Spark 主要使用 HDFS 充当持久化层,所以完整的安装 Spark 需要先安装 Hadoop.
1. Spark On Linux
安装 JDK (green download install)
配置 SSH 免密码登陆 (可选)
安装 Hadoop (brew install hadoop)
安装 Scala (brew install scala)
安装 Spark (green download install)
启动 Spark 集群
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 MS=/usr/local /xsoft JAVA_HOME=$MS /jdk/Contents/Home JAVA_BIN=$JAVA_HOME /bin PATH=$JAVA_HOME /bin:$PATH CLASSPATH=.:$JAVA_HOME /jre/lib/rt.jar:$JAVA_HOME /jre/lib/dt.jar:$JAVA_HOME /jre/lib/tools.jar export JAVA_HOME JAVA_BIN PATH CLASSPATHexport HADOOP_HOME=/usr/local /Cellar/hadoop/3.2.1_1export PATH=$PATH :$HADOOP_HOME /sbin:$HADOOP_HOME /binexport SCALA_HOME=/usr/local /Cellar/scala/2.13.3export PATH=$PATH :$SCALA_HOME /binexport SPARK_HOME=$MS /sparkexport PATH=$PATH :$SPARK_HOME /bin
Spark官网下载
2. 安装 Spark 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 (1). tar -xzvf spark-3.0.0-bin-hadoop2.7.tgz (2). cd /usr/local /xsoft/spark-3.0.0-bin-hadoop3.2/ (3). 配置 conf/spark-env.sh 1) 详细复杂参数配置参见 官网 Configuration 2) vim conf/spark-env.sh export SCALA_HOME=/usr/local /Cellar/scala/2.13.3 export SPARK_HOME=/usr/local /xsoft/spark export SPARK_MASTER_IP=localhost export MASTER=spark://localhost:7077 export PYSPARK_PYTHON=/Users/blair/.pyenv/versions/anaconda3/envs/spark/bin/python3 export PYSPARK_DRIVER_PYTHON="jupyter" export PYSPARK_DRIVER_PYTHON_OPTS="notebook" (4). 配置 conf/slaves (测试可选) (5). 一般需要 startup ssh server.
3. 启动 Spark 在 Spark 根目录启动 Spark
1 2 ./sbin/start-all.sh ./sbin/stop-all.sh
启动后 jps 查看 会有 Master 进程存在
1 2 3 4 ➜ spark jps 11262 Jps 11101 Master 11221 Worker
4. Spark 集群初试 可以通过两种方式运行 Spark 样例 :
1 2 3 ➜ cd /usr/local /xsoft/spark ➜ spark ./sbin/start-all.sh ➜ spark ./bin/run-example org.apache.spark.examples.SparkPi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 scala> import org.apache.spark._ import org.apache.spark._ scala> object SparkPi { | | def main(args: Array[String]) { | | val slices = 2 | val n = 100000 * slices | | val count = sc.parallelize(1 to n, slices).map { i => | | val x = math.random * 2 - 1 | val y = math.random * 2 - 1 | | if (x * x + y * y < 1) 1 else 0 | | }.reduce(_ + _) | | println("Pi is rounghly " + 4.0 * count / n) | | } | } defined module SparkPi scala> // Spark Shell 已默认将 SparkContext 类初始化为对象 sc, 用户代码可直接使用。 // Spark 自带的交互式的 Shell 程序,方便进行交互式编程。
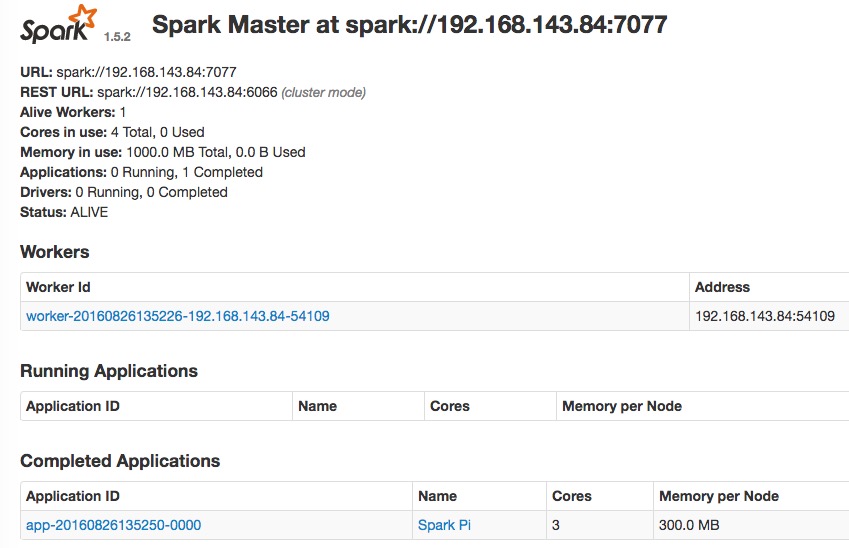
通过 Web UI 查看集群状态
http://masterIp:8080
5. Quick Start quick-start : https://spark.apache.org/docs/latest/quick-start.html
./bin/spark-shell
1 2 3 4 5 6 7 8 9 10 11 scala> val textFile = sc.textFile("README.md") # val textFile = sc.textFile("file:///usr/local/xsoft/spark/README.md") textFile: spark.RDD[String] = spark.MappedRDD@2ee9b6e3 RDDs have actions, which return values, and transformations, which return pointers to new RDDs. Let’s start with a few actions: scala> textFile.count() // Number of items in this RDD res0: Long = 126 scala> textFile.first() // First item in this RDD res1: String = # Apache Spark
Reference
Checking if Disqus is accessible...