SparkSQL indoor to optimization
sparkSQL history, use and optimize
1. SparkSQL 发展
SparkSQL 发展史
| Version | Title Description |
|---|---|
| 1.0以前 | Shark |
| Spark-1.1 | SparkSQL(只是测试性的) SQL |
| Spark<1.3 | DataFrame 称为 SchemaRDD |
| Spark-1.3 | SparkSQL(正式版本)+Dataframe API |
| Spark-1.4 | 增加窗口分析函数 |
| Spark-1.5 | SparkSQL 钨丝计划, UDF/UDAF |
| Spark-1.6 | SparkSQL 执行的 sql 可以增加注释 |
| Spark-2.x | SparkSQL+DataFrame+DataSet(正式版本), 引入 SparkSession 统一编程入口 |
| No. | Title | SparkSQL 主要用于进行结构化数据的处理。它提供的最核心的编程抽象就是DataFrame. |
|---|---|---|
| 1. | 原理 | 将 SparkSQL 转化为 RDD ,然后提交到集群执行 |
| 2. | 作用 | 提供一个编程抽象(DataFrame)并且作为分布式SQL查询引擎。 DataFrame 可据很多源进行构建,包括:结构化的数据文件,Hive中的表,MYSQL,以及RDD |
| 3. | 特点 | 1. 容易整合 2. 统一的数据访问方式 3. 兼容Hive 4. 标准的数据连接 |
| … | spark 1.x | SparkContext sc / SqlContext sqlContextS |
| … | spark 2.x | SparkContext sc / SparkSession spark |
1.1 SparkSession 创建
1 | from pyspark.sql import SparkSession |
SparkSQL 数据抽象
1.2 SparkSQL 数据抽象
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。
![RDD[Record] == DataFrame == Table](/images/spark/spark-aura-9.3.1.png)
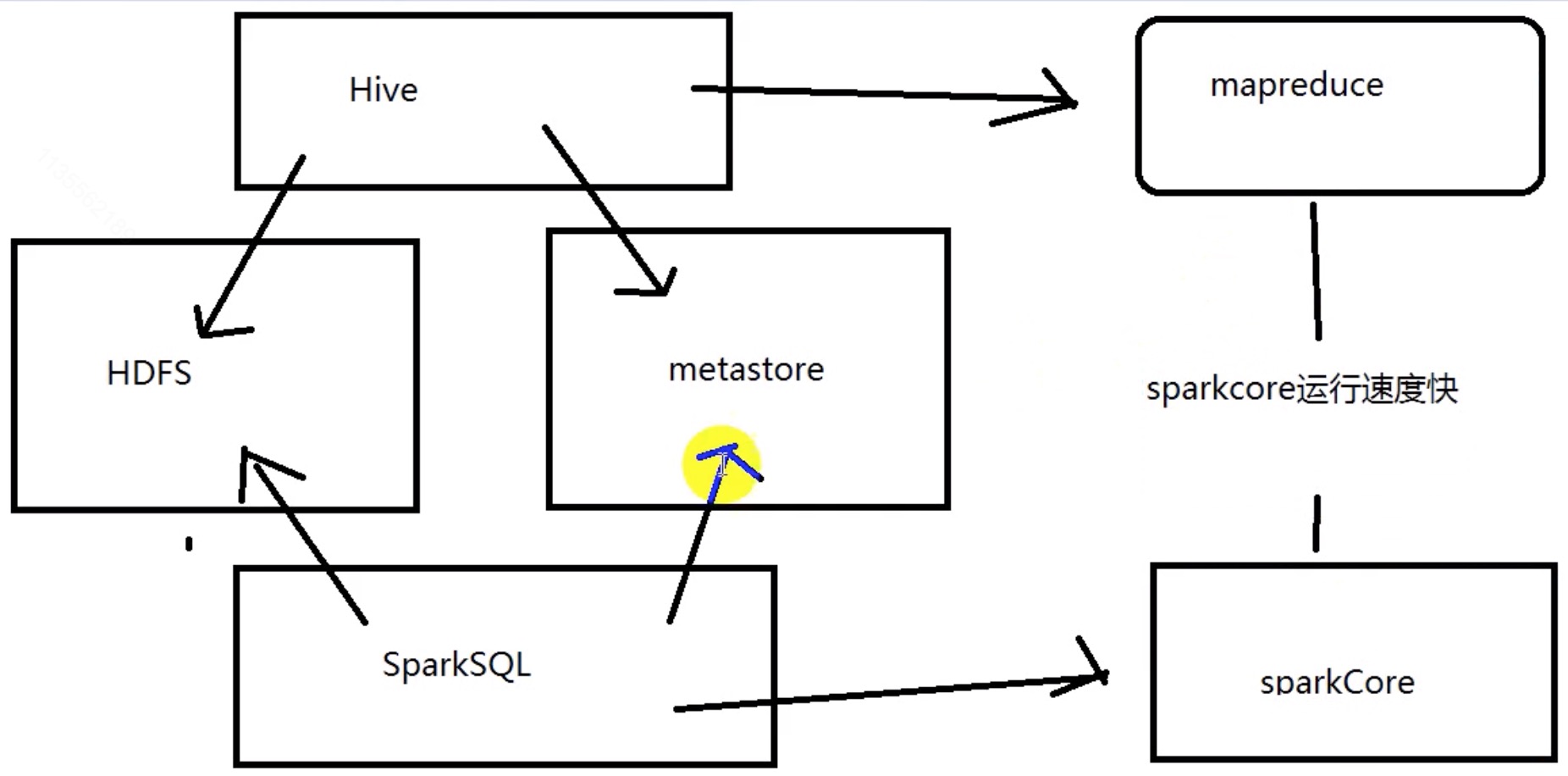
谈谈RDD、DataFrame、Dataset的区别和各自的优势

2. SparkSQL 使用
SparkSQL, DataFrame, StructType, LongType, createOrReplaceTempView
1 | # Import types |
SparkSQL 一些网络链接
| No. | Title Author | Desc |
|---|---|---|
| 2. | Apache SparkSQL | Spark SQL Guide |
| 3. | SparkSQL | Spark2.x学习笔记:14、Spark SQL程序设计 |
| 4. | DataFrame | good 实际例子演示: Spark2.x学习笔记:14、Spark SQL程序设计 |
| 5. | DataFrame | DataFrame常用操作(DSL风格语法),sql风格语法 |
| 6. | SparkSQL | Spark SQL重点知识总结 |
| 7. | Create DataFrame | spark1.x:studentRDD.toDF / sqlContext.createDataFrame(studentRDD) / sqlContext.createDataFrame(rowRDD, schema) spark2.x:spark.read.format().load() |
SparkSQL 编写代码多种方式
1 | // This code works perfectly from Spark 2.x with Scala 2.11 |
Method 1:
Using SparkSession.createDataFrame(RDD obj).
1 | val dfWithoutSchema = spark.createDataFrame(rdd) |
Method 2:
Using SparkSession.createDataFrame(RDD obj) and specifying column names.
1 | val dfWithSchema = spark.createDataFrame(rdd).toDF("id", "vals") |
Method 3 (Actual answer to the question)
This way requires the input rdd should be of type RDD[Row].
1 | val rowsRdd: RDD[Row] = sc.parallelize( |
create the schema
1 | val schema = new StructType() |
Now apply both rowsRdd and schema to createDataFrame()
1 | val df = spark.createDataFrame(rowsRdd, schema) |
1 | spark-submit \ |
SparkSQL 的数据源操作: to load a json file
1 | df = spark.read.load("examples/src/main/resources/people.json", format="json") |
默认情况下保存数据到 HDFS 的数据格式: .snappy.parquet
.snappy: 结果保存到 HDFS 上的时候自动压缩: 压缩算法: snappy
.parquet: 结果使用一种列式文件存储格式保存
parquet / rc / orc / row column
1 | df = spark.read.load("examples/src/main/resources/users.parquet") |
举个🌰: spark 安装路径 examples/src/main/resources :
1 | # /usr/local/xsoft/spark/examples/src/main/resources [23:06:36] |
3. SparkSQL 调优
| No. | Title Author | Link |
|---|---|---|
| 0. | 华为开发者 SparkCore 知乎大数据 SparkSQL |
开发者指南 > 组件成功案例 > Spark > 案例10:Spark Core调优 > 经验总结 Spark基础:Spark SQL调优 1. Cache 缓存 1.1 spark.catalog.cacheTable(“t”) 或 df.cache() Spark SQL会把需要的列压缩后缓存,避免使用和GC的压力 1.2 spark.sql.inMemoryColumnarStorage.compressed 默认true 1.3 spark.sql.inMemoryColumnarStorage.batchSize 默认10000 控制列缓存时的数量,避免OOM风险。 引申要点: 行式存储 & 列式存储 优缺点 2. 其他配置 2.1 spark.sql.autoBroadcastJoinThreshold 2.2 spark.sql.shuffle.partitions 默认200,配置join和agg的时候的分区数 2.3 spark.sql.broadcastTimeout 默认300秒,广播join时广播等待的时间 2.4 spark.sql.files.maxPartitionBytes 默认128MB,单个分区读取的最大文件大小 2.5 spark.sql.files.openCostInBytes parquet.block.size 3. 广播 hash join - BHJ 3.1 当系统 spark.sql.autoBroadcastJoinThreshold 判断满足条件,会自动使用BHJ 华为云Stack全景图 > 开发者指南 > SQL和DataFrame调优 > Spark SQL join优化 spark不会注意spark不会确保每次选择广播表都是正确的,因为有的场景比如 full outer join 是不支持BHJ的。手动指定广播: broadcast(spark.table(“src”)).join(spark.table(“records”), “key”).show() |
| 1. | Spark学习技巧 | Spark SQL从入门到精通 Data Source: json, parquet, jdbc, orc, libsvm, csv, text, Hive 表 |
3. |
SparkSQL要懂的 |
Spark SQL在Spark集群中是如何执行的? 1. Spark SQL 转换为逻辑执行计划 2. Catalyst Optimizer组件,将逻辑执行计划转换为Optimized逻辑执行计划 3. 将Optimized逻辑执行计划转换为物理执行计划 4. Code Generation对物理执行计划进一步优化,将一些(非shuffle)操作串联在一起 5. 生成Job(DAG)由scheduler调度到spark executors中执行 逻辑执行计划和物理执行计划的区别? 1. 逻辑执行计划只是对SQL语句中以什么样的执行顺序做一个整体描述. 2. 物理执行计划包含具体什么操作. 例如:是BroadcastJoin、还是SortMergeJoin… |
| 4. | SparkSQL优化 | 1. spark.sql.codegen=false/true 每条查询的语句在运行时编译为java的二进制代码 2. spark.sql.inMemoryColumnStorage.compressed 默认false 内存列式存储压缩 3. spark.sql.inMemoryColumnStorage.batchSize = 1000 4. spark.sql.parquet.compressed.codec 默认snappy, (uncompressed/gzip/lzo) 5. spark.catalog.cacheTable(“tableName”) 或 dataFrame.cache() 6. --conf “spark.sql.autoBroadcastJoinThreshold = 50485760” 10 MB -> 50M 7. --conf “spark.sql.shuffle.partitions=200” -> 2000 |
| 5. | SparkSQL调优 | http://marsishandsome.github.io/SparkSQL-Internal/03-performance-turning/ 1. 对于数据倾斜,采用加入部分中间步骤,如聚合后cache,具体情况具体分析; 2. 适当的使用序化方案以及压缩方案; 3. 善于解决重点矛盾,多观察Stage中的Task,查看最耗时的Task,查找原因并改善; 4. 对于join操作,优先缓存较小的表; 5. 要多注意Stage的监控,多思考如何才能更多的Task使用PROCESS_LOCAL; 6. 要多注意Storage的监控,多思考如何才能Fraction cached的比例更多 |
1.1 基本操作
1 | val df = spark.read.json(“file:///opt/meitu/bigdata/src/main/data/people.json”) |
编码
1 | // spark2+, SparkSession |
使用 createOrReplaceTempView
1 | val df =spark.read.json("examples/src/main/resources/people.json") |
4. SparkSQL 运行过程
5. Catalyst
| No. | Link |
|---|---|
| 0. | 【大数据】SparkSql连接查询中的谓词下推处理(一) |
| 0. | 使用explain分析Spark SQL中的谓词下推,列裁剪,映射下推 |
| 1. | SparkSQL – 从0到1认识Catalyst(转载) 深入研究Spark SQL的Catalyst优化器(原创翻译) |
| 2. | Spark SQL Catalyst优化器 |
| 3. | 【数据库内核】基于规则优化之谓词下推 |
Reference
| No. | Link |
|---|---|
| 1. | W3C School - Spark RDD 操作 |
| 2. | W3C School - Spark RDD持久化 |
| 3. | W3C School - Spark SQL性能调优 |
- 记录一次spark sql的优化过程
- good - spark 内存溢出处理
- good - spark内存溢出及其解决方案
- SparkSQL解决数据倾斜实战介绍(适用于HiveSQL)
- 优化Spark中的数据倾斜
- spark十亿数据join优化
- Apache Spark 在eBay 的优化
- 字节跳动在Spark SQL上的核心优化实践 | 字节跳动技术沙龙
- Apache Spark源码走读之11 – sql的解析与执行
Checking if Disqus is accessible...