Spark Machine Learning p3 - 数据的获取、处理与准备
《Spark Machine Learing》 Reading Notes : Spark上数据的获取、处理与准备
MovieStream 包括网站提供的电影数据、用户的服务信息数据以及行为数据。
这些数据涉及电影和相关内容(比如标题、分类、图片、演员和导演)、用户信息(比如用户属性、位置和其他信息)以及用户活动数据(比如浏览数、预览的标题和次数、评级、评论,以及如赞、分享之类的社交数据,还有包括像Facebook和Twitter之类的社交网络属性)。
其外部数据来源则可能包括天气和地理定位信息,以及如IMDB和Rotten Tomators之类的第三方电影评级与评论信息等。
一个预测精准的好模型有着极高的商业价值(Netflix Prize 和 Kaggle 上机器学习比赛的成功就是很好的见证)
focus on
- 数据的处理、清理、探索和可视化方法;
- 原始数据转换为可用于机器学习算法特征的各种技术;
- 学习如何使用外部库或Spark内置函数来正则化输入特征.
1. 获取公开数据集
UCL机器学习知识库
包括近300个不同大小和类型的数据集,可用于分类、回归、聚类和推荐系统任务。数据集列表位于:http://archive.ics.uci.edu/ml/。
Amazon AWS公开数据集
包含的通常是大型数据集,可通过Amazon S3访问。这些数据集包括人类基因组项目、Common Crawl网页语料库、维基百科数据和Google Books Ngrams。
相关信息可参见:http://aws.amazon.com/publicdatasets/。
Kaggle
这里集合了Kaggle举行的各种机器学习竞赛所用的数据集。
它们覆盖分类、回归、排名、推荐系统以及图像分析领域,可从Competitions区域下载:http://www.kaggle.com/competitions。
KDnuggets
这里包含一个详细的公开数据集列表,其中一些上面提到过的。
该列表位于:http://www.kdnuggets.com/datasets/index.html。
MovieLens 100k数据集
MovieLens 100k数据集包含表示多个用户对多部电影的10万次评级数据,也包含电影元数据和用户属性信息
http://files.grouplens.org/datasets/movielens/ml-100k.zip
ml-100k/ u.user(用户属性文件)、u.item(电影元数据)和u.data(用户对电影的评级)
1 | >unzip ml-100k.zip |
u.user
user.id、age、gender、occupation、ZIP code
1 | >head -5 u.user |
u.item
movie id、title、release date以及若干与IMDB link和电影分类相关的属性
1 | >head -5 u.item |
u.data
user id、movie id、rating(从1到5)和timestamp属性,各属性间用制表符(\t)分隔
1 | >head -5 u.data |
2. 探索与可视化数据
IPython的安装方法可参考如下指引:http://ipython.org/install.html。
如果这是你第一次使用IPython,这里有一个教程:http://ipython.org/ipython-doc/stable/interactive/tutorial.html。
1 | IPYTHON=1 IPYTHON_OPTS="--pylab" ./bin/pyspark |
终端里的IPython 2.3.1 – An enhanced Interactive Python和Using matplotlib backend: MacOSX输出行表示IPython和pylab均已被PySpark启用。
1 | Welcome to |
可以将样本代码输入到IPython终端,也可通过IPython提供的Notebook 应用来完成。Notebook支持HTML显示,且在IPython终端的基础上提供了一些增强功能,如即时绘图、HTML标记,以及独立运行代码片段的功能。
IPython Notebook 使用指南:http://ipython.org/ipython-doc/stable/interactive/notebook.html
2.1 探索用户数据
1 | user_data = sc.textFile("/Users/hp/ghome/ml/ml-100k/u.user") |
1 | user_fields = user_data.map(lambda line: line.split("|")) |
Output
1 | Users: 943, genders: 2, occupations: 21, ZIP codes: 795 |
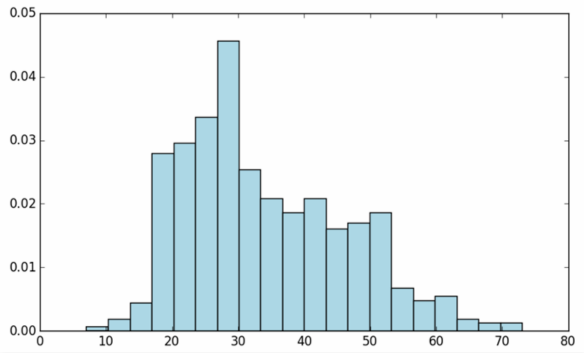
matplotlib的hist个直方图,以分析用户年龄的分布情况:
age distribution
1 | ages = user_fields.map(lambda x: int(x[1])).collect() |
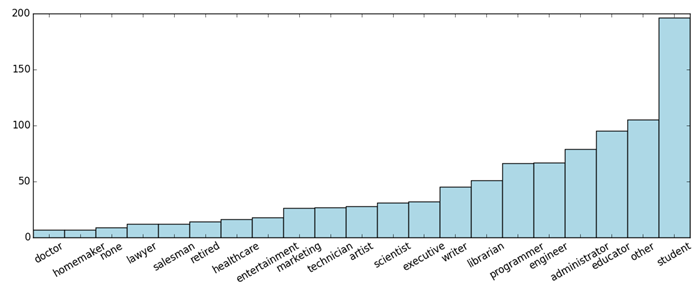
occupation distribution
1 | count_by_occupation = user_fields.map(lambda fields: (fields[3], 1)).reduceByKey(lambda x, y: x + y).collect() |
plt.xticks(rotation=30)之类的代码 是 美化条形图
1 | pos = np.arange(len(x_axis)) |
Spark对RDD提供了一个名为countByValue的便捷函数
1 | count_by_occupation2 = user_fields.map(lambda fields: fields[3]).countByValue() |
2.2 探索电影数据
1 | movie_data = sc.textFile("/PATH/ml-100k/u.item") |
1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0
Movies: 1682
1 | def convert_year(x): |
1 | movie_fields = movie_data.map(lambda lines: lines.split("|")) |
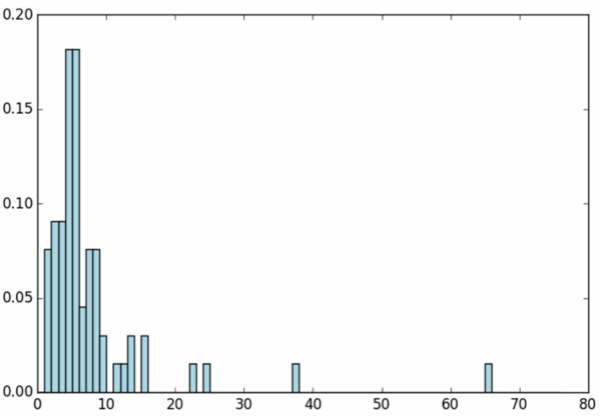
2.3 探索评级数据
1 | rating_data = sc.textFile("/Users/hp/ghome/ml/ml-100k/u.data") |
1 | rating_data = rating_data.map(lambda line: line.split("\t")) |
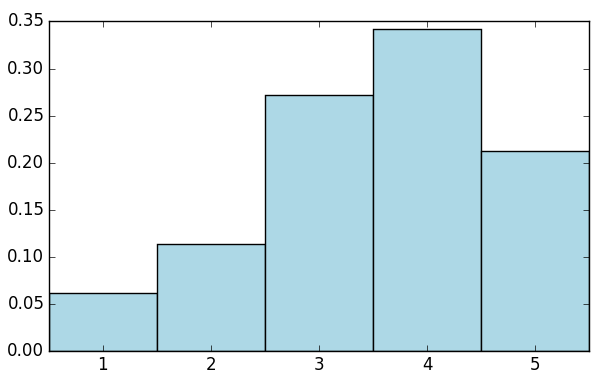
Max rating: 5
Average rating: 3.00
Median rating: 4
Average # of ratings per user: 106.00
Average # of ratings per movie: 59.00
Spark对RDD也提供一个名为states的函数。该函数包含一个数值变量用于做类似的统计:
1 | ratings.stats() |
1 | count_by_rating = ratings.countByValue() |
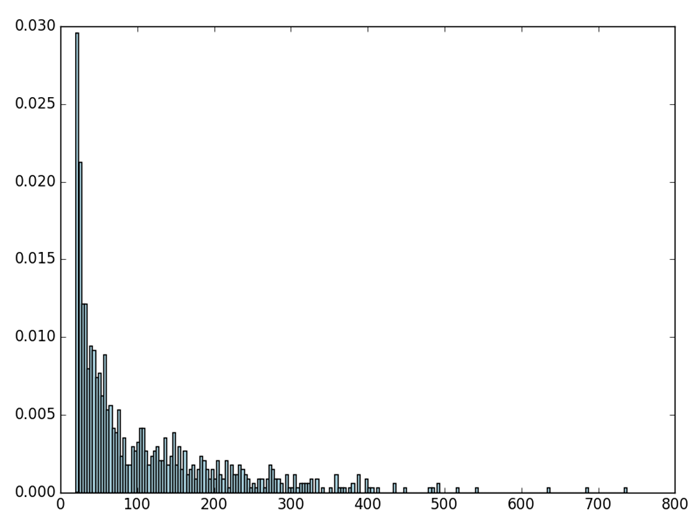
各个用户评级次数的分布情况
1 | user_ratings_grouped = rating_data.map(lambda fields: (int(fields[0]), int(fields[2]))).groupByKey() |
1 | user_ratings_byuser_local = user_ratings_byuser.map(lambda (k, v): v).collect() |
3. 处理与转换数据
非规整数据和缺失数据的填充
4. 从数据中提取有用特征
在完成对数据的初步探索、处理和清理后,便可从中提取可供机器学习模型训练用的特征。
特征(feature)指那些用于***模型训练的变量***。每一行数据包含可供提取到训练样本中的各种信息。
几乎所有机器学习模型都是与用向量表示的数值特征打交道;需将原始数据转换为数值。
特征可以概括地分为如下几种。
- 数值特征(numerical feature):这些特征通常为实数或整数,比如之前例子中提到的年龄。
- 类别特征(categorical feature):我们数据集中的用户性别、职业或电影类别便是这类。
- 文本特征(text feature):它们派生自数据中的文本内容,比如电影名、描述或是评论。
- 其他特征:… 地理位置则可由经纬度或地理散列(geohash)表示。
4.1 数值特征
原始的数值和一个数值特征之间的区别是什么?
机器学习模型中所学习的是各个特征所对应的向量的权值。这些权值在特征值到输出或是目标变量(指在监督学习模型中)is very important。
当数值特征仍处于原始形式时,其可用性相对较低,但可以转化为更有用的表示形式。
如 (位置信息 : 原始位置信息(比如用经纬度表示的),信息可用性很低。 然若对位置进行聚合(比如聚焦为一个city or country),和特定输出 之间存在某种关联。
4.2 类别特征
将类别特征表示为数字形式,常可借助 k 之1(1-of-k)方法进行
比如,可取occupation 所有可能取值:
1 | all_occupations = user_fields.map(lambda fields: fields[3]). distinct().collect() |
然可依次对各可能的职业分配序号(注意 从0开始编号):
1 | idx = 0 |
其输出如下:
1 | Encoding of 'doctor': 2 |
4.3 派生特征
从原始数据派生特征的例子包括计算平均值、中位值、方差、和、差、最大值或最小值以及计数。从电影的发行年份和当前年份派生了新的movie age特征的。这类转换背后的想法常常是对数值数据进行某种概括,并期望它能让模型学习更容易。
数值特征到类别特征的转换也很常见,比如划分为区间特征。进行这类转换的变量常见的有年龄、地理位置和时间。
如 : 将时间戳转为类别特
电影评级发生的时间
[‘afternoon’, ‘evening’, ‘morning’, ‘morning’, ‘morning’]
4.4 文本特征
文本特征也是一种类别特征或派生特征
NLP 便是专注于文本内容的处理、表示和建模的一个领域。
介绍一种简单且标准化的文本特征提取方法。该方法被称为词袋(bag-of-word)表示法。
词袋法将一段文本视为由其中的文本或数字组成的集合,其处理过程如下。
bag-of-word
(1) 分词(tokenization)
首先会应用某些分词方法来将文本分隔为一个由词(一般如单词、数字等)组成的集合。
(2) 删除停用词(stop words removal)
删除常见的单词,比如the、and和but(这些词被称作停用词)。
(3) 提取词干(stemming):
是指将各个词简化为其基本的形式或者干词。常见的例子如复数变为单数(比如dogs变为dog等)。提取的方法有很多种,文本处理算法库中常常会包括多种词干提取方法。
(4) 向量化(vectorization) :
向量来表示处理好的词。二元向量可能是最为简单的表示方式。它用1和0来分别表示是否存在某个词。从根本上说,这与之前提到的 k 之1编码相同。与 k 之1相同,它需要一个词的字典来实现词到索引序号的映射。随着遇到的词增多,各种词可能达数百万。由此,使用稀疏矩阵来表示就很关键。这种表示只记录某个词是否出现过,从而节省内存和磁盘空间,以及计算时间。
提取简单的文本特征
参见 : http://www.ituring.com.cn/tupubarticle/5567
现在每一个电影标题都被转换为一个稀疏向量。
4.5 正则化特征
在将特征提取为向量形式后,一种常见的预处理方式是将数值数据正则化(normalization)。其背后的思想是将各个数值特征进行转换,以将它们的值域规范到一个标准区间内。正则化的方法有如下几种。
- 正则化特征:这实际上是对数据集中的单个特征进行转换。比如减去平均值(特征对齐)或是进行标准的正则转换(以使得该特征的平均值和标准差分别为0和1)。
- 正则化特征向量:这通常是对数据中的某一行的所有特征进行转换,以让转换后的特征向量的长度标准化。也就是缩放向量中的各个特征以使得向量的范数为1(常指一阶或二阶范数)。
向量正则化可通过numpy的norm函数来实现。具体来说,先计算一个随机向量的二阶范数,然后让向量中的每一个元素都除该范数,从而得到正则化后的向量:
1 | np.random.seed(42) |
其输出应该如下(上面将随机种子的值设为42,保证每次运行的结果相同):
1 | x: [ 0.49671415 -0.1382643 0.64768854 1.52302986 -0.23415337 -0.23413696 |
用 MLlib 正则化特征
Spark在其MLlib机器学习库中内置了一些函数用于特征的缩放和标准化。它们包括供标准正态变换的StandardScaler,以及提供与上述相同的特征向量正则化的 Normalizer。
比较一下MLlib的Normalizer与我们自己函数的结果:
1 | from pyspark.mllib.feature import Normalizer |
在导入所需的类后,会要初始化Normalizer(其默认使用与之前相同的二阶范数)。注意用Spark时,大部分情况下Normalizer所需的输入为一个RDD(它包含numpy数值或MLlib向量)。作为举例,我们会从x向量创建一个单元素的RDD。
之后将会对我们的RDD调用Normalizer的transform函数。由于该RDD只含有一个向量,可通过first函数来返回向量到驱动程序。接着调用toArray函数来将该向量转换为numpy数组:
1 | normalized_x_mllib = normalizer.transform(vector).first().toArray() |
相比自己编写的函数,使用 MLlib内置的函数 更方便
4.6 用软件包提取特征
特征提取可借助的软件包有scikit-learn、gensim、scikit-image、matplotlib、Python的NLTK、Java编写的OpenNLP以及用Scala编写的Breeze和Chalk。Breeze自Spark 1.0开始就成为Spark的一部分了。Breeze有线性代数功能。
5. 小结
了解 如何导入、处理和清理数据,如何将原始数据转为特征向量以供模型训练的常见方法
Checking if Disqus is accessible...