Diligence is not a race against time, but continuous, dripping water wears through the rock.
小舟從此逝 江海寄餘生🧘 is inputting 
2022.05.27: review: spark vs MR Spark面试整理 hdc520 大全好总结
- DAG计算模型. spark遇到 wide dependency 才会出现shuffer,而hadoop每次MapReduce都会有一次shuffer;
- MapReduce 每次shuffle 操作后,必须写到磁盘, 而spark可以 cache/persist. RDD在每次transformation后并不立即执行,而且action后才执行,有进一步减少了I/O操作。
- MR它必须等map输出的所有数据都写入本地磁盘文件以后,才能启动reduce操作
- spark 利用多线程来执行具体的任务(Hadoop MapReduce采用的是进程模型),减少任务的启动和切换开销;
spark的RDD与DataFrame以及Dataset的区别
(1)RDD特点
1)弹性:RDD的每个分区在spark节点上存储时默认是放在内存中的,若内存存储不下,则存储在磁盘中。
2)分布性:每个RDD中的数据可以处在不同的分区中,而分区可以处在不同的节点中.
3)容错性:当一个RDD出现故障时,可以根据RDD之间的依赖关系来重新计算出发生故障的RDD.2、spark的算子
(1)transform算子:map转换算子,filter筛选算子,flatmap,groupByKey,reduceByKey,sortByKey,join,cogroup,combinerByKey。
(2)action算子:reduce,collect,count,take,aggregate,countByKey。(2.5) coalesce与repartition的区别
1)coalesce 与 repartition 都是对RDD进行重新划分,repartition只是coalesce接口中参数shuffle为true的实现。
2)若coalesce中shuffle为false时,传入的参数大于现有的分区数目,RDD的分区数不变,也就是说不经过shuffle,是无法将RDD的分区数变多的。
3)若存在过多的小任务的时候,可以通过coalesce方法,收缩合并分区,减少分区的个数,减小任务调度成本,尽量避免shuffle,这样会比repartition效率高。(2.6) reduceByKey与groupByKey的区别:
pairRdd.reduceByKey(+).collect.foreach(println)等价于pairRdd.groupByKey().map(t => (t._1,t._2.sum)).collect.foreach(println)
reduceByKey的结果:(hello,2)(world,3) groupByKey的结果:(hello,(1,1))(world,(1,1,1))
使用reduceByKey()的时候,会对同一个Key所对应的value进行本地聚合,然后再传输到不同节点的节点。而使用groupByKey()的时候,并不进行本地的本地聚合,而是将全部数据传输到不同节点再进行合并,groupByKey()传输速度明显慢于reduceByKey()。虽然groupByKey().map(func)也能实现reduceByKey(func)功能,但是,优先使用reduceByKey(func).(2.7) spark的cache和persist的区别:
1)计算流程DAG特别长,服务器需要将整个DAG计算完成得出结果,若计算流程中突然中间算出的数据丢失了,spark又会根据RDD的依赖关系重新计算,这样会浪费时间,为避免浪费时间可以将中间的计算结果通过cache或者persist放到内存或者磁盘中
2)cache最终调用了persist方法,默认的存储级别仅是存储内存中的;persist是最根本的底层函数,有多个存储级别,executor执行时,60%用来缓存RDD,40%用来存放数据.九、spark如何分区:
分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的个数决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务的个数,也是由RDD(准确来说是作业最后一个RDD)的分区数决定。spark默认分区方式是HashPartitioner.只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None,每个RDD的分区ID范围:0~numPartitions-1,决定这个值是属于那个分区的。
2022.05.24DFS / Stack
2.1 字符串解码 “3[a2[c]]” == “accacc”, stack == [(3, “”), (2,“a”)]215. 数组中的第K个最大元素 from heapq import heapify, heappush, heappop
python中的heap是小根堆: heapify(hp) , heappop(hp), heappush(hp, v)
2022.05.22binary-search
1.1 二分查找, while l <= r 1.2 two_sum (easy hash) 1.3 3sum,(first, second, third)
1.4 34. 在排序数组中查找元素的第一个和最后一个位置
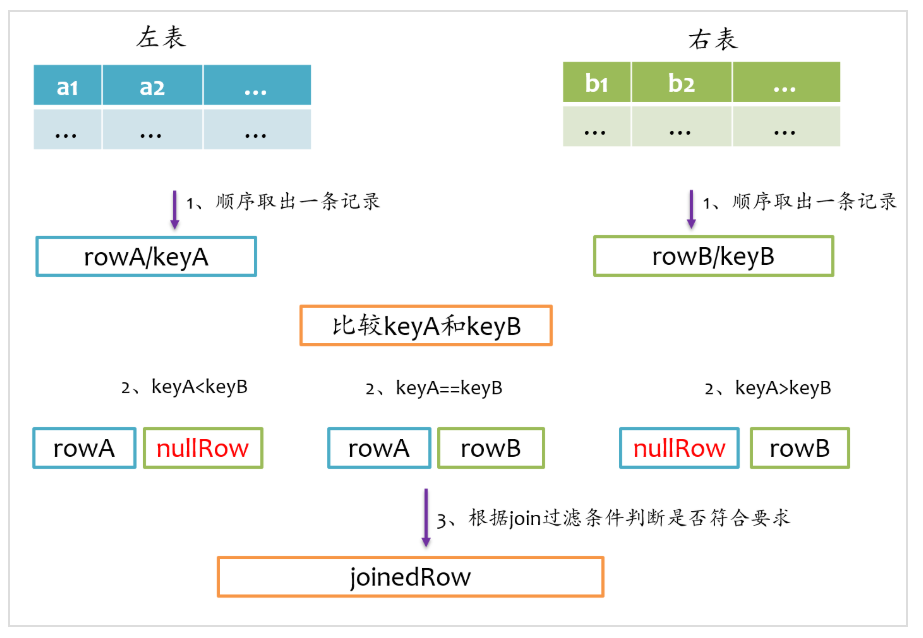
2022.05.21full outer join相对来说要复杂一点,full outer join仅采用sort merge join实现,左边和右表既要作为streamIter,又要作为buildIter
2022.05.20
1.1 Spark处理数据比Hive快的原因总结: Spark比Mapreduce运行更快 - Spark在计算模型和调度上比MR做了更多的优化,不需要过多地和磁盘交互。以及对JVM使用的优化。
(1)消除了冗余的HDFS读写(不需要过多地和磁盘交互)
(2)消除了冗余的MapReduce阶段
(3)JVM的优化[MapReduce操作,启个Task便启次JVM,进程的操作。Spark 线程]1.2 reduceByKey vs groupByKey
在spark中,我们知道一切的操作都是基于RDD的。在使用中,RDD有一种非常特殊也是非常实用的format——pair RDD,即RDD的每一行是(key, value)的格式。这种格式很像Python的字典类型,便于针对key进行一些处理。
针对pair RDD这样的特殊形式,spark中定义了许多方便的操作,今天主要介绍一下reduceByKey和groupByKey,groupByKey 当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大,导致传输延时
2
3
4
5
6
7
8
9
10
11
12
13
14
lines = lines.filter(lambda x: 'New York' in x)
#lines.take(3)
words = lines.flatMap(lambda x: x.split(' '))
wco = words.map(lambda x: (x, 1))
#print(wco.take(5))
from operator import add
word_count = wco.reduceByKey(add)
word_count.collect()
2022.05.19English My Job2021 blair Notes / 2020 Interview Questions - Data Warehouse
2
3
4
5
6
7
8
9
10
11
12
13
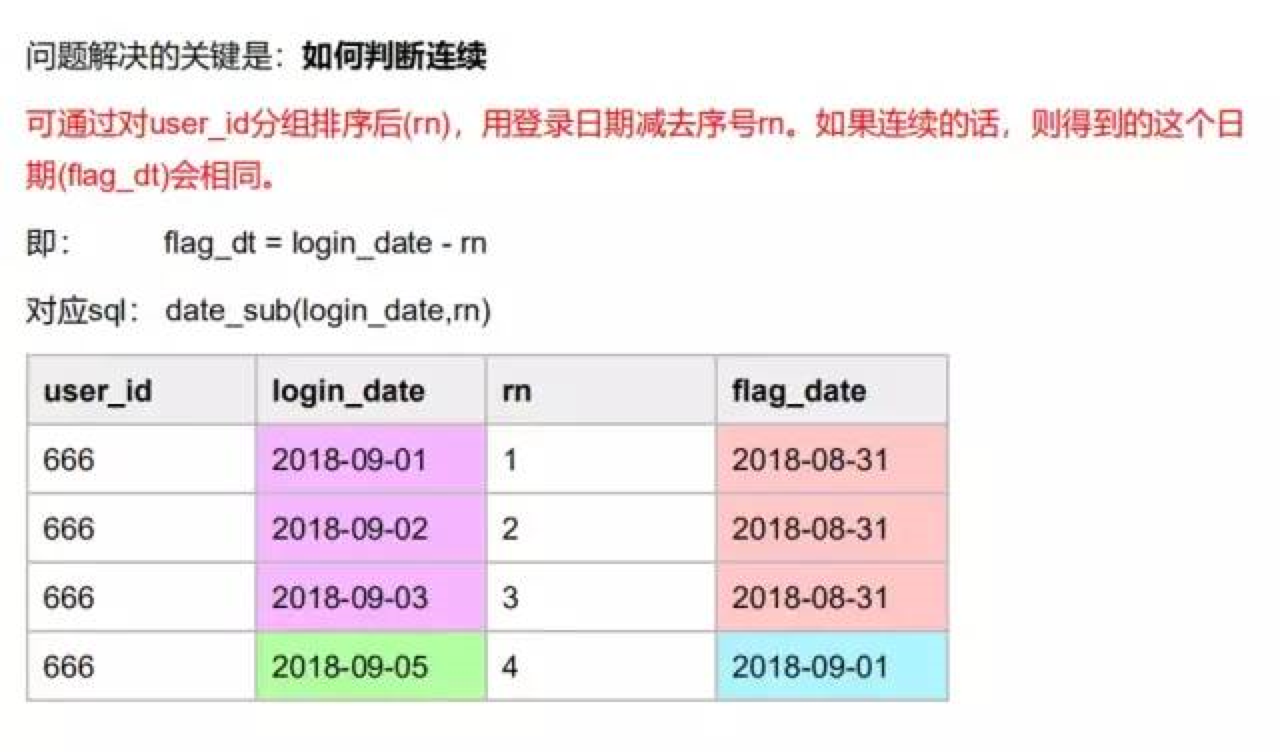
select
user_id, count(1) cnt
from
(
select
user_id,
login_date,
row_number() over(partition by user_id order by login_date) as rn
from tmp.tmp_last_3_day
) t
group by user_id, date_sub(login_date, t.rn)
having count(1) >= 3;
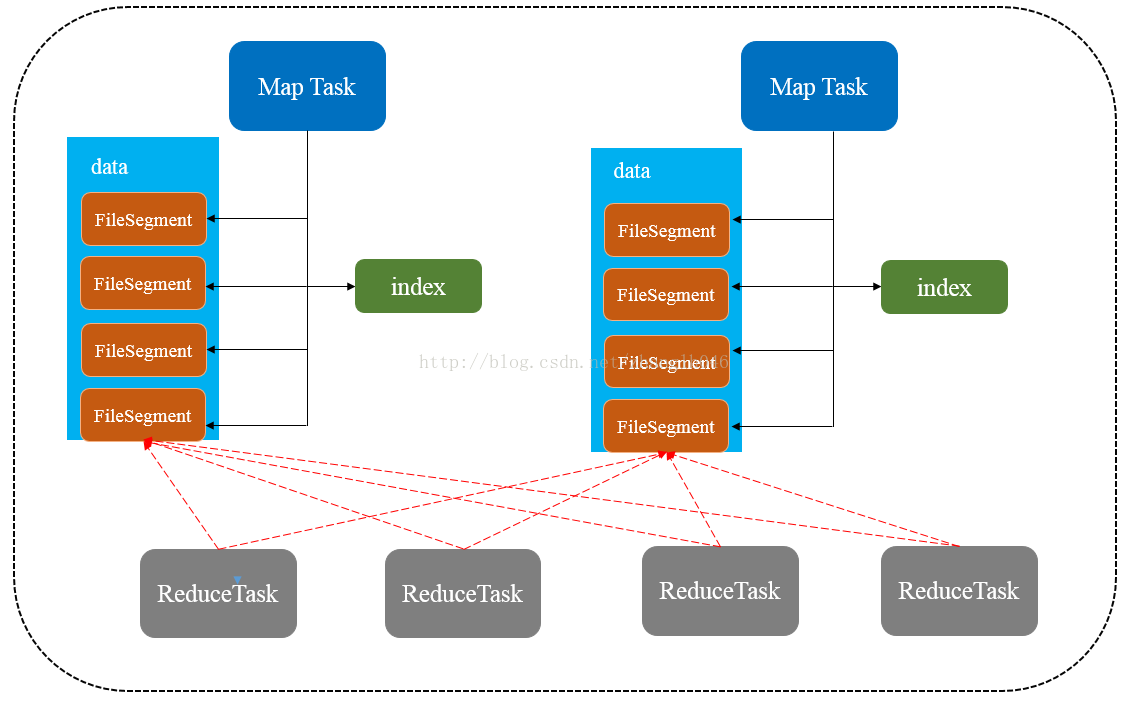
2022.05.18shuffle形式有几种?都做哪些优化 & English BBC - <如果在相遇,我会记得你> the good old songsspark基础之shuffle机制、原理分析及Shuffle的优化(很好很详细)
Shuffle就是对数据进行重组,由于分布式计算的特性和要求,在实现细节上更加繁琐和复杂
- HashShuffle(<=spark1.6,会产生很多小文件, Writer费内存易GC)
- Sort-Based Shuffle (有多重model,不展开)
Transformation 操作如:repartition,join,cogroup,以及任何 *By 或者 *ByKey 的 Transformation 都需要 shuffle 数据9,合理的选用操作将降低 shuffle 操作的成本,提高运算速度
2022.05.17SparkSQL Join & English BBC - 诸事不顺的一天 The English we We Speak
- join 实现有几种呢,源码有研究过吗? 底层是怎么实现的
面试必知的Spark SQL几种Join实现 - (streamIter为大表,buildIter为小表)
sort merge join / broadcast join / hash join
Spark 精品
Shuffle不过是偷偷的帮你加上了个类似saveAsLocalDiskFile的动作。然而,写磁盘是一个高昂的动作。所以我们尽可能的把数据先放到内存,再批量写到文件里,还有读磁盘文件也是给费内存的动作。
Cache/Persist意味着什么?
其实就是给某个Stage加上了一个saveAsMemoryBlockFile的动作, Spark允许你把中间结果放内存里.
萝卜姐: Is the ByteDance interview difficult and how should you deal with it?
1. skill dismantling
1.1 底层原理,源码理解。
1.2 项目相关,难点,仓库建模
1.3 show sql
spark和hive:
-
是通过什么管理shuffle中的内存,磁盘 的
-
讲讲谓词下推?
-
full outer join原理
-
spark为什么比hive快
-
讲讲sparksql优化
-
讲讲RDD, DAG, Stage
-
说说groupByKey, reduceByKey
-
spark是怎么读取文件,分片的?
-
有没有遇到过spark读取文件,有一些task空跑的现象?
-
窗口函数中 几个rank函数有啥不同(spark、hive中窗口函数实现原理复盘 Hive sql窗口函数源码分析 sparksql比hivesql优化的点(窗口函数))parquet文件和orc文件有啥不同mr shuffle 是什么样子?具体原理是什么?跟spark有什么不同?讲讲hive sql优化hive 数据倾斜参数原理讲讲spark内存模型?(从一个sql任务理解spark内存模型 )
2. Show SQL
就会问还有没有更优化的方式?
窗口函数,groupingsets cube这些 都会用到。有好多是计算滑动的那种
这个sql 在hive中起几个job,为什么是这么几个job?
-
Be confident and positive
-
Interview tips (overcoming nervousness)
-
last last last last
1. Spark Summary
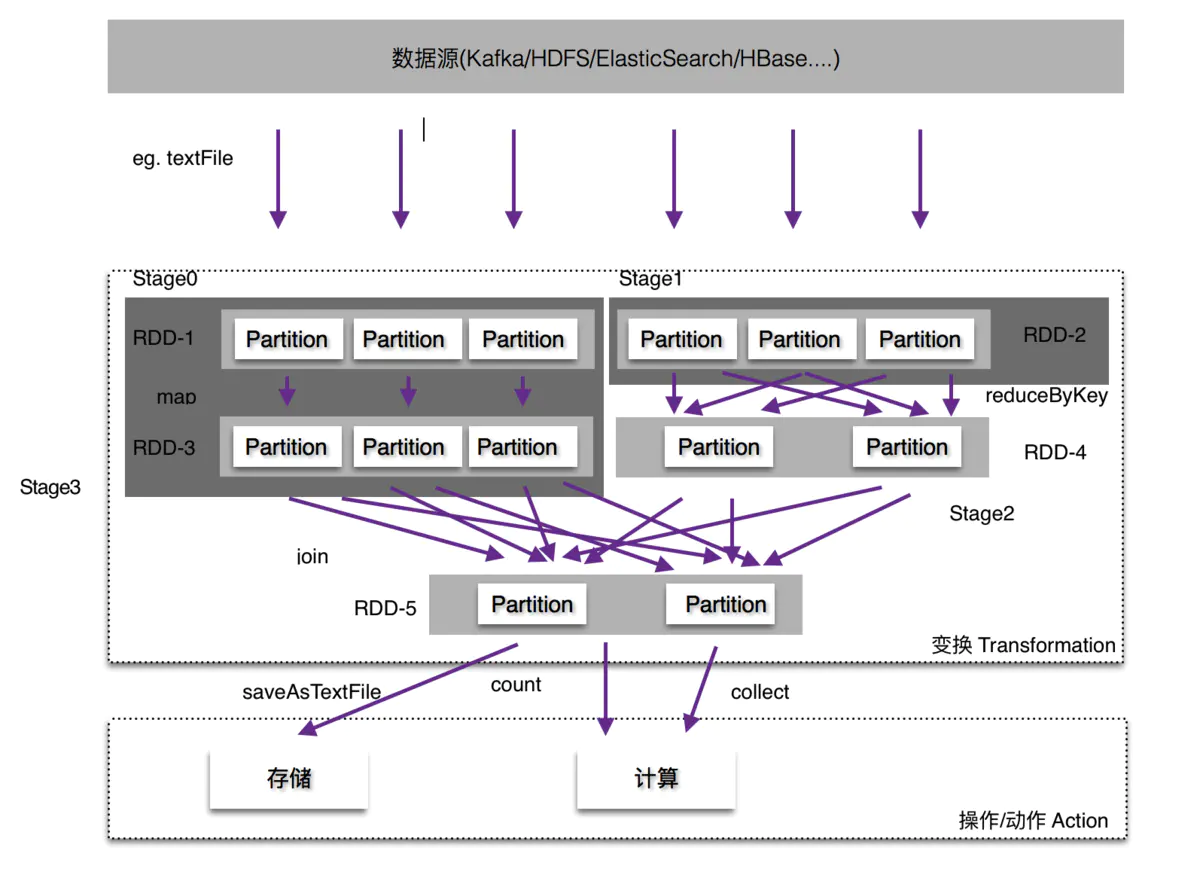
DataFrame是spark1.3.0版本提出来的
DataSet是spark1.6.0版本提出来的
但在 spark2.0 版本中,DataFrame和DataSet合并为DataSet.
2. SparkSQL
3. Spark Basic
4. Spark Review
5. Spark Interview
1 | class TreeNode: |
Checking if Disqus is accessible...