Spark Machine Learning p2 - 设计机器学习系统
《Spark Machine Learing》 Reading Notes : 如何设计机器学习系统 moiveStream
1. 原始 MovieStream 介绍
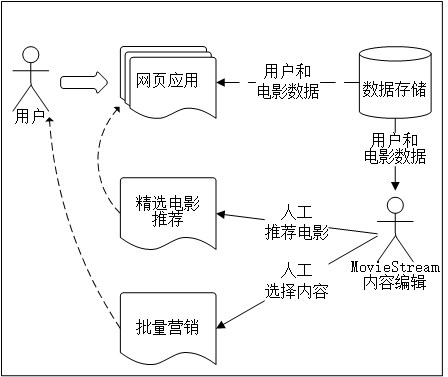
1.1 个性化
个性化 是根据各因素来改变用户体验和呈现给用户内容。这些因素可能包括用户的行为数据和外部因素。
推荐(recommendation), 常指向用户呈现一个他们可能感兴趣的物品列表。
个性化和推荐十分相似, 根据因素改变搜索的呈现不同用户不同内容,这是隐式个性化
1.2 客户细分
目标营销用与推荐类似的方法从用户群中找出要营销的对象。一般来说,推荐和个性化的应用场景都是一对一,根据用户的特征进行分组,并可能参考行为数据。也可能使用了某种机器学习模型,比如 聚类。
1.3 预测建模
预测性分析 从某种意义上说还覆盖推荐、个性化和目标营销。用预测建模(predictive modeling)来表示其他做预测的模型。借助活动记录、收入数据以及内容属性,MovieStream 可以创建一个回归模型(regression model)来预测新电影的市场表现。
另外,我们也可使用分类模型(classificaiton model)来对只有部分数据的新电影自动分配标签、关键字或分类。
2. 机器学习模型的种类
supervised learning:这种方法使用已标记数据来学习。推荐引擎、回归和分类便是例子。它们所使用的标记数据可以是用户对电影的评级(对推荐来说)、电影标签(对上述分类例子来说)或是收入数字(对回归预测来说).
unsupervised learning:一些模型的学习过程不需要标记数据,我们称其为无监督学习。这类模型试图学习或是提取数据背后的结构或从中抽取最为重要的特征。聚类、降维和文本处理的某些特征提取都是无监督学习.
3. 数据驱动ML系统的组成
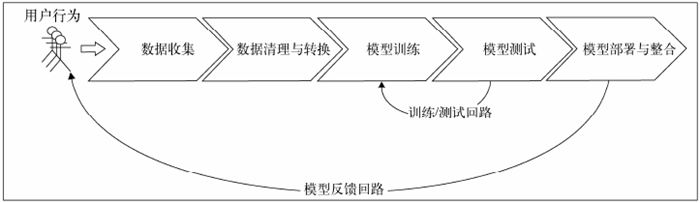
3.1 数据获取与存储
MovieStream 的数据通常来自用户活动.
要存储的数据包括:原始数据、即时处理后的数据,以及可用于生产系统的最终建模结果。
数据存储
- 文件系统 : 如 HDFS、Amazon S3 等;
- SQL数据库 : 如 MySQL、PostgreSQL;
- NoSQL : -如 HBase、Cassandra、Mongodb;
- 搜索引擎 : 如 Solr 、Elasticsearch;
- 流数据 : – 如 Kafka、Flume、Amazon Kinesis
3.2 数据清理与转换
大部分机器学习模型所处理的都是 feature。特征 通常是输入变量所对应的可用于模型的数值表示。
原始数据 预处理 几种 情况
- 数据过滤
- 合并多个数据源
- 数据汇总
对许多模型类型来说,这种表示就是包含 数值数据的 向量 or 矩阵。
将类别数据(比如地理位置所在的国家或是电影的类别)编码为对应的数值表示。
- 文本数据提取有用信息。
- 处理图像或是音频数据。
- 数值数据常被转换为类别数据以减少某个变量的可能值的数目。例如将年龄分为 601, 602…
- 对特征进行正则化、标准化,以保证同一模型的不同输入变量的值域相同。
这些数据清理、探索、聚合和转换步骤,都能通过Spark核心API、SparkSQL引擎和其他外部Scala、Java或Python包做到。借助 Spark 的 Hadoop功能 还能实现上述多种存储系统上的读写。
3.3 模型训练与测试回路
当数据已转换为可用于模型的形式,便可开始模型的训练和测试。
在训练数据集上运行模型并在测试数据集(即为评估模型而预留的数据,在训练阶段模型没接触过该数据)上测试其效果,这个过程一般相对直接,被称作交叉验证(cross-validation)。
Spark MLlib 来实现对各种机器学习方法的模型训练、评估以及交叉验证。
3.4 模型部署与整合
通过训练测试循环找出最佳模型后,要让它能得出可付诸实践的预测,还需将其部署到生产系统中。
这个过程一般要将已训练的模型导入特定的数据存储中。
3.5 模型监控与反馈
监控机器学习系统在生产环境下的表现十分重要。
同样值得注意的是,模型准确度和预测效果只是现实中系统表现的一部分。
我们可以尽可能在生产系统中部署不同的模型,通过调整它们而优化业务指标。实践中,这通常通过在线分割测试(live split test)进行。
模型反馈(model feedback),指通过用户的行为来对模型的预测进行反馈的过程。在现实系统中,模型的应用将影响用户的决策和潜在行为,从而反过来将从根本上改变模型自己将来的训练数据。
3.6 批处理/实时方案选择
常见的批处理方法。模型用所有数据或一部分数据进行周期性的重新训练。由于上述流程会花费一定的时间,这就使得批处理方法难以在新数据到达时立即完成模型的更新。
存在一类名为在线学习(online learning)的机器学习方法。它们在新数据到达时便能立即更新模型,从而使实时系统成为可能。常见的例子有对线性模型的在线优化算法,如随机梯度下降法。
4. 机器学习系统架构
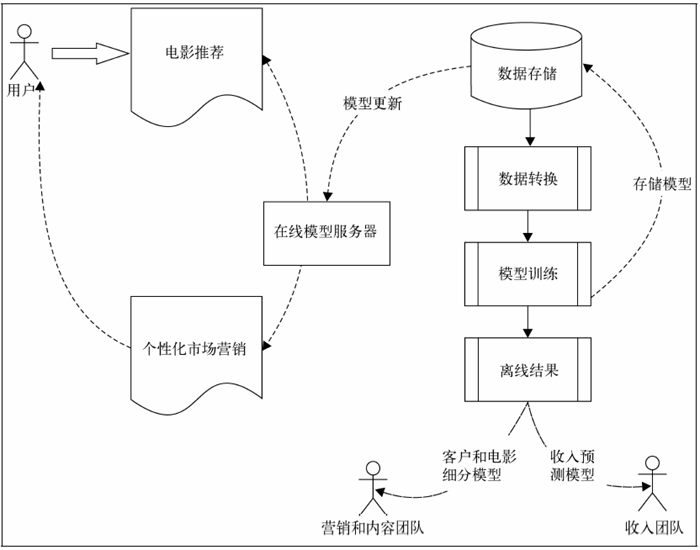
机器学习流程示意图的内容:
- 收集与用户、用户行为和电影标题有关的数据;
- 将这些数据转为特征;
- 模型训练,包括训练-测试和模型选择环节;
- 将已训练模型部署到在线服务系统,并用于离线处理;
- 通过推荐和目标页面将模型结果反馈到MovieStream站点;
- 将模型结果返回到MovieStream的个性化营销渠道;
- 使用离线模型来为MovieSteam的各个团队提供工具,以帮助其理解用户的行为、内容目录的特点和业务收入的驱动因素。
Checking if Disqus is accessible...