Spark Summary 2 - Q&A
Spark
| No. | Title | Flag |
|---|---|---|
| 0. | kaike - sparkSQL底层实现原理 spark.sql.shuffle.partitions和 spark.default.parallelism 的区别 SparkSQL并行度参数设置方法 |
|
| 0. | SparkSql - 结构化数据处理 (上) | |
| 0. | Spark Container Executor task之间的关系 | |
| 0. | Spark 漫画 全面解释Spark企业调优点 | |
| 0 | Spark内核及调优 | |
| 1. | RDD 属性? 5大属性 | ❎ |
| 2. | 算子分为哪几类(RDD支持哪几种类型的操作) 1. Transformation (lazy模式)2. Action | ❎ |
| 3. | 创建rdd的几种方式 | ❎ |
| 4. | spark运行流程 | ❎ |
| 5. | Spark中coalesce与repartition的区别 | ❎ |
| 6. | sortBy 和 sortByKey的区别 | ❎ |
| 7. | map和mapPartitions的区别 sc.parallelize([1, 2, 3, 4]).mapPartitions(func).collect() |
❎ |
| 8. | 数据存入Redis 优先使用map mapPartitions foreach foreachPartions ? def f(x): print(x) sc.parallelize([1, 2, 3, 4, 5]).foreach(f) |
❎ |
| 9. | reduceByKey和groupBykey的区别 | ❎ |
| 10. | cache和checkPoint的比较 : 都是做 RDD 持久化的 | ❎ |
| 11. | 简述map和flatMap的区别和应用场景 map是对每个元素进行操做,flatmap是对每个元素操做后并压平. |
❎ |
| 12. | 计算曝光数和点击数 | |
| 13. | 分别列出几个常用的transformation和action算子 | ❎ |
| 17. | Spark应用执行有哪些模式,其中哪几种是集群模式 | ❎ |
| 18. | 请说明spark中广播变量的用途 ?(1)broadcast (不能改)(2)accumulator, sc.accumulator(0) 使用广播变量,每个 Executor 的内存中,只驻留一份变量副本,而不是对 每个 task 都传输一次大变量,省了很多的网络传输, 对性能提升具有很大帮助, 而且会通过高效的广播算法来减少传输代价. mapper = {'dog':1}, bc=sc.broadcast(mapper), bc.value: {'dog':1} mapper = {'pig': 3} , bc.unpersist(), sc.broadcast(mapper).value 2.2 rdd-programming-guide.html#broadcast-variables |
❎ |
| 20. | Spark高频考点: 写出你用过的spark中的算子,其中哪些会产生shuffle过程 1. reduceBykey 2. groupByKey 3. …ByKey |
❎ |
| 21. | good - Spark学习之路 (三)Spark之RDD 扎心了老铁 | ❎ |
| 22. | 请写出创建Dateset的几种方式 1. 常用的方式通过sparksession读取外部文件或者数据生成dataset 2. 通过调用createDataFrame生成Dataset df.select( "name").show()df.select(df[ 'name'], df['age'] + 1).show() df.filter(df[ 'age'] > 21).show() df.groupBy( "age").count().show() df.createOrReplaceTempView( "people") sqlDF = spark.sql( "SELECT * FROM people") sqlDF.show() teenNames = teenagers.rdd.map(lambda p: "Name: " + p.name).collect() |
❎ |
| 23. | 描述一下 RDD,DataFrame,DataSet 的区别? DataSet 结合了 RDD 和 DataFrame 的优势,并带来的一个新的概念 Encoder。 当序列化数据时,Encoder 产生字节码与 off-heap 进行交互,可以达到按需访问数据的效果,而不用反序列化整个对象。Spark 尚未提供自定义 Encoder 的 API,可是将来会加入 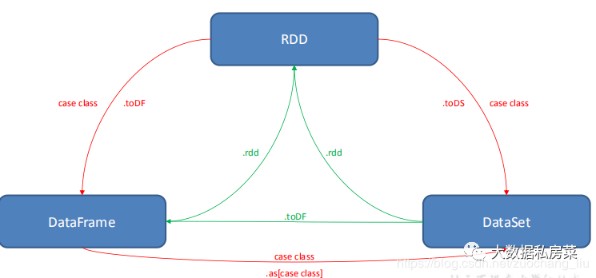 Apache spark DataFrame & Dataset |
❎ |
| 24. | 描述一下Spark中stage是如何划分的?描述一下shuffle的概念 | ✔️❎ |
| 25. | Spark 在yarn上运行需要做哪些关键的配置工作? 如何kill -个Spark在yarn运行中Application: yarn application -kill <appId> 但是这样会导致端口在一段时间(24小时)内被占用 |
❎ |
| 26. | 通常来说,Spark与MapReduce相比,Spark运行效率更高。请说明效率更高来源于Spark内置的哪些机制?并请列举常见spark的运行模式? | ❎ |
| 27. | RDD中的数据在哪? 不可变的意思是RDD中的每个分区数据是 only-read RDD要做逻辑分区(这里的分区类似hadoop中的逻辑切片split),每个分区可单独在集群节点计算 |
❎ |
| 28. | 如果对RDD进行cache操作后,数据在哪里? 1. 执行cache算子时数据会被加载到各个Executor进程的内存. 2. 第二次使用 会直接从内存中读取而不会区磁盘. |
❎ |
| 29. | Spark中Partition的数量由什么决定? 答: 和MR一样,但是Spark默认最少有两个分区. | ❎ |
| 30. | ❎ | |
| 35. | ❎ | |
| 36. | Spark SQL 在 Spark Core 的基础上针对结构化数据处理进行很多优化和改进. | ❎ |
| 37. | 简述宽依赖和窄依赖概念,groupByKey,reduceByKey,map,filter,union五种操作 | ❎ |
| 38. | 数据倾斜可能会导致哪些问题,如何监控和排查,在设计之初,要考虑哪些来避免 | ❎ |
| 39. | 简述宽依赖和窄依赖概念,groupByKey,reduceByKey,map,filter,union五种操作. | ❎ |
| 41. | 有一千万条短信,有重复,以文本文件的形式保存,一行一条数据,请用五分钟时间,找出重复出现最多的前10条 | |
| 42. | 现有一文件,格式如下,请用spark统计每个单词出现的次数 | ❎ |
| 45. | 特别大的数据,怎么发送到excutor中? Answ: broadcast | ❎ |
| 46. | spark调优都做过哪些方面? 要非常具体的场景 | ❎ |
| 47. | spark任务为什么会被yarn kill掉? | ❎ |
| 48. | Spark on Yarn作业执行流程?yarn-client和yarn-cluster有什么区别? | ❎ |
| 49. | spark中的cache() persist() checkpoint()之间的区别 1. checkpoint 的 RDD 会被计算两次 2. rdd.persist(StorageLevel.DISK_ONLY), partition 由 blockManager 管理, blockManager stop, cache 到磁盘上 RDD 也会被清空 3. checkpoint 将 RDD 持久化到 HDFS 或本地文件夹, 可以被下一个 driver program 使用. |
❎ |
| 50. | spark算子调优四:repartition解决SparkSQL低并行度问题 你自己通过spark.default.parallelism参数指定的并行度,只会在没有spark sql的stage中生效 hive表,对应了一个hdfs文件,有20个block;你自己设置了spark.default.parallelish参数为100;你的第一个stage的并行度,是不受你设置的参数控制的,就只有20task |
|
| 51. | very good 多弗朗明哥 -【大数据】Spark性能优化和故障处理 算子调优三:filter与coalesce的配合使用 算子调优四:repartition解决SparkSQL低并行度问题 算子调优五:reduceByKey本地聚合 |
1 | # Register the DataFrame as a SQL temporary view |
1. RDD 属性
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (block locations for an HDFS file)
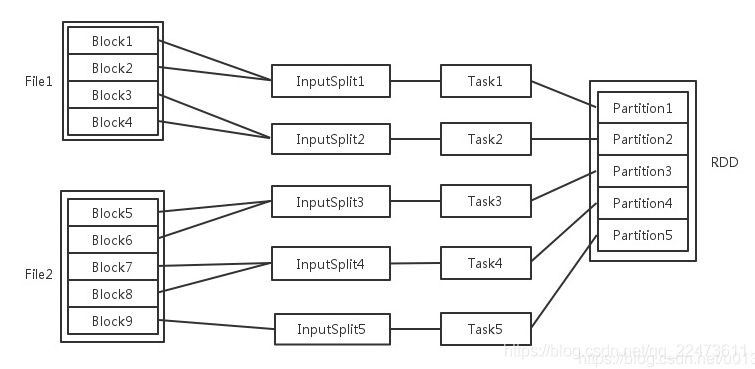
| No. | Title | Flag |
|---|---|---|
| 1. | 一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。 | ❎ |
| 2. | 一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。 | ❎ |
| 3. | RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。 | ❎ |
| 4. | 一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。 | ❎ |
| 5. | 一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置 | ❎ |
尽量保证每轮Stage里每个task处理的数据量>128M
2. RDD支持的操作
| No. | Title | Flag |
|---|---|---|
| 1. | Transformation: 现有的RDD通过转换生成一个新的RDD。lazy模式,延迟执行。 map,filter,flatMap,groupByKey,reduceByKey,aggregateByKey,union,join, coalesce. |
❎ |
| 2. | Action: 在RDD上运行计算,并返回结果给驱动程序(Driver)或写入文件系统. reduce,collect,count,first,take,countByKey 及 foreach 等等. |
❎ |
| 说明 | collect 该方法把数据收集到driver端 Array数组类型, transformation只有遇到action才能被执行. | ❎ |
当执行action之后,数据类型不再是rdd了,数据就会存储到指定文件系统中,或者直接打印结 果或者收集起来.
3. 创建rdd的几种方式
1.集合并行化创建(有数据)
1 | val arr = Array(1,2,3,4,5) |
2.读取外部文件系统,如hdfs,或者读取本地文件(最常用的方式)(没数据)
1 | val rdd2 = sc.textFile("hdfs://hdp-01:9000/words.txt") |
3.从父RDD转换成新的子RDD
调用Transformation类的方法,生成新的RDD
5. coalesce, repartition区别
- repartition 底层调用的就是 coalesce 方法:
coalesce(numPartitions, shuffle = true)- repartition 一定会发生 shuffle,coalesce 根据传入的参数来判断是否发生 shuffle
一般情况下增大 rdd 的 partition 数量使用 repartition,减少 partition 数量时使用coalesce
6. sortBy / sortByKey区别
sortBy既可以作用于RDD[K] ,还可以作用于RDD[(k,v)]
sortByKey 只能作用于 RDD[K,V] 类型上
sortBy : sortBy(lambda x:x[2],ascending = False)
1 | #任务:有一批学生信息表格,包括name,age,score, 找出score排名前3的学生, score相同可以任取 |
sortByKey : sortByKey().map(lambda x:x[0])
1 | #任务:按从小到大排序并返回序号, 大小相同的序号可以不同 |
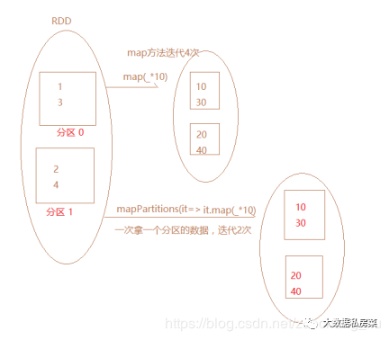
7. map和mapPartitions的区别
8. 数据存入Redis 优先使用什么算子?
foreachPartions
- map
- mapPartitions
- foreach
- foreachPartions
1 | from pyspark import SparkFiles |
使用 foreachPartions
- map mapPartitions 是转换类的算子, 有返回值
- 写mysql,redis 的链接
1 | # foreach(f)[source] |
9. reduceByKey和groupBykey区别
reduceByKey会传一个聚合函数, 至关于 groupByKey + mapValues
reduceByKey 会有一个分区内聚合,而groupByKey没有 最核心的区别
结论:reduceByKey有分区内聚合,更高效,优先选择使用reduceByKey
10. cache和checkPoint的比较
都是作 RDD 持久化的
1.缓存,是在触发action以后,把数据写入到内存或者磁盘中。不会截断血缘关系
(设置缓存级别为memory_only:内存不足,只会部分缓存或者没有缓存,缓存会丢失,memory_and_disk :内存不足,会使用磁盘)
2.checkpoint 也是在触发action以后,执行任务。单独再启动一个job,负责写入数据到hdfs中。(把rdd中的数据,以二进制文本的方式写入到hdfs中,有几个分区,就有几个二进制文件)
3.某一个RDD被checkpoint以后,他的父依赖关系会被删除,血缘关系被截断,该RDD转换成了CheckPointRDD,之后再对该rdd的全部操做,都是从hdfs中的checkpoint的具体目录来读取数据。缓存以后,rdd的依赖关系仍是存在的。
checkpoint
- sc.setCheckpointDir("/Users/xulijie/Documents/data/checkpoint")
- val pairs = sc.parallelize(data, 3)
- pairs.checkpoint
Cache
Cache(): 运算时间很长或运算量太大才能得到的 RDD,computing chain 过长或依赖其他 RDD 很多的 RDD.
df2.cache()
rdd2.cache()
cache 机制是每计算出一个要 cache 的 partition 就直接将其 cache 到内存了。但 checkpoint 没有使用这种第一次计算得到就存储的方法,而是等到 job 结束后另外启动专门的 job 去完成 checkpoint 。 也就是说需要 checkpoint 的 RDD 会被计算两次。因此,在使用 rdd.checkpoint() 的时候,建议加上 rdd.cache(), 这样第二次运行的 job 就不用再去计算该 rdd 了,直接读取 cache 写磁盘。
Hadoop vs Spark 区别
Spark比MapReduce运行速度快的原因主要有以下几点:
- task启动时间比较快,Spark是fork出线程;而MR是启动一个新的进程;
- 更快的shuffles,Spark只有在shuffle的时候才会将数据放在磁盘,而MR却不是。
- 更快的工作流:典型的MR工作流是由很多MR作业组成的,他们之间的数据交互需要把数据持久化到磁盘才可以;而Spark支持DAG以及pipelining,在没有遇到shuffle完全可以不把数据缓存到磁盘。
缓存:虽然目前HDFS也支持缓存,但是一般来说,Spark的缓存功能更加高效,特别是在SparkSQL中,我们可以将数据以列式的形式储存在内存中。- 所有的这些原因才使得Spark相比Hadoop拥有更好的性能表现;在比较短的作业确实能快上100倍,但是在真实的生产环境下,一般只会快 2.5x ~ 3x!
JVM 的优化: Hadoop 每次 MapReduce 操作,启动一个 Task 便会启动一次 JVM,基于进程的操作。而 Spark 每次 MapReduce 操作是基于线程的,
Spark 只在启动 Executor 是启动一次 JVM,内存的 Task 操作是在线程复用的。每次启动 JVM 的时间可能就需要几秒甚至十几秒,那么当 Task 多了,这个时间 Hadoop 不知道比 Spark 慢了多。
Reference
- very good 多弗朗明哥 -【大数据】Spark性能优化和故障处理
- good - Spark分区 partition 详解
- good - 2020大数据/数仓/数开面试题真题总结(附答案)
- 2020大数据/数仓/数开面试题真题总结(附答案)
- spark中的cache() persist() checkpoint()之间的区别
- airflow的使用方法
other:
Checking if Disqus is accessible...