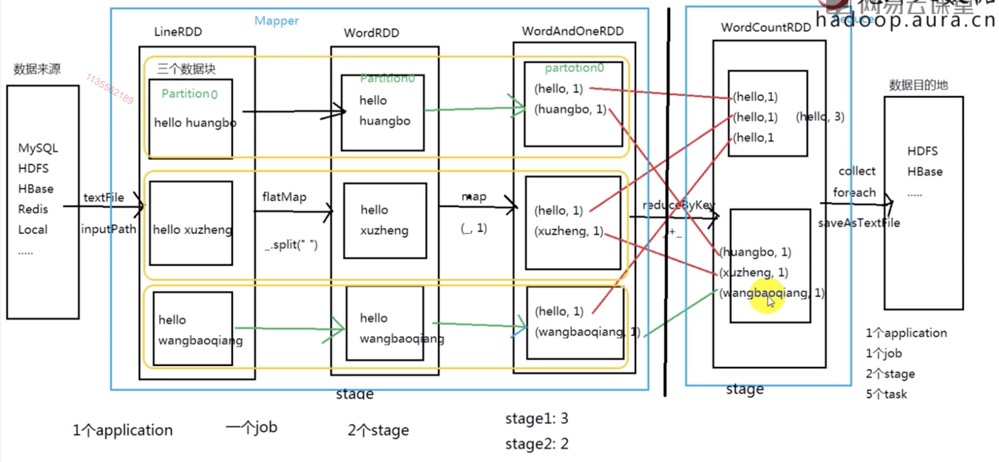
Spark Core 中的 RDD 详解 3.1
1. 广播变量
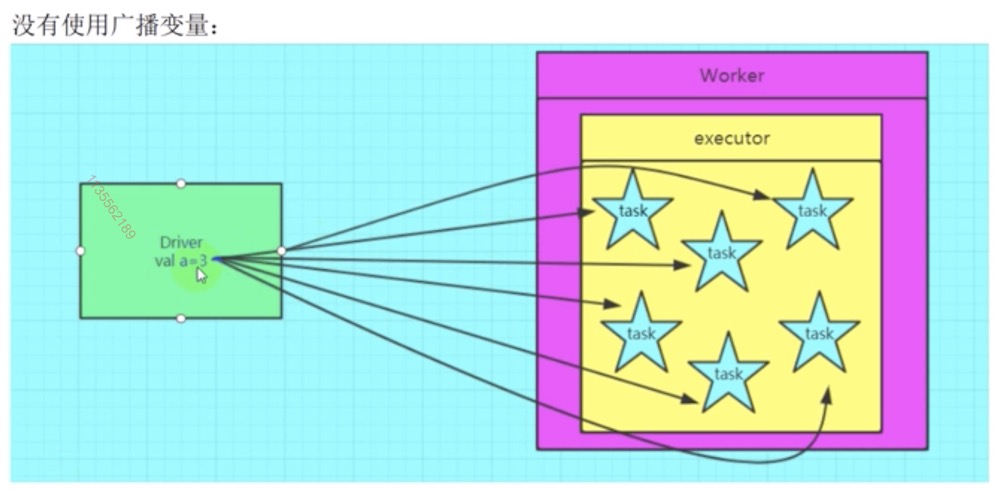
线程可以共享变量的思路
广播变量:
(1) 在默认情况下,每一个task都会维持一个全局变量的副本
有一个集合:100M 在 driver 中生成, 但是在所有的task中都需要使用
那么,每一个 task 都会维持一个当前这 100M 数据的副本
如果一个 executor 中启动了 6 个 task,最终消耗 600M 内存
(2). 如果使用广播变量的话
那么可以把当前这个100M的数据,就编程一个广播变量的值
用 driver 中的 sparkcontext 进行 全局所有 executor 广播
最后的效果:每个 executor 中只存在一份这个广播变量的副本
而不是原先的每一个task都保持一个副本
所以最终的内存消耗量: 100m
(3) 最后的效果:
- 减少了网络数据传输的量
- 减少了executor的内存使用
如果一个值很小,那么几乎没有广播的必要。
广播的值的大小越大,效果越明显
2. 累加器
1 | val a = sc.accumulator(0) |
还原一个累加器
1 | val b = a.value |
spark 的累加器 和 mapreduce编程模型的全局计数器是一个道理。
3. DAG规划和基础理论
切分 Stage 是 从后往前找 shuffer类型/宽依赖的算子,遇到一个就断开,形成一个 stage
最后一个 stage: ResultStage
除此之外的stage
因此spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄赖就将这个RDD加入该stage中。
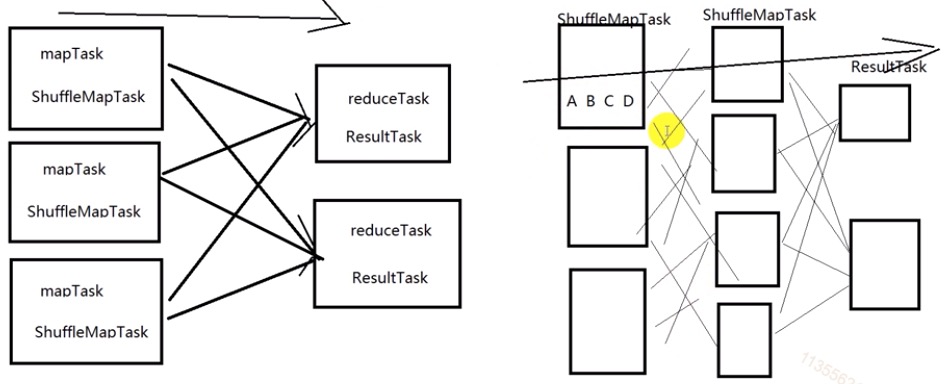
在spark中,Task的类型分为2种:ShuffleMapTask和ResultTask;简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!
而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中。
切分stage:
从后往前找 shuffle类型/宽依赖 的算子, 遇到一个就断开, 形成一个 stage
最后一个stage: ResultStage ------> ResultTask
除此之外的stage:ShffleMapStage ------> ShffleTask每一个 stage 都会切成多个同种类型的 Task
每一个 Stage 中的有可能包含多个不同的 RDD
那么一个 Stage 又有可能会划分多个 task 执行
每个 RDD 又可以指定不同的分区数
默认情况下:每一个分区,就会是一个 Task那么现在,如果遇到了一个 stage 中有多个不同分区数的RDD,
那么请问:到底这个stage中有多少个Task执行呢?5 4 3 -----> 3个task
以最后一个RDD的分区数来决定
切分job:
从前往后找action算子, 找到一个就形成一个 job.
3 + 2 = 5 tasks
DAG 的生成
checkpoint linage
检查点 血脉 血统
容错
对于Spark任务中的宽窄依赖,我们只喜欢窄依赖
DAGScheduler:
- spark-submit 提交任务
- 初始化 DAGScheduler 和 TaskScheduler
- 接收到 application 之后,DAGScheduler 会首先把 application 抽象成一个 DAG
- DAGScheduler 对这个 DAG (DAG中的一个Job) 进行 stage 的切分
- 把每一个 stage 提交给 TaskScheduler
rdd1.collect
client 提交任务的任务节点
如果是client模式,那么 driver程序就在 client 节点
如果模式是 cluster, driver 程序在 worker 中.
rdd20.countByKey()countByKey 是作用在 key-value 类型上的一个 action 算法
countByValue 一般是用来统计普通类型的RDD
map reduce recudeByKey filter, json难点:
- aggregate
- aggregate
count sum max min distinct avg
100G ----> 1G
20G -----> 30G
map mapPartitions
join mapjoin reducejoin
cogroup
coalesce
repartition
repartitionAndSortWithinPartitions
重新分区, 并且分区内数据进行排序
6. RDD 持久化操作 cache, persist
cache:
正常情况下: 一个RDD中是不包含真实数据的,只包含描述这个RDD的源数据信息
如果对这个RDD调用 cache 方法
那么这个rdd中的数据,现在依然还是没有真实数据
直到第一次调用一个action的算子出发了这个RDD的数据生成,那么cache 操作
cache()
persist() == persist(StorageLevel.MEMORY_ONLY)
persist(StorageLevel.XXXX)
1 | def cache(): this.type = persist() |
一个普通的文件 file ===》 内存
该 file 被序列化了 ===》 内存
JVM 最大的区域是 Head 内存, OffHeap 堆外内存
各种 byKey 操作 (重要)
----union, join, coGroup, subtract, cartesian----
- groupByKey
- reduceByKey
- aggregateByKey
- sortByKey
- combineByKey
Reference
- Spark广播变量和累加器详解
- 马老师-Spark的WordCount到底产生了多少个RDD
- 大数据技术之_19_Spark学习_02_Spark Core 应用解析+ RDD 概念 + RDD 编程 + 键值对 RDD + 数据读取与保存主要方式 + RDD 编程进阶 + Spark Core 实例练习
Checking if Disqus is accessible...