Chatbot Research 3 - 机器学习构建 chatbot
Chatterbot 聊天机器人框架
检索与匹配 & 分类与朴素贝叶斯
关于聊天机器人的思考
- 工程考量
- 机器学习角度考虑
预备知识
- 检索与匹配
- 分类与朴素贝叶斯
chatterbot
- 架构与使用方法
- 源码分析
1. 传统聊天机器人
NLP 基础知识
- 基本分词 (jieba)
- 关键词抽取 (tf-idf等)
- 正则表达式模式匹配
- …
Machine Learning相关知识
- 文本表示与匹配
- 分类 (文本场景分析)
- 数据驱动 (特征工程)
- …
2. 聊天机器人的一些思考
工程考量
- 架构设计清晰、模块化
- 功能分拆,解耦,部件可插拔与扩展
算法与机器学习角度考量
- 算法简单,数据(特征)驱动
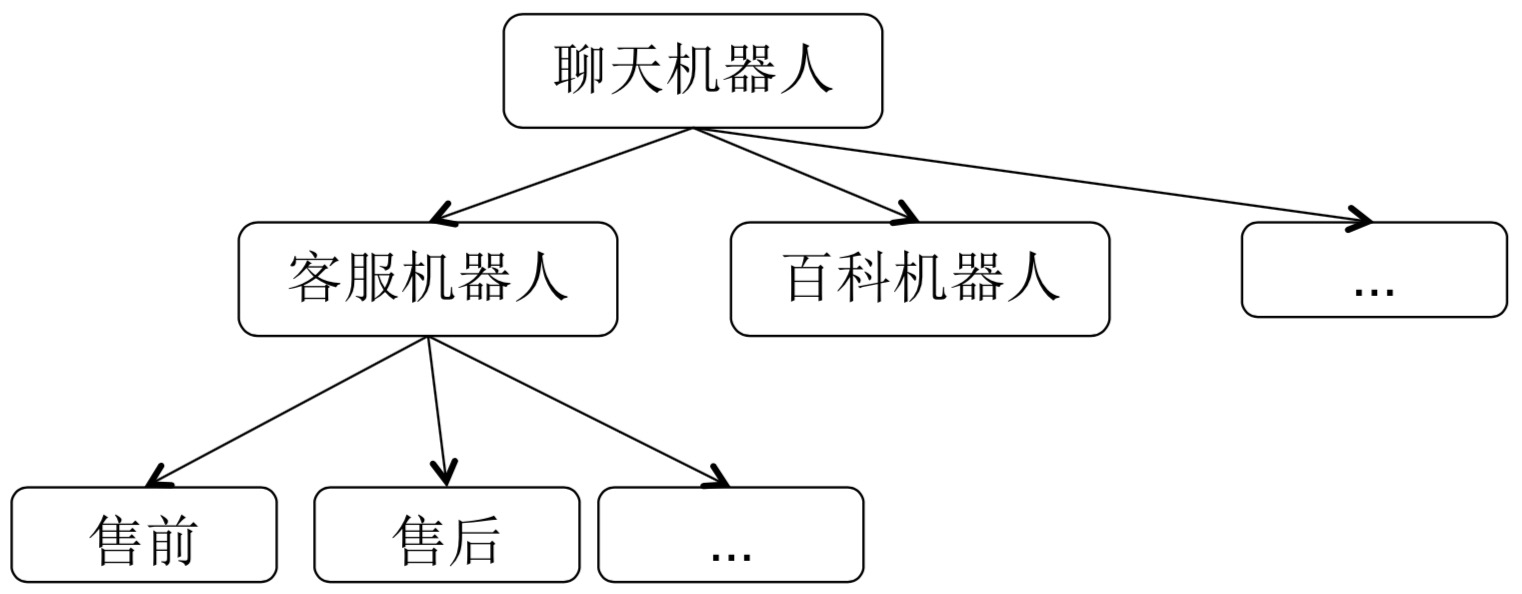
- 场景化与垂直领域
3. 预备知识
基于检索与匹配
- 知识库 (存储了问题与回复内容)
- 检索: 搜寻相关问题
- 匹配: 对结果进行排序
编辑距离
编辑距离/Levenshtein距离,是指两个字符串之间,由一个转成另一个所需要的最少编辑操作次数。
递归 & 动态规划 DP
TFIDF
QA pair 的 TFIDF 的相近度
S1: “你喜欢什么书”
S2: “你喜欢什么电影”
python 编辑距离
Python在string 类型中,默认的 utf-8 编码下,一个中文字符是用三个字节来表示的。用unicode。
1 | # -*- coding:utf-8 -*- |
4. Chatterbot 聊天机器人

每个部分都设计了不同的 “适配器”(Adapter)
机器人应答逻辑 => Logic Adapters
- Closest Match Adapter
字符串模糊匹配(编辑距离)- Closest Meaning Adapter
借助 nltk 的 WordNet,近义词评估- Time Logic Adapter
处理涉及时间的提问- Mathematical Evaluation Adapter 涉及数学运算
存储器后端 => Storage Adapters
- Read Only Mode
只读模式,当有输入数据到 chatterbot 的时候,数据库并不会发生改变- Json Database Adapter
用以存储对话数据的接口,对话数据以 Json格式 进行存储. (载入数据特别慢,工业界不可行)- Mongo Database Adapter
以 MongoDB database 方式来存储对话数据
输入形式 => Input Adapters
- Variable input type adapter
允许 chatterbot 接收不同类型的输入的,如 strings, dictionaries 和Statements- Terminal adapter
使得 ChatterBot 可以通过终端进行对话- Speech recognition
语音识别输入,详见 chatterbot-voice
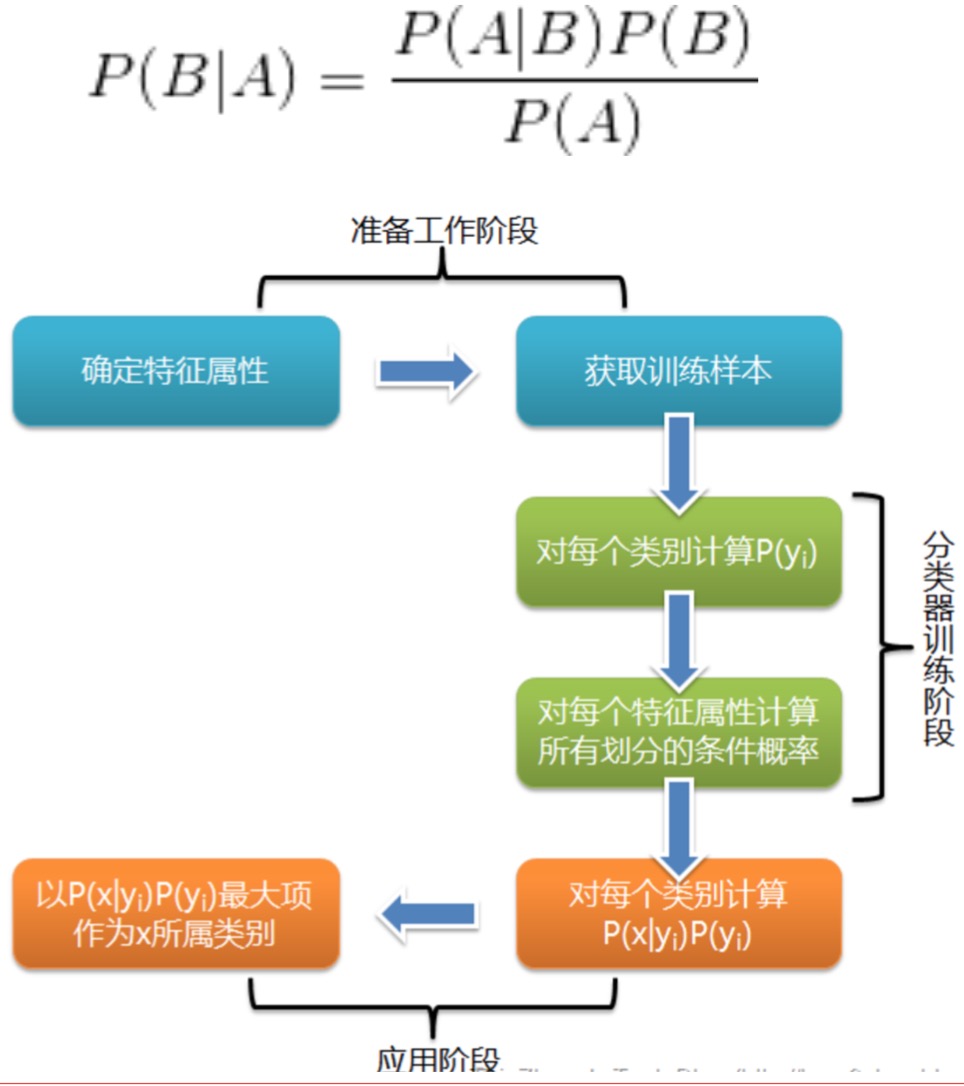
5. Bayes 分类
预备知识:场景分类与NB
Reference
- github ChatterBot
- Docs » About ChatterBot
- 使用chatterbot构建自己的中文chat(闲聊)机器人/
- 自然语言处理 Chatterbot聊天机器人
- 精品: 开源ChatterBot工作原理
Checking if Disqus is accessible...