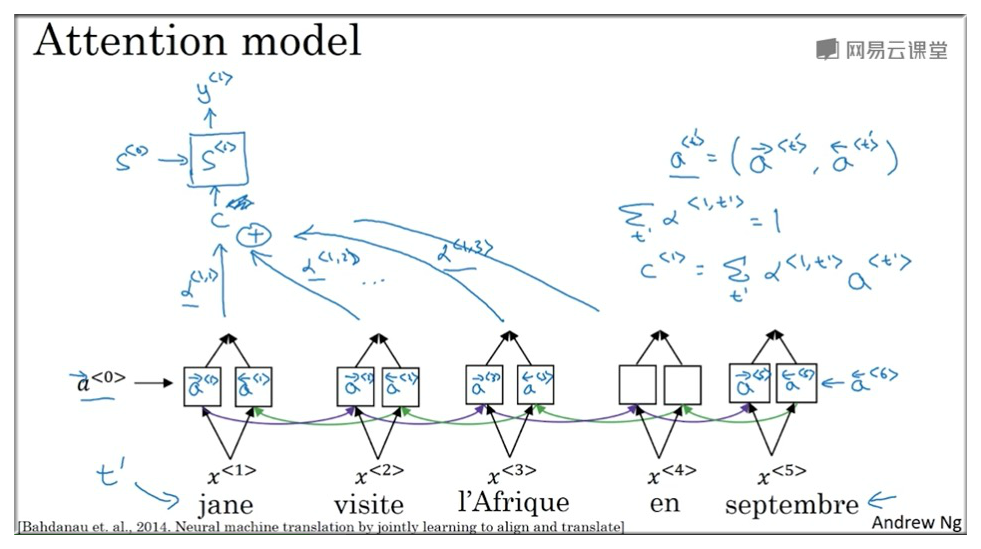
8.2 注意力权值计算公式
上面公式中的 计算图如下:
其中 表示上一个状态的值, 表示第 个特征节点.
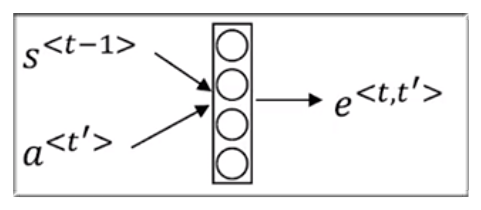
Andrew Ng 并没有详细的介绍上面的网络,只是一笔带过,说反向传播和梯度下降会自动学习,emmm。。那就这样吧。
结合下图可以独自参考一下上面的公式是什么意思.
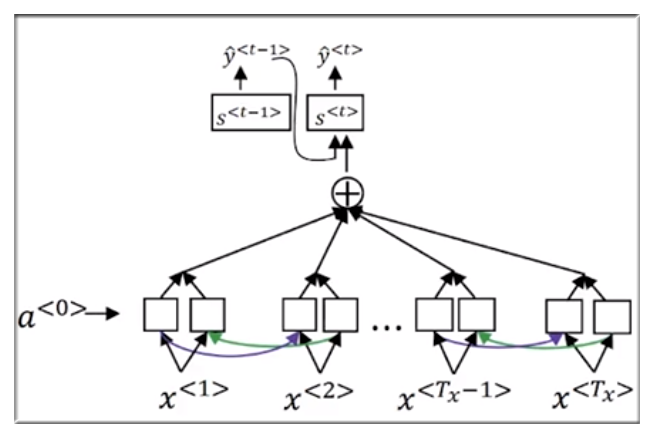
8.3 大数据文摘
下面的笔记是《大数据文摘》的笔记,感觉他写的清楚一些:
通过之前的学习可以看到机器翻译是将所有要翻译的内容统一输入然后再开始生成结果,但这样有一个弊端就是在句子特别长的时候后面的内容有的时候无法翻译的特别的准确。通过搭建 attention model 可以解决这个问题:
如图所示,这是一个 BRNN,并且在普通 RNN 的基础上增加 attention层,将阶段性的输入部分转化为输出,这样的方式也更符合人类的翻译过程。
让我们拿出细节部分仔细的理解一下,首先是 attention 层,也就是下图中 ,每一个 attention 单元接受 三个单词的输入所以也称作语境单元(context), α 是每单个输入词在语境单元中占得权重。对每一个语境单元 t 来说,因为 α 是通过 softmax 决定的,所以 . 这里决定终每一个单词占得语境权重仍然是通过一 个小型的神经网络来进行计算并且后得到的。
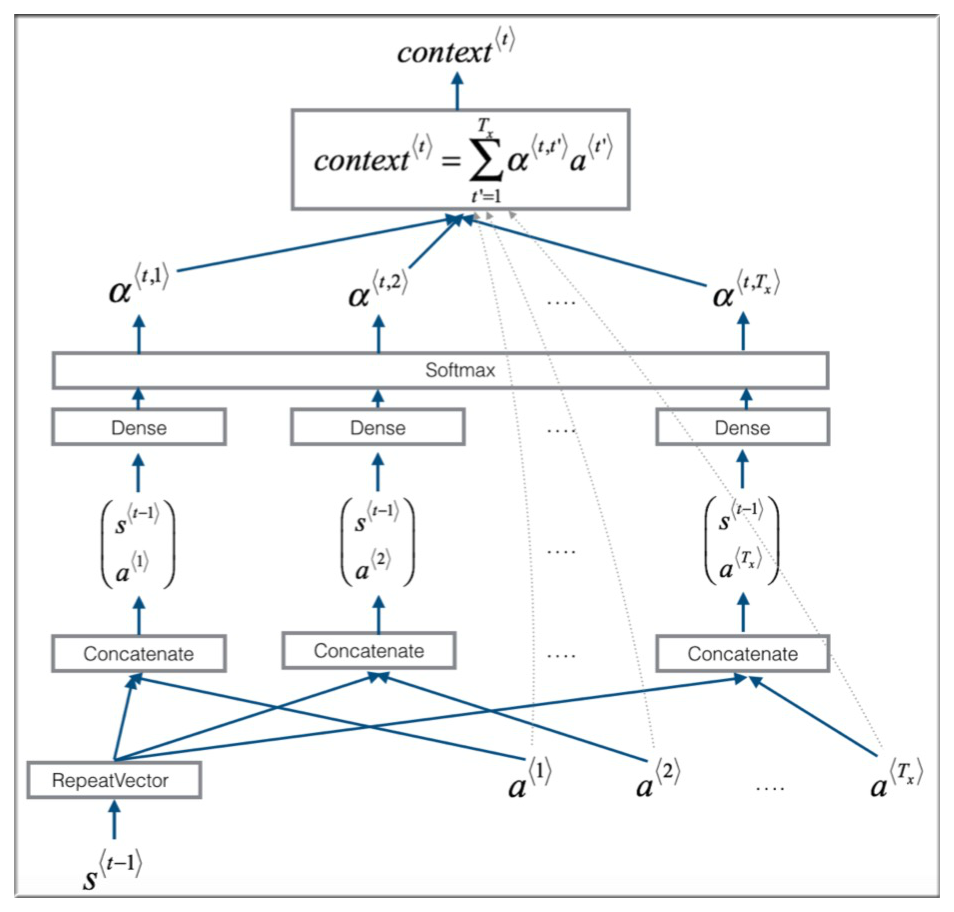
输出的 进入到下一层 Post LSTM 这一步就和之前学习过的那样子,将前一步的输出与这一步经过重重分析的输入综合到一起产生这一步的输出。
让我们评估一下 attention model: 由于结构的复杂,计算量与时间比普通的语言模型要多和慢许多。不过对于机器翻译来说,由于每一句话并不会特别特比的长,所以有的时候稍微慢一点也不是完全无法接受.
一个重要 attention model 应用就是语音识别,人通过麦克风输入一句话让机器来翻译输入的内容,来看一下是如何实现的
9. Speech recognition
一般语音识别过程是如下图示的,即首先将原音频 (黑白的,纵轴表示振幅) 转化成纵轴为频率的音谱图,并且通过人工预先设定的音素(phonemes)再来识别.
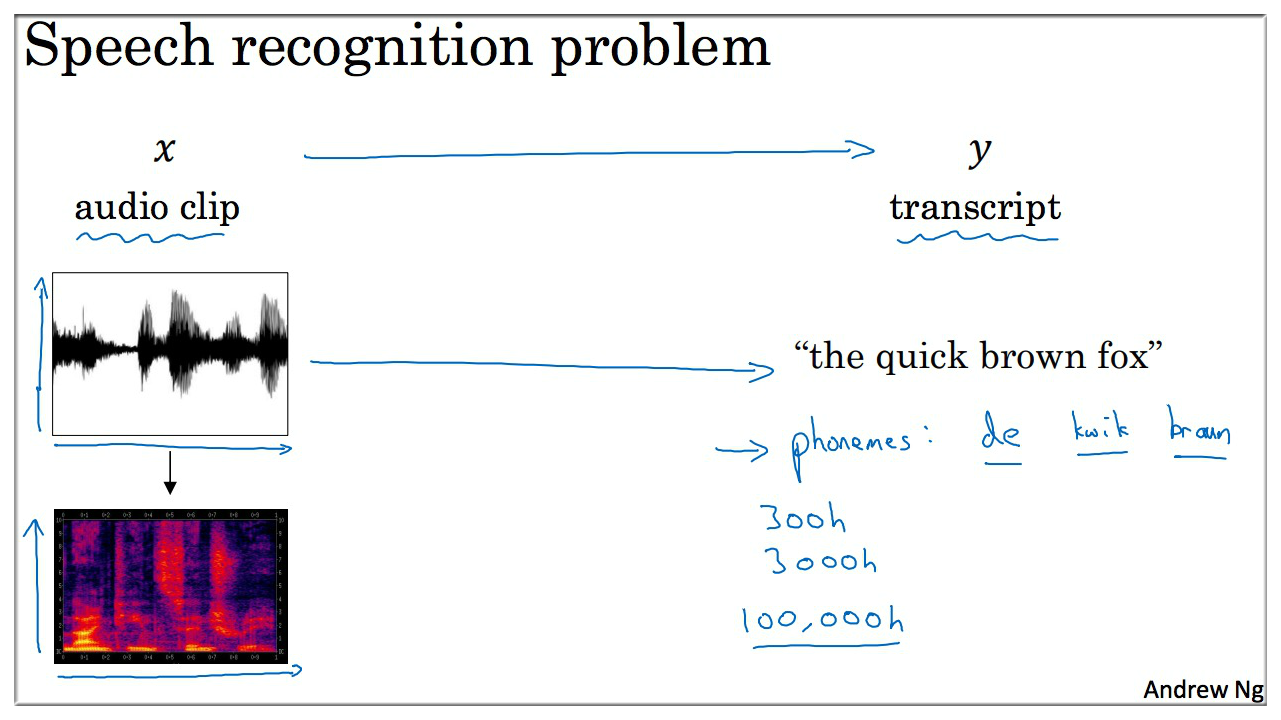
当人对着麦克风录入一句话,麦克风记录下来的是空气细微的震动的强度,以及频率。人耳在听到一句话的时候其 实做的是类似的处理。在深度学习没有特别流行之前,比较流行的是用音节做语音识别,但现在因为有了强大的 attention model,得到的结果比音节的效果更好。
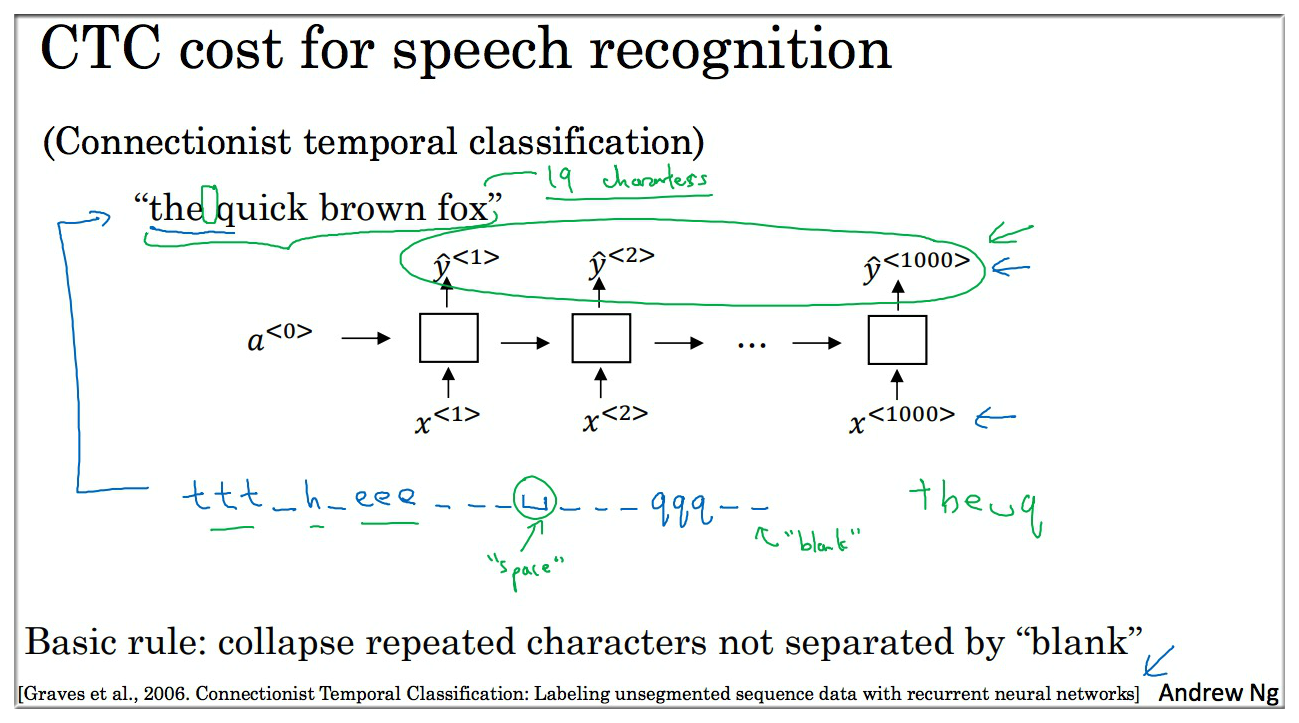
CTC(connectionist temporal classification)是之前较为常用的方法。
具体原理如下:
假设每秒音频可以提取出 100 个特征值,那么假设 10秒 的音频就有 1000 个特征值,那么输出值也有 1000 个,但是说出的话并没有这么多啊,那该怎么处理呢?
方法很简单,只需要把“”进行压缩即可,注意需要将 ""和空额区分开来,因为空格也是占一个字符的。
10. Trigger word detection

假设下图式训练集中的一段音频,其中包含了两次唤醒词:
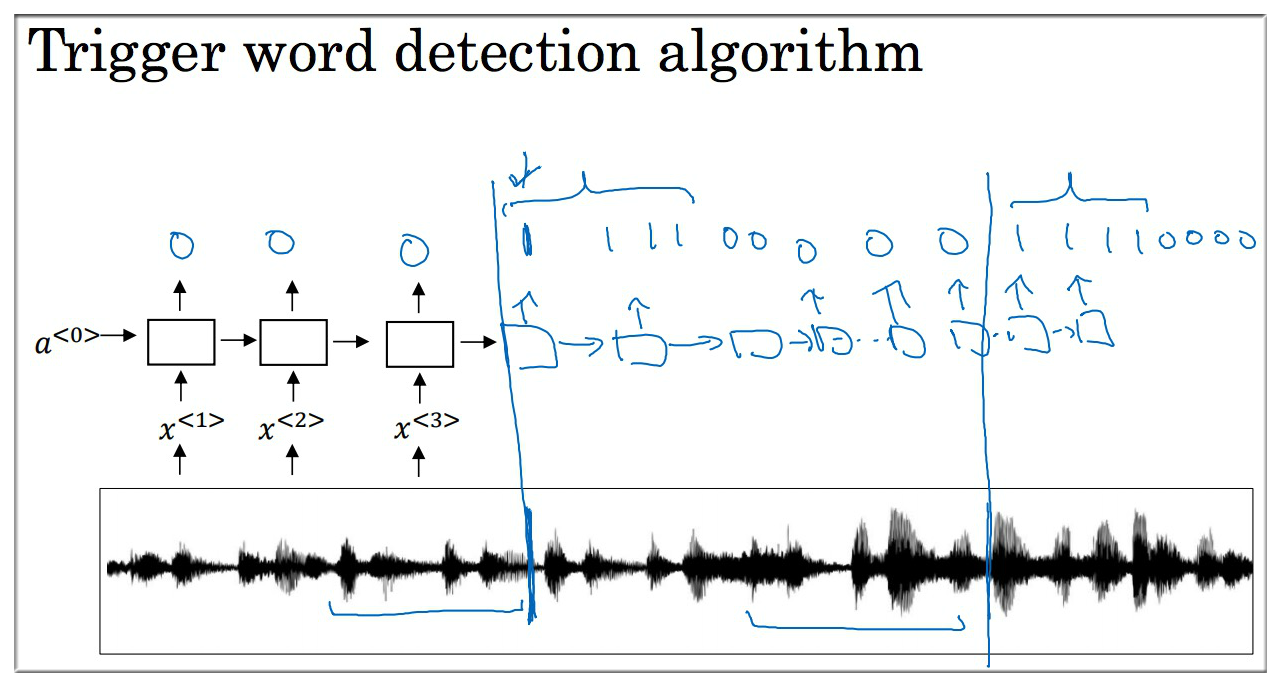
搭建一个 attention model,在听到唤醒词之前一直输出的是 0,在听到唤醒词以后输出 1,但因为一个唤醒词会持续半秒左右所以我们也不仅仅只输出一次 1,而是将输出的 1 持续一段时间,通过这样的方式训练出的 RNN 就可以很 有效的检测到唤醒词了。
11. Summary and thank you
终于学完了。虽然并不能说明什么~~~233333
感谢吴恩达和他的团队给我们带来这么好的教程
Checking if Disqus is accessible...