Spark Tutorials 2 - SparkContext、Stage、Executor、RDD

1. Spark - SparkContext
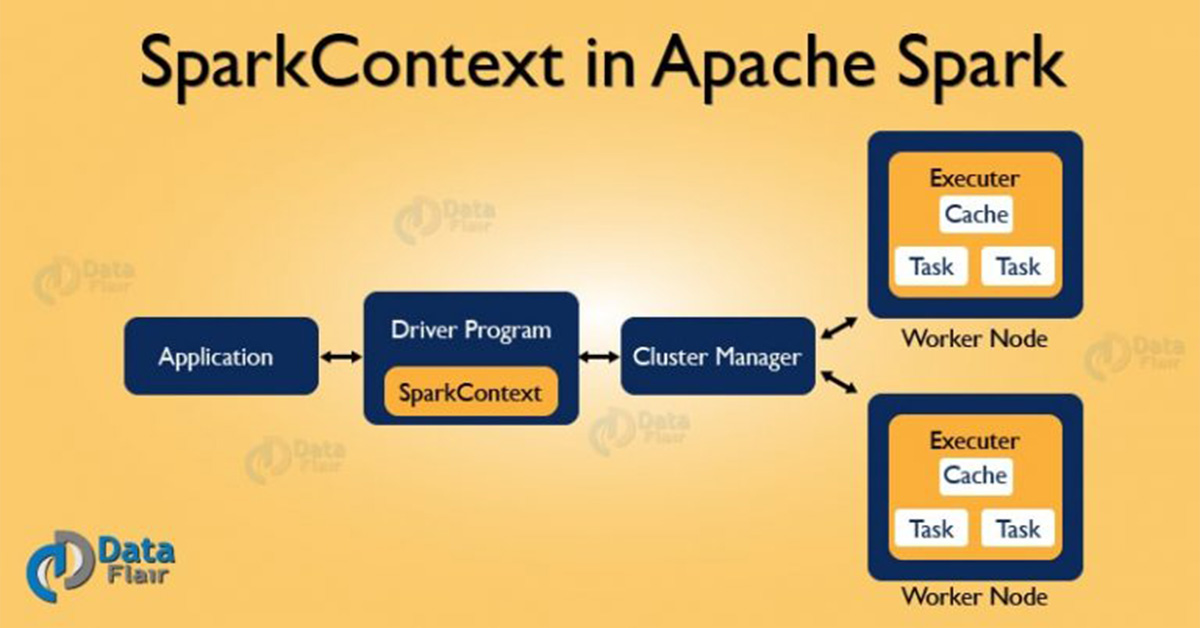
SparkContext allows your Spark Application to access Spark Cluster with the help of Resource Manager. The resource manager can be one of these three- Spark Standalone, YARN, Apache Mesos.
The different contexts in which it can run are local, yarn-client, Mesos URL and Spark URL.
1.1 SparkContext Functions

1.2 SparkContext Conclusion
Hence, SparkContext provides the various functions in Spark like get the current status of Spark Application, set the configuration, cancel a job, Cancel a stage and much more. It is an entry point to the Spark functionality. Thus, it acts a backbone.
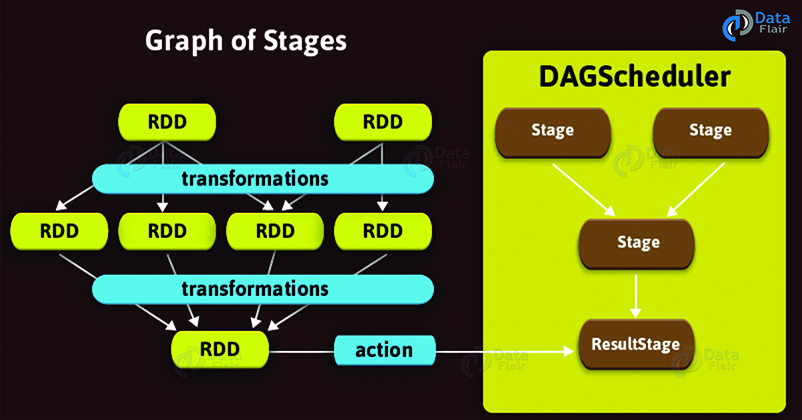
2. Spark - Stage
Spark Stage- An Introduction to Physical Execution plan
- ShuffleMapstage
- ResultStage
2.1 What are Stages in Spark?
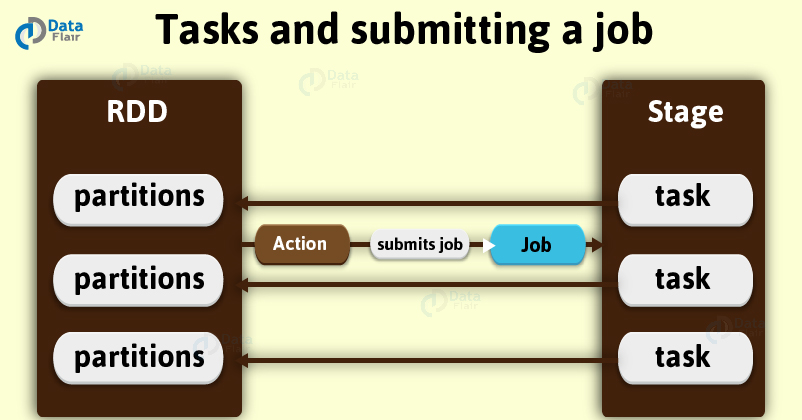
with the boundary of a stage in spark marked by shuffle dependencies.
Ultimately, submission of Spark stage triggers the execution of a series of dependent parent stages. Although, there is a first Job Id present at every stage that is the id of the job which submits stage in Spark.
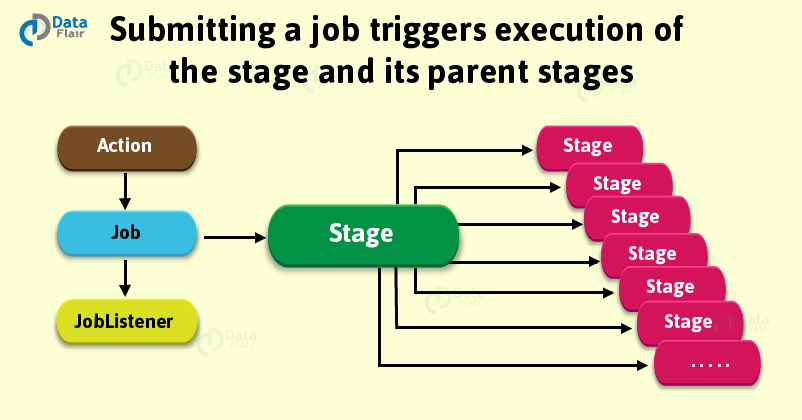
2.2 ShuffleMapStage
- ShuffleMapStage in Spark
- ResultStage in Spark

2.3 ResultStage
ResultStage implies as a final stage in a job that applies a function on one or many partitions of the target RDD in Spark. It also helps for computation of the result of an action.
3. Spark - Executor
Apache Spark Executor for Executing Spark Tasks
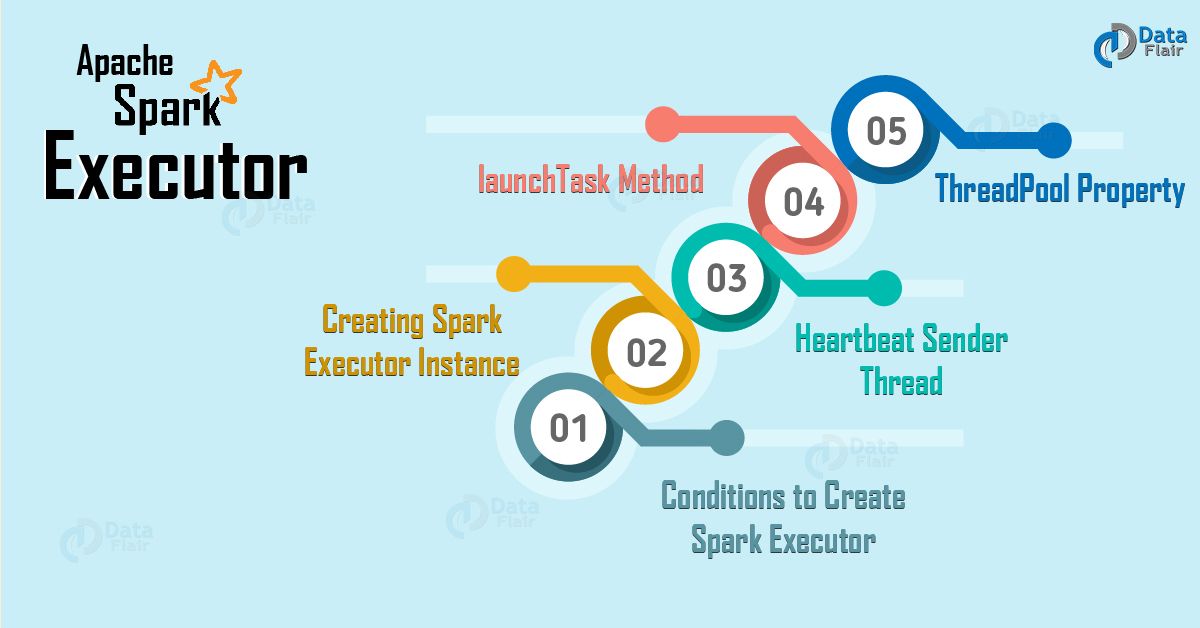
3.1 Spark Executor
Some conditions in which we create Executor in Spark is:
- When CoarseGrainedExecutorBackend receives RegisteredExecutor message. Only for Spark Standalone and YARN.
- When LocalEndpoint is created for local mode.
n. 端点;[化]滴定终点
3.2 Creating Executor Instance
By using the following, we can create the Spark Executor:
- From Executor ID.
- By using SparkEnv we can access the local MetricsSystem as well as BlockManager. Moreover, we can also access the local serializer by it.
- From Executor’s hostname.
- To add to tasks’ classpath, a collection of user-defined JARs. By default, it is empty.
- By flag whether it runs in local or cluster mode (disabled by default, i.e. cluster is preferred)
Moreover, when creation is successful, the one INFO messages pop up in the logs. That is:
INFO Executor: Starting executor ID [executorId] on host [executorHostname]
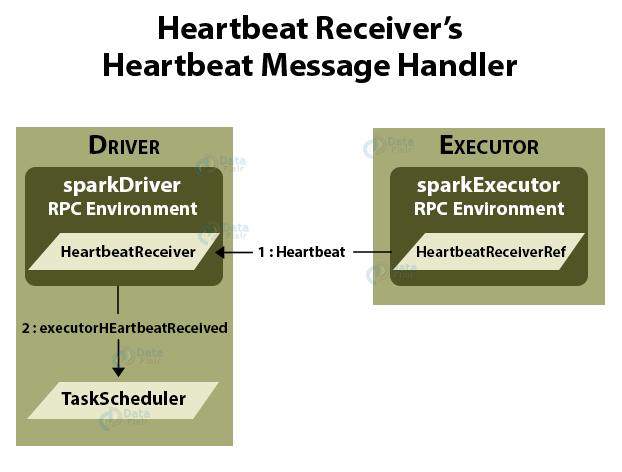
3.3 Heartbeat Sender Thread
Basically, with a single thread, heartbeater is a daemon ScheduledThreadPoolExecutor.
We call this thread pool a driver-heartbeater.
3.4 Launching Task Method
3.5 executor.taskLaunch.worker
Thread Pool — ThreadPool Property
3.6 Conclusion
we have also learned how Spark Executors are helpful for executing tasks. The major advantage we have learned is, we can have as many executors we want. Therefore, Executors helps to enhance the Spark performance of the system.
4. Spark - RDD
Spark RDD – Introduction, Features & Operations of RDD
4.1 resilient distributed dataset
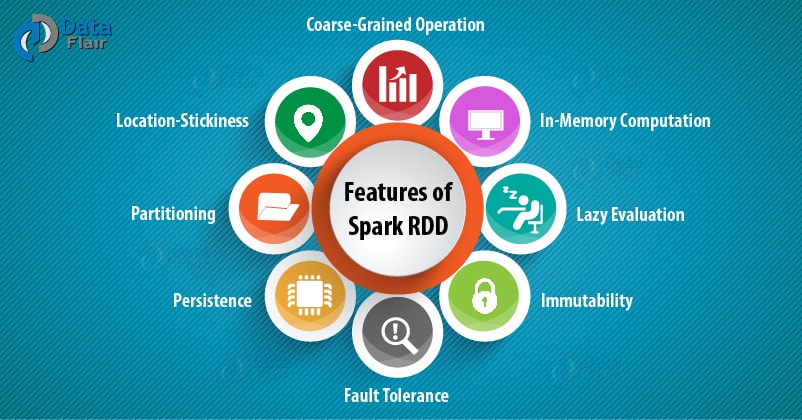
- Resilient, i.e. fault-tolerant with the help of RDD lineage graph(DAG) and so able to recompute missing or damaged partitions due to node failures.
- Distributed, since Data resides on multiple nodes.
- Dataset represents records of the data you work with. The user can load the data set externally which can be either JSON file, CSV file, text file or database via JDBC with no specific data structure.

4.2 Why need RDD in Spark?
Apache Spark evaluates RDDs lazily. It is called when needed, which saves lots of time and improves efficiency. The first time they are used in an action so that it can pipeline the transformation. Also, the programmer can call a persist method to state which RDD they want to use in future operations.
4.3 Features of Spark RDD
5. Spark RDD Operations
- Transformation
- Actions
5.1 Transformations
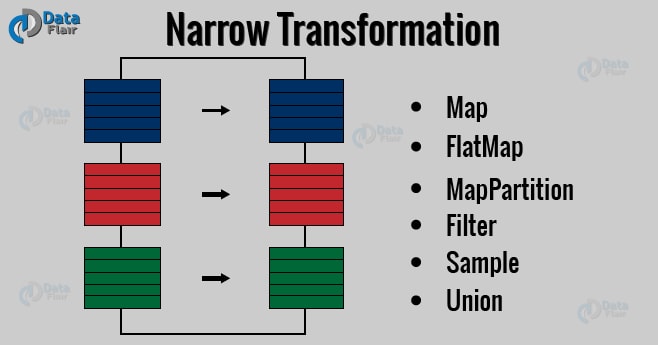
a. Narrow Transformations
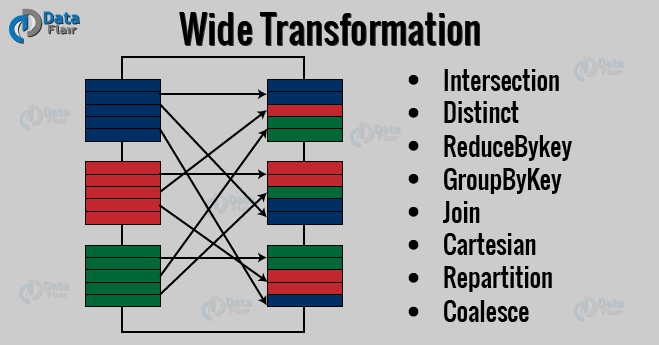
b. Wide Transformations
5.2 Actions
An Action in Spark returns final result of RDD computations. It triggers execution using lineage graph to load the data into original RDD.
Conclusion – Spark RDD
Because of the above-stated limitations of RDD to make spark more versatile DataFrame and Dataset evolved.
6. Limitation of Spark RDD
Reference
- data-flair.training/blogs
- Spark RDD Operations-Transformation & Action with Example
- Spark RDD常用算子学习笔记详解(python版)
- Spark常用的Transformation算子的简单例子
Checking if Disqus is accessible...