Spark Shuffle Optimize 10 items
调优:
- 开发调优
- 资源调优
- DataSkew
- shuffle
今天的内容:
(1)Spark Task 执行过程详细梳理
(2)DataSkew 发生时的现象和原因分析
(3)DataSkew 原理分析
(4)DataSkew 适用场景分析
(5)DataSkew solution 优缺点分析
(6)DataSkew solution 实践经验分享
Preface
1). 哪个是 窄依赖 ? B (计算之前之后 2个 RDD 记录是 1对1)
A、join
B、filter map foreach
C、sort
D、group
2). 关于广播变量 ? BCD (在Driver声明的,用来序列化到每个Executor中供Task使用)
B、read-only
C、存储在各个节点 (从节点:Worker负责启动和管理 Executor)
D、能存储在磁盘或HDFS (默认是存储在内存里面,[存储内存 执行内存])
3). Spark 为什么比 MapReducer 快? ABC
A、基于内存计算,减少低效的磁盘交互
B、高效的调度算法, 基于 DAG
C、容错机制 Linage,精华部分就是 DAG 和 Linage
DAG引擎! == mapreduce spark 能够把中间结果放到内存里面
spark 官方宣称: SPark hadoop 0.9:100 迭代计算 做一次 3:1
Distributed Computing
分布式计算,不怕数据量大,就怕 DataSkew
Shuffle 调优 10点 (DataSkew Solution)
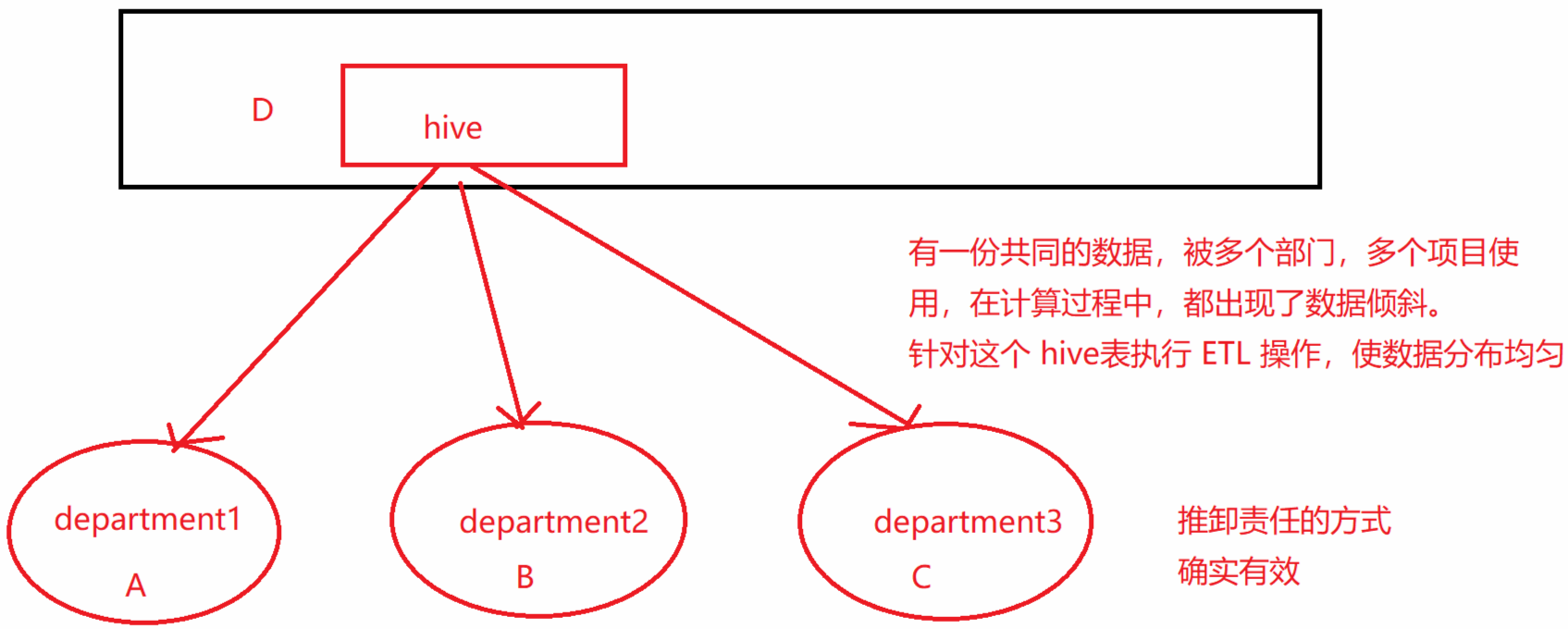
1. 使用Hive ETL预处理数据
导致 DataSkew 的是 Hive 表。如果该 Hive 表中的数据本身很不均匀(比如某个 key 对应了 100 万数据,其他 key 才对应了 10 条数据),而业务场景需要频繁用 Spark 对 Hive 表执行某个分析操作,那么比较适合使用这种技术方案:
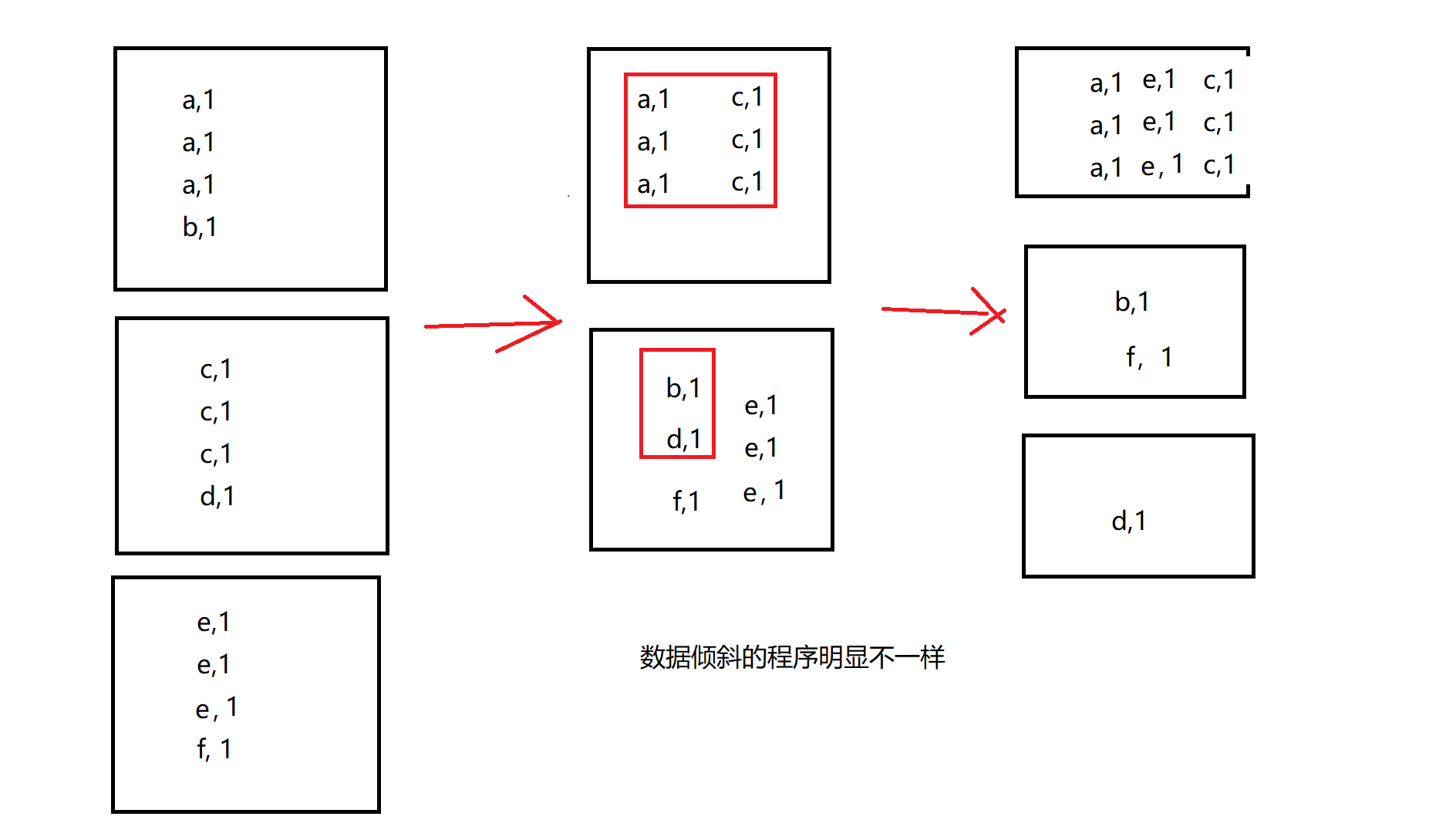
2. 调整shuffle操作的并行度
碰运气做法: 原来的并行度导致了倾斜,调整并行度, 如果是自定义的分区规则决定必须是n个分区,n个Task
依然使用默认的HasPartitoiner,那么这种碰运气的方案是有用的
大量不同的Key被分配到了相同的Task造成该Task数据量过大。
如果我们必须要对数据倾斜迎难而上,那么建议优先使用这种方案,因为这是处理数据倾斜最简单的一 种方案。但是也是一种属于 碰运气的方案。因为这种方案,并不能让你一定解决数据倾斜,甚至有可能 加重。那当然,总归,你会调整到一个合适的并行度是能解决的。前提是这种方案适用于 Hash散列的 分区方式。凑巧的是,各种分布式计算引擎,比如MapReduce,Spark 等默认都是使用 Hash散列的方 式来进行数据分区。
Spark 在做 Shuffle 时,默认使用 HashPartitioner(非Hash Shuffle)对数据进行分区。如果并行度设 置的不合适,可能造成大量不相同的 Key 对应的数据被分配到了同一个 Task 上,造成该 Task 所处理的 数据远大于其它 Task,从而造成 DataSkew。
如果调整 Shuffle 时的并行度,使得原本被分配到同一 Task 的不同 Key 发配到不同 Task 上处理,则可 降低原 Task 所需处理的数据量,从而缓解 DataSkew 造成的短板效应。
2.5. 企业最佳实践
该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100万, 那么无论你的task数量增加到多少,这个对应着100万数据的key肯定还是会分配到一个task中去处理, 因此注定还是会发生数据倾斜的。所以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝 试去用嘴简单的方法缓解数据倾斜而已,或者是和其他方案结合起来使用。
如果之前的额并行度是12,现在调整成为 18 有用么?并没有多大的改善 10个 11个 13
不要拥有一样的公约数, (特别是最大公约数)
3. 过滤少数导致倾斜的key
无用数据直接过滤。 产生数据倾斜是由于部分无效数据导致的。把这部分无效数据过滤掉即可!
1 | 你们的大宽表:有些字段的值:null department |
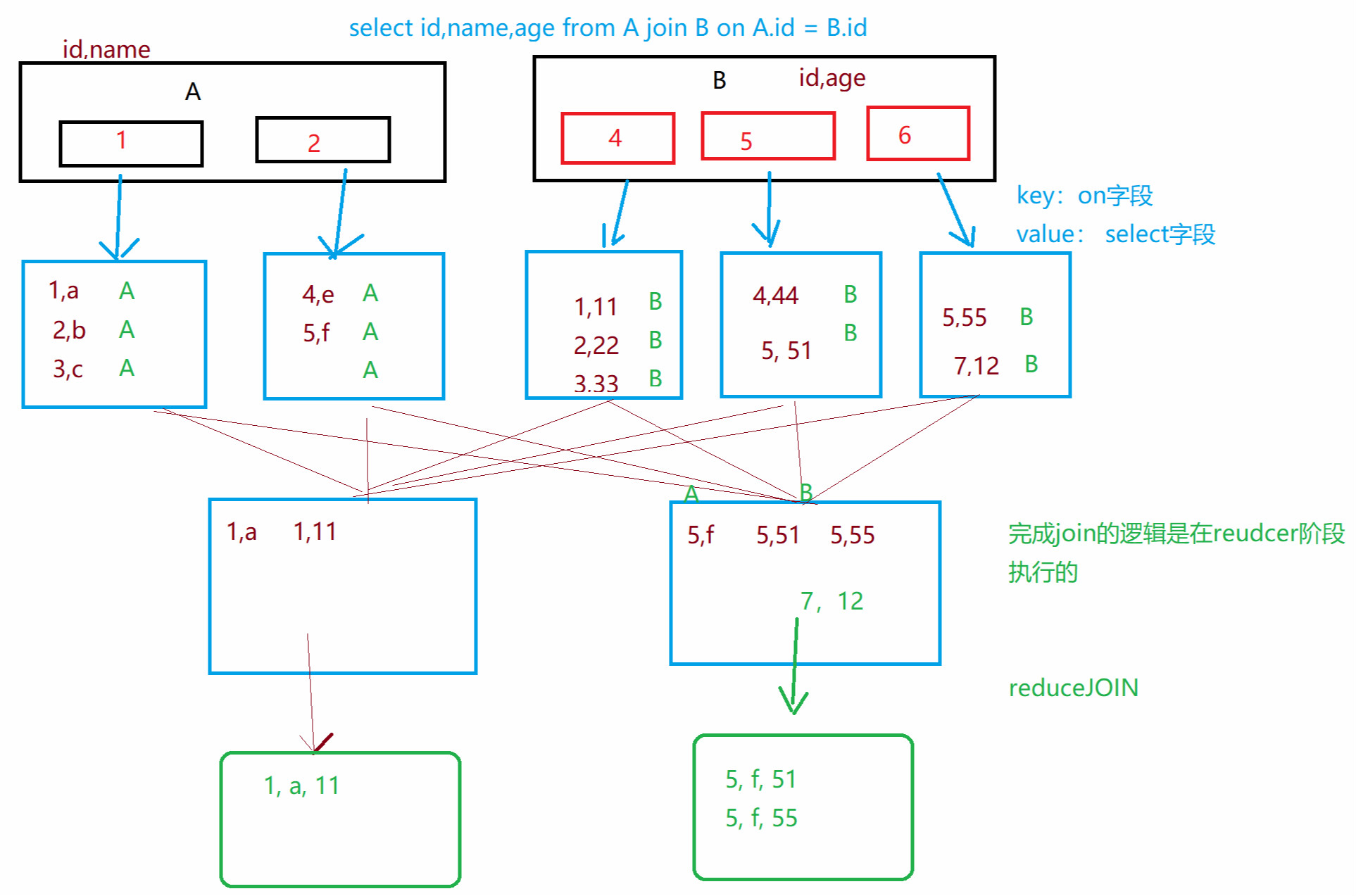
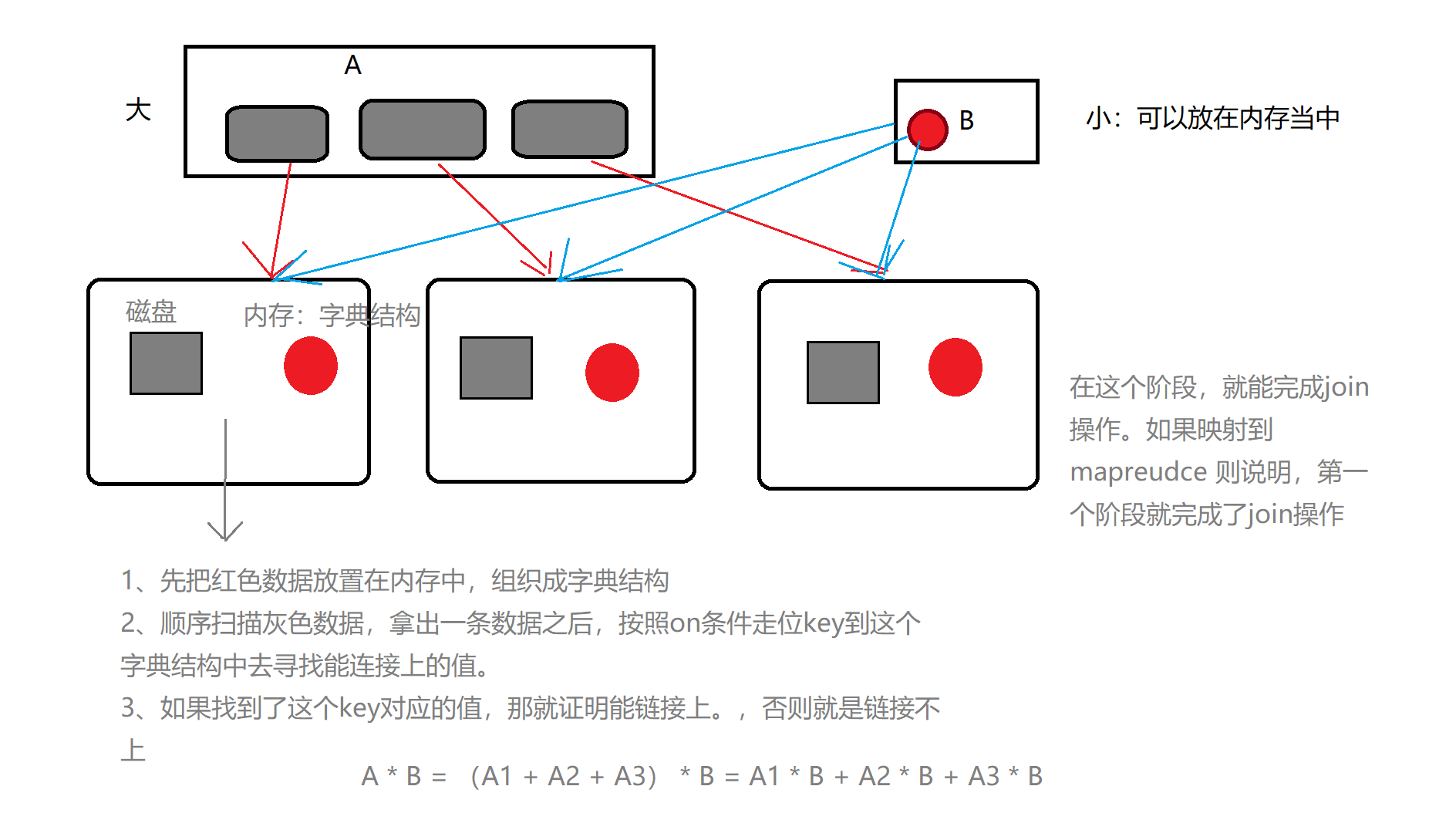
4. 将reduce join转为map join
大小表做连接, mapjoin
spark中如何实现 mapjoin 的逻辑呢? 使用 spark的广播机制!
就是可以把小表数据当做广播变量,使用广播机制,把该变量数据,广播到所有的executor里面去。
reduceJoin:
mapJoin:
5. 采样倾斜 key 并分拆 join 操作
现在假设一个数据倾斜场景中的数据分为两种:
一种是导致倾斜的数据集合: 单独处理
一种是不导致倾斜的数据集合: 单独处理
最后把结果合起来!
6. 两阶段聚合(局部聚合+全局聚合)
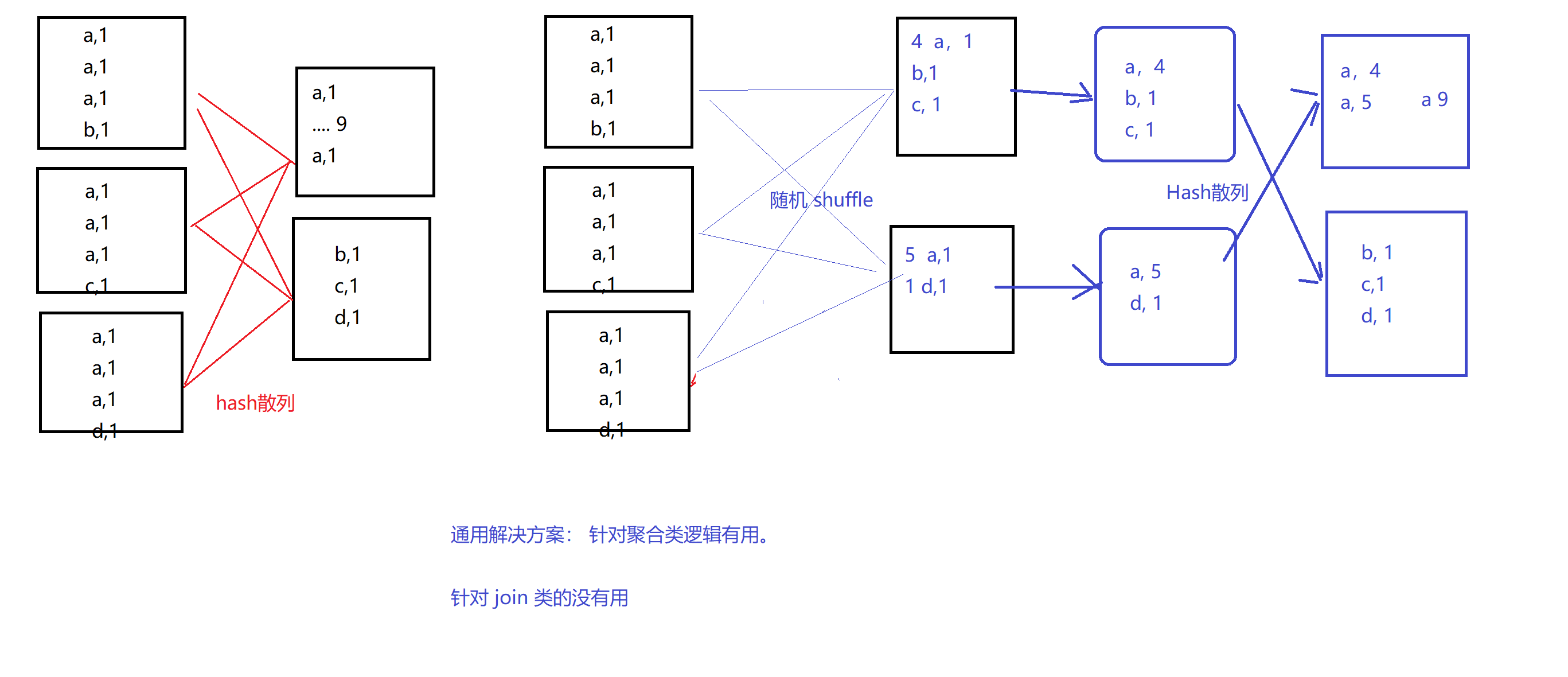
方案六: 两阶段聚合 (聚合类逻辑的通用解决方案) 纵向切分
原来:一次hash散列导致倾斜
现在:一次随机shuffle + 一次hash散列
7. 使用随机前缀和扩容 RDD 进行 join
方案七: 增加随机字段/链接字段 + 扩容RDD
表A 表B
RDD1 rdd2
两种场景:
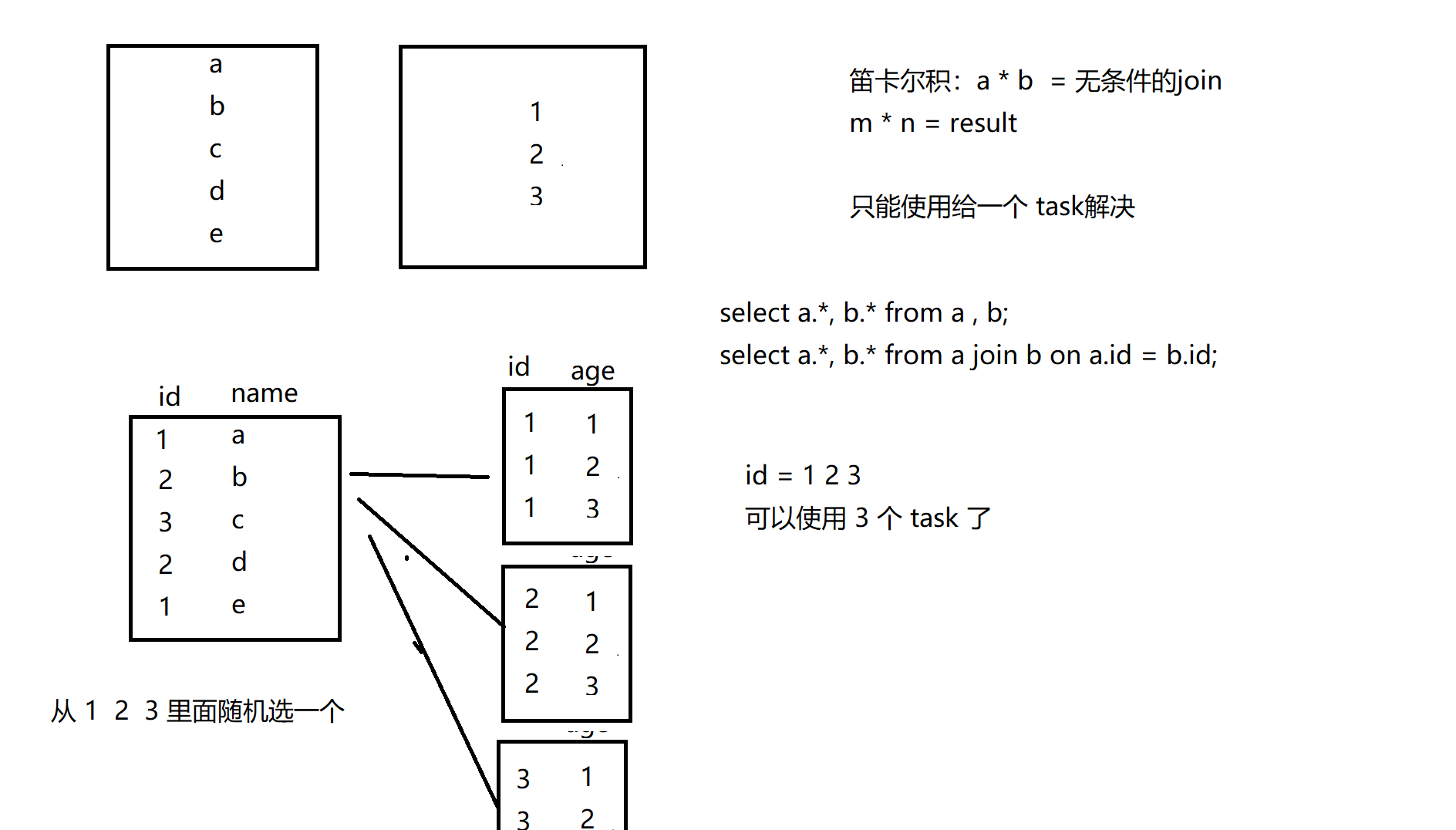
1、如果 两张表做笛卡尔积
2、如果两张表做join,并且导致数据倾斜的某些key比较多。
拆分出来单独处理(依然可能有数据倾斜 ==> 加随机前缀)
如果是导致倾斜的key只有一个,这个key的数据量非常。 加随机前缀 复制
1、笛卡尔积
2、导致倾斜的key的数据;量特别大。 不能使用单个task解决
8. 任务横切,一分为二,单独处理
9. 多种方案组合使用
10. 自定义 Partitioner
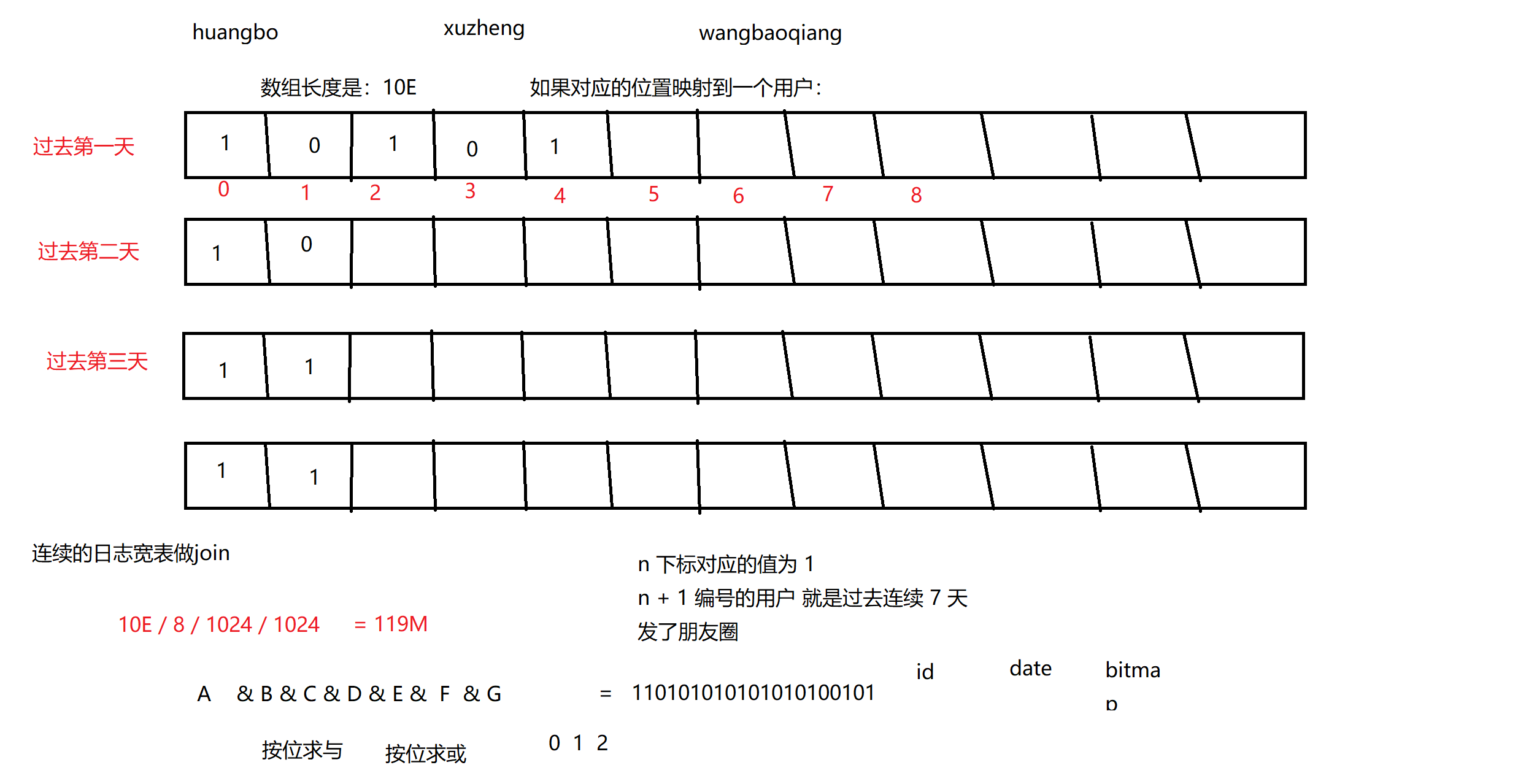
11. bitmap 求 Join
Checking if Disqus is accessible...