Spark Summary 1 - Basic knowledge
1 | ./bin/spark-submit \ |
尽量保证每轮Stage里每个task处理的数据量>128M
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (block locations for an HDFS file)
DataFrame和DataSet可以相互转化,df.as[ElementType]这样可以把DataFrame转化为DataSet,ds.toDF()这样可以把DataSet转化为DataFrame
DataSet可以在编译时检查类型, DataSet以Catalyst逻辑执行计划表示,并且数据以编码的二进制形式被存储,不需要反序列化就可以执行sorting、shuffle等操作。
Spark SQL是Spark最新和技术最为复杂的组件之一。它支持SQL查询和新的DataFrame API。Spark SQL的核心是Catalyst优化器,它以一种新颖的方式利用高级编程语言特性(例如Scala的模式匹配和quasiquotes)来构建可扩展查询优化器。
repartition vs coalesce vs coalesce in sql
Spark算子:RDD基本转换操作(2)–coalesce、repartition
一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce
| No. | Title | Article |
|---|---|---|
| 0. | Hive杀招 | 再次分享!Hive调优,数据工程师成神之路 |
| 0 | HadoopReview杀招 | Hadoop高频考点,正在刷新你的认知! |
| 0. | Apache Parquet和Apache Avro | |
| 0. | RDD是分布式的Java对象的集合 DataFrame是分布式的Row对象的集合 |
RDD、DataFrame和DataSet的区别 persist、cache和checkpoint的区别与联系 |
| 3. | Data Warehouse | 2020 大数据/数仓/数开 Interview Questions |
| 4. | Spark RDD | very good Spark原理篇之RDD特征分析讲解 |
| 5. | Spark Task | Spark中Task数量的分析 |
| 6. | Spark 腾讯总结 | Spark 腾讯计算机组总结(一) |
| 7. | 大数据学习指南 | Github 大数据学习指南 |
| Spark性能优化指南 | ||
| 1. | dev | Spark性能优化指南——基础篇 |
| 2. | shuffle | Spark性能优化指南——高级篇(8) |
| 3. | Spark 1.6 后引入统一内存管理 | Apache Spark 内存管理详解 |
蓦然大数据开发 More Info 请点击
| No. | Title | Article |
|---|---|---|
| 蓦然大数据开发 | ||
| 1. | 蓦然大数据开发 | 知乎, 公众号:旧时光大数据 |
| 2. | 蓦然大数据开发 | 大数据Hadoop(三)——MapReduce |
| 1. | Spark | 大数据Spark题(一) |
| 2. | Spark | 大数据Spark题(二) |
| 3. | Spark | 大数据Spark题(三) |
| 4. | Spark | 大数据Spark题(四) |
| 5. | Spark | 大数据Spark题(五)— 几种常见的数据倾斜情况及调优方式 |
| 6. | Spark | 大数据Spark题(六)— Shuffle配置调优 |
| 7. | Spark | 大数据Spark题(七)— 程序开发调优 |
| 8. | Spark | 大数据Spark题(八)— 运行资源调优 |
Spark 创建RDD、DataFrame各种情况的默认分区数
1). reduceByKey(func, numPartitions=None), Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合
2). groupByKey(numPartitions=None), 不能自定义函数,我们需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作
spark的执行模型的方式,它的特点无非就是多个任务之间数据通信不需要借助硬盘而是通过内存,大大提高了程序的执行效率。而hadoop由于本身的模型特点,多个任务之间数据通信是必须借助硬盘落地的。那么spark的特点就是数据交互不会走硬盘。只能说多个任务的数据交互不走硬盘,但是spark的shuffle过程和hadoop一样仍然必须走硬盘的。
所谓Shuffle不过是把处理流程切分,给切分的上一段(我们称为Stage M)加个存储到磁盘的Action动作,把切分的下一段(Stage M+1)数据源变成Stage M存储的磁盘文件。每个Stage都可以走我上面的描述,让每条数据都可以被N个嵌套的函数处理,最后通过用户指定的动作进行存储。
我们做Cache/Persist意味着什么?
其实就是给某个Stage加上了一个saveAsMemoryBlockFile的动作,然后下次再要数据的时候,就不用算了。这些存在内存的数据就表示了某个RDD处理后的结果。这个才是说为啥Spark是内存计算引擎的地方。在MR里,你是要放到HDFS里的,但
Spark允许你把中间结果放内存里。所以结论是:Spark并不是基于内存的技术!它其实是一种可以有效地使用内存LRU策略的技术
Spark只有在shuffle的时候才会将数据放在磁盘,而MR却不是
0. Top Questions
1. spark的优化怎么做? (☆☆☆☆☆)
spark调优比较复杂,但是大体可以分为三个方面来进行
| No. | Title | Answer |
|---|---|---|
| 1 | Platform | 提高数据的本地性,选择高效的存储格式如parquet |
| 2 | Application | 处理 Data Skew,复用RDD进行缓存,作业并行化执行等等 |
| 3 | JVM 层面 | 启用高效的序列化方法如kyro,增大off head内存等等 |
Lineage, cognitive ability
2. Spark性能优化指南—高级篇(8) (☆☆☆☆☆)
Data Skew 发生的原理
Data Skew 的原理很简单:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生 Data Skew。
| No. | Spark性能优化指南—高级篇(8) | 优缺点 | Flag |
|---|---|---|---|
3. |
提高shuffle操作的并行度 |
reduceByKey(1000) rdd: spark.default.parallelismSQL: spark.sql.shuffle.partitions,shuffle task 默200 总结:实现起来简单,可以缓解和减轻 Data Skew 的影响 |
❎ |
| 4. | 两阶段聚合(局部聚合+全局聚合) |
随机前缀=>原1个Task的数据,现分多Task, 后去掉前缀, 在全局聚合 仅仅适用于聚合类的shuffle操作,适用范围相对较窄 |
❎ |
| 5. | 将reduce join转为map join | 这个方案只适用1个大表和1个小表情况。需将小表进行广播 | good |
| 6. | 采样倾斜key并分拆join操作 | 如果导致倾斜的key特别多的话,,那么这种方式也不适合 | ✔️ |
| 7. | 使用随机前缀和扩容RDD进行join | 该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。 而且需要对整个RDD进行扩容,对内存资源要求很高 |
✔️ |
| No. | 调优概述 |
|---|---|
| 1. | 大多数Spark作业的性能主要就是消耗在shuffle环节,因为包含了大量的磁盘IO、序列化、网络数据传输等操作。 影响一个Spark作业性能的因素,主要还是 代码开发、资源参数以及数据倾斜,shuffle调优只能在整个Spark的性能调优中占到一小部分而已。 |
| 2. | shuffle相关参数调优 |
将reduce join转为map join:
1 | // 首先将数据量比较小的RDD的数据,collect到Driver中来。 |
3. RDD的弹性表现在哪几点?(☆☆☆☆☆)
1)自动的进行内存和磁盘的存储切换;
2)基于Lineage的高效容错;
3)task如果失败会自动进行特定次数的重试;
4)stage如果失败会自动进行特定次数的重试,而且只会计算失败的分片;
5)checkpoint和persist,数据计算之后持久化缓存;
6)数据调度弹性,DAG TASK调度和资源无关;
7)数据分片的高度弹性。
4. Spark 开发调优 (☆☆☆☆☆)
| No. | Spark性能优化指南基础篇(8) | 优缺点 |
|---|---|---|
| 1 ~ 3: 重复利用一个RDD | 重复利用一个RDD | |
| (1). | 避免创建重复 RDD | |
| (2). | 尽可能复用同一个 RDD | |
| (3). | 对多次使用的 RDD 进行持久化 | |
| 4 ~ 6: 提高任务处理的性能 | 提高任务处理的性能 | |
(4). |
尽量避免使用 shuffle 类算子 |
Spark作业运行过程中,最消耗性能的地方就是shuffle过程 shuffle过程中,各个节点上的相同key都会先写入本地磁盘文件中,然后其他节点需要通过网络传输拉取各个节点上的磁盘文件中的相同key |
| (5). | 使用 map-side 预聚合的 shuffle 操作 是在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combiner; |
map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了 减少了磁盘IO以及网络传输开销 |
| (6). | 使用高性能算子 | reduceByKey/aggregateByKey替代groupByKey 使用mapPartitions替代普通map |
| (7). | 广播大变量 (减轻网络负担) | |
(8). |
使用 Kryo 优化序列化性能 |
1. 在算子函数中用到外部变量,该变量会序列化后网络传输 2. RDD泛型类型时,所有自定义类型对象,都会进行序列化 3. 使用可序列化的持久化策略时 Kryo要求最好要注册所有需要进行序列化的自定义类型 |
| (9). | 优化数据结构 |
总结: 如果说有某一个 RDD 会在一个程序中被多次使用,那么就应该不要重复创建,要多次使用这一个RDD (不可变的),既然要重复利用一个RDD,就应该把这个 RDD 进行持久化. (最好在内存中)
cache persist 持久化数据到磁盘或内存 unpersist
如何把持久化到磁盘或内存中的数据给删除掉呢?
1. Spark 基础 (2)
1). spark的有几种部署模式,每种模式特点?
1). local 【启动1~k个executor]】
2). standalone 【分布式部署集群,自带完整的服务,资源管理和任务监控是Spark自己监控】
3). Spark on yarn (yarn-cluster和yarn-client)
Spark on yarn模式
- 分布式部署集群,资源和任务监控交给yarn管理
- 粗粒度资源分配方式,包含cluster和client运行模式
- cluster 适合生产,driver运行在集群子节点,具有容错功能
- client 适合调试,dirver运行在客户端
2). spark有5个组件 (5)
- master:管理集群和节点,不参与计算。
- worker:计算节点,进程本身不参与计算,和master汇报。
- Driver:运行程序的main方法,创建spark context对象。
- sparkContext:控制整个application的生命周期,包括dagsheduler和task scheduler等组件。
- client:用户提交程序的入口。
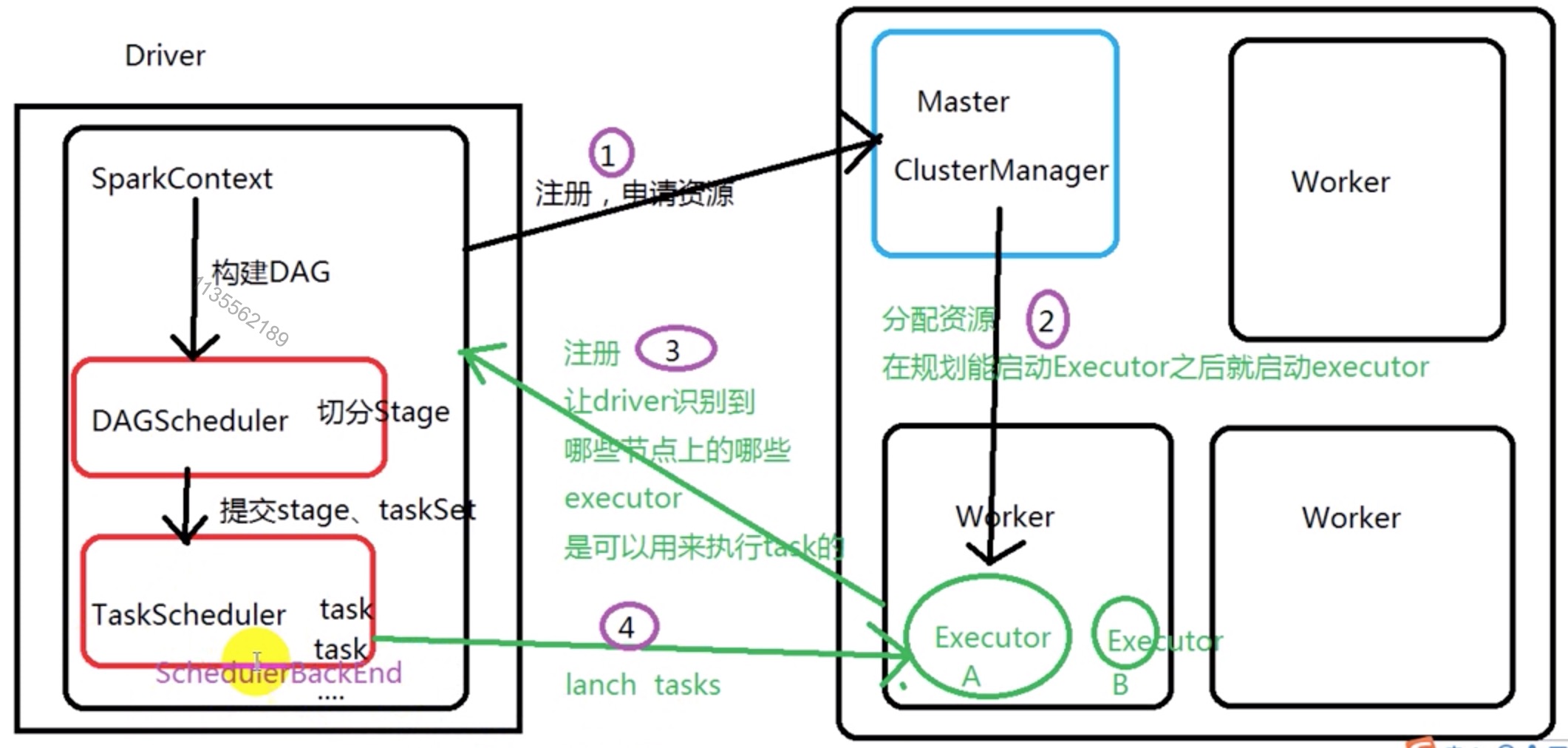
2. Spark运行细节 (13)
| No. | Topic | Flag |
|---|---|---|
| 1. | spark工作机制 ? 【 client端提交作业后->Drive,main,SparkContext->DAG...】 |
|
| 2. | Spark应用程序的执行过程 | |
| 3. | driver的功能是什么? 【作业主进程,有main函数,且有SparkContext的实例】 |
|
| 4. | Spark中worker的主要工作是什么? [ 管理当前节点内存,CPU使用状况, worker就类似于包工头,管理分配新进程] |
|
| 5. | task有几种类型?2种 【resultTask 和 shuffleMapTask类型,除了最后一个task都是】 |
|
| 6. | 什么是shuffle,以及为什么需要shuffle? 【某种具有共同特征的数据汇聚到一个计算节点上进行计算】 |
|
| 7. | Spark master HA 主从切换过程不会影响集群已有的作业运行,为什么? 【因为程序在运行之前,已经申请过资源了,driver和Executors通讯,不需要和master进行通讯的】 |
|
| 8. | Spark并行度怎么设置比较合适 【spark并行度,每个core承载2~4个partition(并行度)】 |
|
| 9. | Spark程序执行,有时候默认为什么会产生很多task,怎么修改默认task执行个数? | |
| 10. | Spark中数据的位置是被谁管理的? 【每个数据分片都对应具体物理位置,数据的位置是被blockManager管理】 |
|
| 11. | 为什么要进行序列化? 【减少存储空间,高效存储和传输数据,缺点:使用时需要反序列化,非常消耗CPU】 |
|
| 12. | Spark如何处理不能被序列化的对象? 【封装成object】 |
2.1 spark工作机制
- 用户在client端提交作业后,会由Driver运行main方法并创建 sparkContext
- 执行add算子,形成dag图输入dagscheduler , (创建job,划分Stage,提交Stage)
- 按照add之间的依赖关系划分stage输入task scheduler
- task scheduler会将stage划分为taskset分发到各个节点的executor中执行
2.2 Spark应用程序的执行过程
1 . 构建Spark Application的运行环境(启动SparkContext)
2 . SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
3 . 资源管理器分配Executor资源,Executor运行情况将随着心跳发送到资源管理器上;
YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
4 . SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler
5 . Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行,SparkContext将应用程序代码发放给Executor。
6 . Task在Executor上运行,运行完毕释放所有资源
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。
Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。
task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。
一个stage的所有task都执行完毕之后,会在
各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
stage的划分
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。
因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
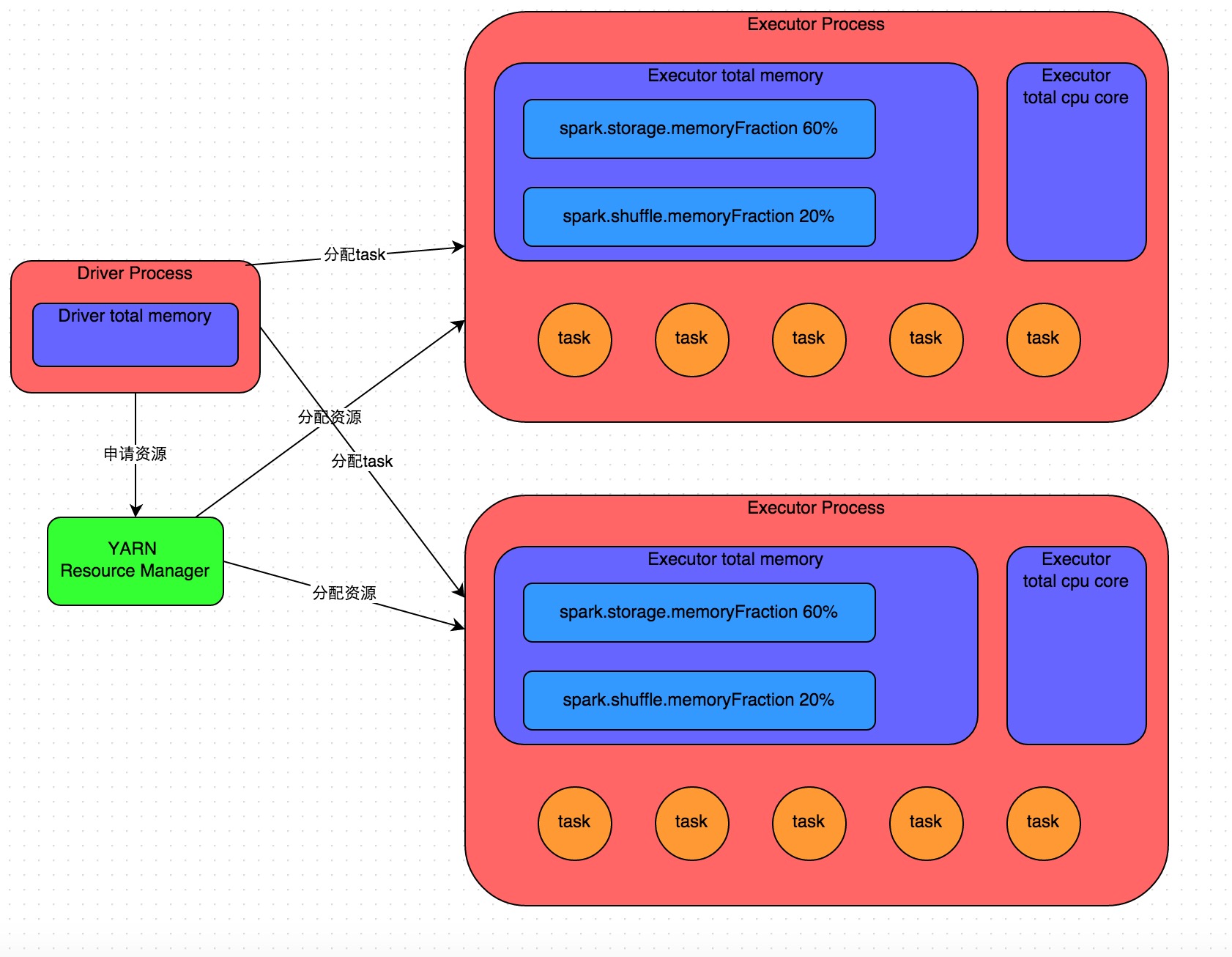
| No. | Executor的内存主要分为三块 |
|---|---|
| 1. | 第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%; |
| 2. | 第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%; |
| 3. | 第三块是让RDD持久化时使用,默认占Executor总内存的60%。 |
1 | ./bin/spark-submit \ |
2.3 driver的功能是什么?
Spark作业运行时包括一个Driver进程,也是作业主进程,有main函数,且有SparkContext的实例,是程序入口点;
功能:
- 向集群申请资源
- 负责了作业的调度和解析
- 生成Stage并调度Task到Executor上(包括DAGScheduler,TaskScheduler)
2.4 Spark中Worker工作是什么?
- 管理当前节点内存,CPU使用状况,接收master分配过来的资源指令,通过ExecutorRunner启动程序分配任务
- worker就类似于包工头,管理分配新进程,做计算的服务,相当于process服务
- worker不会运行代码,具体运行的是Executor是可以运行具体appliaction写的业务逻辑代码
Process 进程
2.4 Spark 程序执行,有时候默认为什么会产生很多task,怎么修改默认task执行个数?
- 有很多小文件的时候,有多少个输入block就会有多少个task启动
- spark中有partition,每个partition都会对应一个task,task越多,在处理大规模数据的时候,就会越有效率
3. Spark 与 Hadoop 比较(7)
- Mapreduce和Spark的相同和区别
- 简答说一下hadoop的mapreduce编程模型
- 简单说一下hadoop和spark的shuffle相同和差异?
- 简单说一下hadoop和spark的shuffle过程
- partition和block的关联
- Spark为什么比mapreduce快?
- Mapreduce操作的mapper和reducer阶段相当于spark中的哪几个算子?
相当于spark中的map算子和reduceByKey算子,区别:MR会自动进行排序的,spark要看具体partitioner
3.1 MR和Spark相同和区别
spark用户提交的任务:application
一个application对应一个SparkContext,app中存在多个job
1). 每触发一次action会产生一个
job-> 这些job可以并行或串行执行2). 每个job有多个
stage,stage是shuffle过程中DAGSchaduler通过RDD之间的依赖关系划分job而来的3). 每个stage里面有多个
task,组成 taskset 有TaskSchaduler分发到各个executor执行4).
executor生命周期和app一样的,即使没有job运行也存在,所以task可以快速启动读取内存进行计算.
3.2 mapreduce 编程模型
- map task会从本地文件系统读取数据,转换成key-value形式的键值对集合
- key-value,集合,input to mapper进行业务处理过程,将其转换成需要的key-> value在输出
- 之后会进行一个partition分区操作,默认使用的是hashpartitioner
- 之后会对key进行进行sort排序,grouping分组操作将相同key的value合并分组输出
- 之后进行一个combiner归约操作,其实就是一个本地的reduce预处理,以减小后面shufle和reducer的工作量
- reduce task会通过网络将各个数据收集进行reduce处理
- 最后将数据保存或者显示,结束整个job
3.3 mr/spark 的 shuffle 差异?
high-level 角度:
- 两者并没有大的差别 都是将 mapper(Spark: ShuffleMapTask)的输出进行 partition,
- 不同的 partition 送到不同的 reducer(Spark 里 reducer 可能是下一个 stage 里的 ShuffleMapTask,也可能是 ResultTask)
- Reducer 以内存作缓冲区,边 shuffle 边 aggregate 数据,等到数据 aggregate 好以后进行 reduce().
low-level 角度:
Hadoop MapReduce 是 sort-based,进入 combine() 和 reduce() 的 records 必须先 sort.
好处:combine/reduce() 可以处理大规模的数据, 因为其输入数据可以通过外排得到
(1) mapper 对每段数据先做排序
(2) reducer 的 shuffle 对排好序的每段数据做 归并 merge
Spark 默认选择的是 hash-based,通常使用 HashMap 来对 shuffle 来的数据进行 aggregate,不提前排序
如果用户需要经过排序的数据:sortByKey()
实现角度:
- Hadoop MapReduce 将处理流程划分出明显的几个阶段:map(), spilt, merge, shuffle, sort, reduce()
- Spark 没有这样功能明确的阶段,只有不同的 stage 和一系列的 transformation(),spill, merge, aggregate 等操作需要蕴含在 transformation() 中
3.4 MR/Spark 的 shuffle 过程
| Tech | description |
|---|---|
| hadoop | map端保存分片数据,通过网络收集到reduce端 |
| spark | spark的shuffle是在DAGSchedular划分Stage的时候产生的,TaskSchedule要分发Stage到各个worker的executor,减少shuffle可以提高性能 |
3.5 partition 和 block 的关联
hdfs 中的 block 是分布式存储的最小单元,等分,可设置冗余,这样设计有一部分磁盘空间的浪费,但是整齐的 block大小,便于快速找到、读取对应的内容
Spark中的partition是RDD的最小单元,RDD是由分布在各个节点上的partition组成的.
partition是指的spark在计算过程中,生成的数据在计算空间内最小单元.
同一份数据(RDD)的partion大小不一,数量不定,是根据application里的算子和最初读入的数据分块数量决定
| block/partition | description |
|---|---|
| block | 位于存储空间, block的大小是固定的 |
| partition | 位于计算空间, partion大小是不固定的 |
4. Spark RDD(4)
4.1 RDD机制
- 分布式弹性数据集,简单的理解成一种数据结构,是spark框架上的通用货币
- 所有算子都是基于rdd来执行的
- rdd执行过程中会形成dag图,然后形成lineage保证容错性等
- 从物理的角度来看rdd存储的是block和node之间的映射
4.2 RDD的弹性表现在哪几点?
- 自动的进行内存和磁盘的存储切换;
- 基于Lingage的高效容错;
- task如果失败会自动进行特定次数的重试;
- stage如果失败会自动进行特定次数的重试,而且只会计算失败的分片;
- checkpoint和persist,数据计算之后持久化缓存
- 数据调度弹性,DAG TASK调度和资源无关
- 数据分片的高度弹性,a.分片很多碎片可以合并成大的,b.par
4.3 RDD有哪些缺陷?
- 不支持细粒度的写和更新操作(如网络爬虫)
- spark写数据是粗粒度的,所谓粗粒度,就是批量写入数据 (批量写)
- 但是读数据是细粒度的也就是说可以一条条的读 (一条条读)
- 不支持增量迭代计算,Flink支持
4.4 什么是RDD宽依赖和窄依赖?
RDD和它依赖的parent RDD(s)的关系有两种不同的类型
- 窄依赖:每一个parent RDD的Partition最多被子RDD的一个Partition使用 (一父一子)
- 宽依赖:多个子RDD的Partition会依赖同一个parent RDD的Partition (一父多子)
5. RDD操作(13)
5.1 cache和pesist的区别
.cache() == .persist(MEMORY_ONLY)
5.2 cache后面能不能接其他算子,它是不是action操作?
可以接其他算子,但是接了算子之后,起不到缓存应有的效果,因为会重新触发cache
cache不是action操作
5.3 什么场景下要进行persist操作?
spark所有复杂一点的算法都会有persist身影,spark默认数据放在内存,spark很多内容都是放在内存的,非常适合高速迭代,1000个步骤 只有第一个输入数据,中间不产生临时数据,但分布式系统风险很高,所以容易出错,就要容错,rdd出错或者分片可以根据血统算出来,如果没有对父rdd进行persist 或cache的化,就要重头做。
| No. | 以下场景会使用persist | Article |
|---|---|---|
| 1) | 某个步骤计算非常耗时,需要进行persist持久化 ; | |
| 2) | 计算链条非常长,重新恢复要算很多步骤,很好使,persist ; | |
| 3) | checkpoint所在的rdd要持久化persist, lazy级别,框架发现有checnkpoint,checkpoint时单独触发一个job,需要重算一遍,checkpoint前 要持久化,写个rdd.cache或者rdd.persist,将结果保存起来,再写checkpoint操作,这样执行起来会非常快,不需要重新计算rdd链条了。checkpoint之前一定会进行persist; sc.setCheckpointDir(“hdfs://lijie:9000/checkpoint0727”) rdd.cache() rdd.checkpoint() |
|
| 4) | shuffle之后为什么要persist,shuffle要进性网络传输,风险很大,数据丢失重来,恢复代价很大 ; | |
| 5) | shuffle之前进行persist,框架默认将数据持久化到磁盘,这个是框架自动做的。 |
5.4 rdd有几种操作类型?三种!
- transformation,rdd由一种转为另一种rdd
- action
- cronroller,控制算子(cache/persist) 对性能和效率的有很好的支持
5.5 collect功能是什么,其底层是怎么实现的?
driver通过collect把集群中各个节点的内容收集过来汇总成结果
collect返回结果是Array类型的,合并后Array中只有一个元素,是tuple类型(KV类型的)的。
5.6 map与flatMap的区别
map:对RDD每个元素转换,文件中的每一行数据返回一个数组对象
flatMap:对RDD每个元素转换,然后再扁平化,将所有的对象合并为一个对象,会抛弃值为null的值
5.8 列举你常用的action?
collect,reduce,take,count,saveAsTextFile等
5.10 Spark累加器有哪些特点?
全局的,只增不减,记录全局集群的唯一状态
在exe中修改它,在driver读取
executor级别共享的,广播变量是task级别的共享
两个application不可以共享累加器,但是同一个app不同的job可以共享
5.11 spark hashParitioner的弊端
分区原理:对于给定的key,计算其hashCode
弊端是数据不均匀,容易导致数据倾斜
5.12 RangePartitioner分区的原理
尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,也就是说一个分区中的元素肯定都是比另一个分区内的元素小或者大
分区内的元素是不能保证顺序的
简单的说就是将一定范围内的数映射到某一个分区内
5.13 Spark中的HashShufle的有哪些不足?
shuffle产生海量的小文件在磁盘上,此时会产生大量耗时的、低效的IO操作;
容易导致内存不够用,由于内存需要保存海量的文件操作句柄和临时缓存信息
容易出现数据倾斜,导致OOM
5. Spark 大数据问题(7)
| No. | Title |
|---|---|
| 1. | 如何使用Spark解决TopN问题? |
| 2. | 如何使用Spark解决分组排序问题? lines.groupByKey(), values.toList.sortWith |
| 3. | 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url? Solution: 划分小文件 Hash & Bloomfilter |
| 4. | 有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M,要求返回频数最高的100个词 (1). hash(x)%5000 5000个小文件 (2). 统计每个小文件词频 |
| 5. | 现有海量日志数据保存在一个超级大的文件中,该文件无法直接读入内存,要求从中提取某天出访问百度次数最多的那个IP 分而治之+Hash, Hash(IP)%1024 |
| 6. | 在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数 方案1:采用2-Bitmap 方案2:划分小文件,在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素 |
| 7. | 腾讯面试题:给40亿个不重复的unsignedint的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中? 申请512M的内存,一个bit位代表一个unsignedint值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在 |
Hive数仓建表该选用ORC还是Parquet,压缩选LZO还是Snappy?
「所以在实际生产中,使用Parquet存储,lzo压缩的方式更为常见,这种情况下可以避免由于读取不可分割大文件引发的数据倾斜。 但是,如果数据量并不大(预测不会有超大文件,若干G以上)的情况下,使用ORC存储,snappy压缩的效率还是非常高的。」
Reference
Spark算子:RDD基本转换操作(2)–coalesce、repartition
- Spark知识点汇总
- Spark总结(一) 知乎
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark常用算子
- 《Spark快速大数据分析》RDD操作总结
- Spark常见面试问题有哪些?
- Spark学习痛点和路线图
- Spark面试题(一)
- 每个 Spark 工程师都应该知道的五种 Join 策略
Checking if Disqus is accessible...