spark troubleshooting
Spark
| No. | Title | Desc |
|---|---|---|
| 1. | coalesce | 无论是在RDD中还是DataSet,默认情况下coalesce不会产生shuffle,此时通过coalesce创建的RDD分区数小于等于父RDD的分区数。 |
| 2. | repartition | 1)增加分区数 - repartition触发shuffle,shuffle的情况下可以增加分区数. - coalesce默认不触发shuffle,即调用该算子增加分区数,实际情况是分区数仍是当前的分区数. |
| 3. | union | val rdd4 = rdd1.union(rdd3) - res: Array[Int] = Array(1,2,3,4,5,6,7,8,9,12,14,16,18) 多数情况: 通过union生成的RDD的分区数为父RDD的分区数之和 |
| 4. | Join | join(otherDataset, [numTasks])是连接操作,将输入数据集(K,V)和另外一个数据集(K,W)进行Join, 得到(K, (V,W));该操作是对于相同K的V和W集合进行笛卡尔积 操作,也即V和W的所有组合 val rdd5 = rdd0.join(rdd0) res3: Array[(Char,(Int, Int))] = Array((d,(9,8)), (c,(6,6)), (c,(6,7))) rdd 算子: leftOuterJoin, fullOuterJoin, … spark sql 之join等函数用法 |
| 5. | cogroup | cogroup(otherDataset, [numTasks])是将输入数据集(K, V)和另外一个数据集(K, W)进行cogroup,得到一个格式为(K, Seq[V], Seq[W])的数据集 val rdd6 = rdd0.cogroup(rdd0) res: Array[(Int, (Iterable[Int], Iterable[Int]))] = Array((1,(ArrayBuffer(1, 2, 3),ArrayBuffer(1, 2, 3))), (2,(ArrayBuffer(1, 2, 3),ArrayBuffer(1, 2, 3)))) spark的union和join操作演示 |
| No. | Title Author | Link & Solutions |
|---|---|---|
| 0. | GROUPING SETS | spark.sql.files.maxPartitionBytes 默认128M, 单个分区读取的最大文件大小 (对于大部分的Parquet压缩表来说,注意压缩要可分割lzo,这个默认设置其实会导致性能问题) 可以通过设置spark.sql.files.maxPartitionBytes 来分割每个task 的输入 在Hadoop里,任务的并发默认是以hdfs block为单位的,而Spark里多了一种选择,即以RowGroup为基本单位: spark 处理parquet 文件时,一个row group 只能由一个task来处理 row group是需要调优的spark参数,重要一点,就是控制任务的并发度: set parquet.block.size=16M set spark.sql.files.maxPartitionBytes=16M |
| 1. | 较多的 DataFrame join 操作时 | 调大此参数:spark.sql.autoBroadcastJoinThreshold,默认10M,可设置为 100M |
| 2. | 华为开发者 SparkCore 知乎大数据 SparkSQL |
开发者指南 > 组件成功案例 > Spark > 案例10:Spark Core调优 > 经验总结 Spark基础:Spark SQL调优 1. Cache 缓存 1.1 spark.catalog.cacheTable(“t”) 或 df.cache() Spark SQL会把需要的列压缩后缓存,避免使用和GC的压力 1.2 spark.sql.inMemoryColumnarStorage.compressed 默认true 1.3 spark.sql.inMemoryColumnarStorage.batchSize 默认10000 控制列缓存时的数量,避免OOM风险。 引申要点: 行式存储 & 列式存储 优缺点 2. 其他配置 2.1 spark.sql.autoBroadcastJoinThreshold 2.2 spark.sql.shuffle.partitions 默认200,配置join和agg的时候的分区数 2.3 spark.sql.broadcastTimeout 默认300秒,广播join时广播等待的时间 2.4 spark.sql.files.maxPartitionBytes 默认128MB,单个分区读取的最大文件大小 2.5 spark.sql.files.openCostInBytes parquet.block.size 3. 广播 hash join - BHJ 3.1 当系统 spark.sql.autoBroadcastJoinThreshold 判断满足条件,会自动使用BHJ 华为云Stack全景图 > 开发者指南 > SQL和DataFrame调优 > Spark SQL join优化 spark不会注意spark不会确保每次选择广播表都是正确的,因为有的场景比如 full outer join 是不支持BHJ的。手动指定广播: broadcast(spark.table(“src”)).join(spark.table(“records”), “key”).show() |
开发小知识 |
||
| 0. | NULL, AVG/NOT IN | select avg(amount) as a_mount from orders amount (150, 150, null) avg = 150 不是 100 select * from stores where tag not in ("") |
| 1. | NVL(expr1,expr2) | NVL(expr1,expr2) NVL(UnitsOnOrder,0) other simlar: IFNULL(UnitsOnOrder, 0) / coalesce(null, “”) NULLIF(exp1,expr2)函数的作用是如果exp1和exp2相等则返回空(NULL) |
| 2. | IF( expr1 , expr2 , expr3 ) | expr1 的值为 TRUE,则返回值为 expr2 expr1 的值为FALSE,则返回值为 expr3 |
| 3. | IFNULL( expr1 , expr2 ) | if expr1 not null, return expr1 |
常见问题 |
||
| 3. | 定位性能问题对应的sql |
1. spark driver log 看 执行慢的stage(99%) 2. spark ui 上看 该stage 的task 执行完成比率 3. spark ui 上看 该stage 对应的 continer id 和 所属job 4. spark ui 上看 sql 的执行计划 和 执行计划图,最终定位到是哪段sql |
| 4. | 一道sql的题,一张表,用户id和登录日期,查找连续两天登陆的用户 | left join tb_log b on a.uid = b.uid on a.uid = b.uid |
| 5. | 写sql。求一个省份下的uv最高的城市 主要考察窗口函数 | select province,city,row_nnumber()over(partition by province order by uv desc ) rank |
| 6. | 数据不一致遇到过吗,是什么原因? | |
| 7. | 知道什么是 whole stage codengen吗 | 面向接口编程太耗时间,主要是方法递归调用,虚函数调用 可以将一个stage的所有task整理成一个方法,并且生成动态字节码 并结合 |
| 8. | spark 3.0 特性 | 待学 |
9. |
wordCount |
lines=sc.textFile(path) words = lines.flatMap(lambda x: x.split(’ ')) wco = words.map(lambda x: (x, 1)) word_count = wco.reduceByKey(add) |
1 | SELECT |
| No. | Title | Flag |
|---|---|---|
| 0. | kaike - sparkSQL底层实现原理 spark.sql.shuffle.partitions和 spark.default.parallelism 的区别 SparkSQL并行度参数设置方法 |
|
| 1. | B站 我爱喝假酒 - 性能调优 | |
| 2. | Spark性能调优之合理设置并行度 (稍有误), Spark实践 – 性能优化基础 | |
| 3. | spark.defalut.parallelism 默认是没有值的,如设置值为10,是在shuffle/窄依赖 的过程才会起作用(val rdd2 = rdd1.reduceByKey(_+_) //rdd2的分区数就是10,rdd1的分区数不受这个参数的影响) |
|
| 4. | 如果读取的数据在HDFS上,增加block数,默认情况下split与block是一对一的,而split又与RDD中的partition对应,所以增加了block数,也就提高了并行度 | |
| 5. | reduceByKey的算子指定partition的数量 val rdd2 = rdd1.reduceByKey(_+_,10) val rdd3 = rdd2.map.filter.reduceByKey(_+_) |
|
| 6. | val rdd3 = rdd1.join(rdd2) rdd3里面partiiton的数量是由父RDD中最多的partition数量来决定,因此使用join算子的时候,增加父RDD中partition的数量 | |
| 7. | 由于Spark SQL所在stage的 并行度无法手动设置 如果数据量较大,并且此stage中后续的transformation操作有着复杂的业务逻辑,而Spark SQL自动设置的task数量很少,这就意味着每个task要处理为数不少的数据量,然后还要执行非常复杂的处理逻辑,这就可能表现为第一个有Spark SQL的stage速度很慢,而后续的没有Spark SQL的stage运行速度非常快。 |
RDD 属性
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (block locations for an HDFS file)
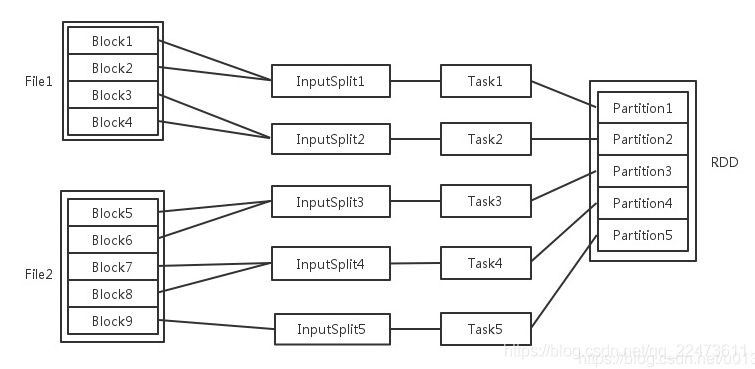
| No. | Title | Flag |
|---|---|---|
| 1. | 一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。 | ❎ |
| 2. | 一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。 | ❎ |
| 3. | RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。 | ❎ |
| 4. | 一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。 | ❎ |
| 5. | 一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置 | ❎ |
尽量保证每轮Stage里每个task处理的数据量>128M
Reference
- 数仓开发需要了解的5大SQL分析函数
- 干货:一文读懂数据仓库设计方案 |
- 使用Hive窗口函数替换union all处理分组汇总(小计,总计)
- Spark实践 – 性能优化基础
- Spark项目实战-troubleshooting之控制shuffle reduce端缓冲大小以避免OOM
- 结合源码谈谈 - 通过spark.default.parallelism谈Spark并行度
- 谈谈spark.sql.shuffle.partitions和 spark.default.parallelism 的区别及spark并行度的理解
Checking if Disqus is accessible...