Spark Intrduce 2 - RDD
1. Spark 是什么?

SQL, Oracle, Spark
- Oracle == 汽车
- hadoop == 飞机
- SQL == 驾照
- Spark 让SQL并行运行 == SQL加速器
Spark 是计算引擎
2. Spark 执行过程

HiveOnSpark vs SparkSQL
- Store
- MR
HiveOnSpark, Hive SQL 可以用 Spark 执行引擎, 但是这样调优起来很麻烦
SparkSQL 比 Hive on Spark 好一点.
3. Spark 的起源

4. Spark 的架构图
Spark 2.x python & Java 性能 1:1
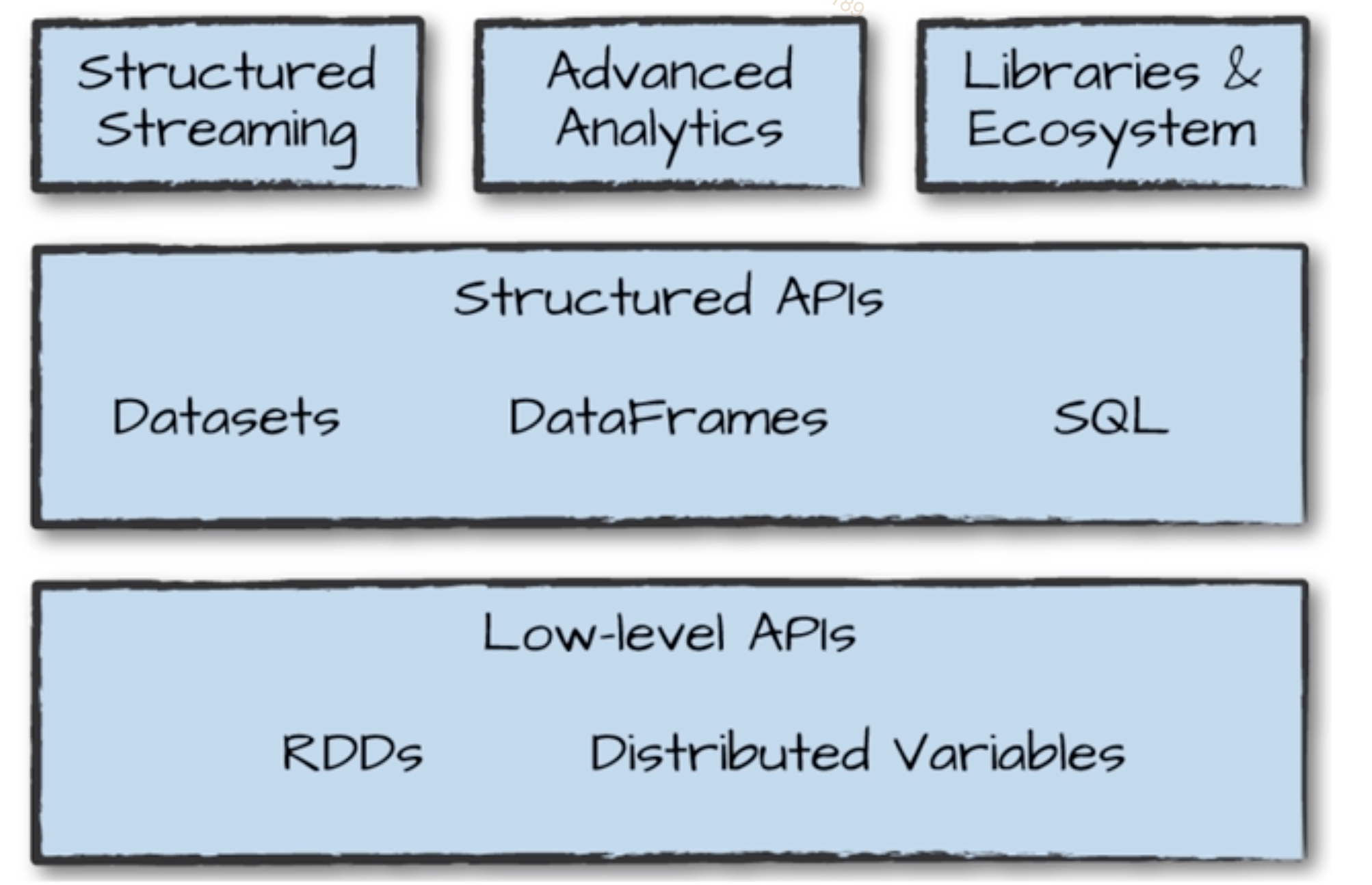
Spark DataFrame 与 pandas Dataframe 没关系,但是可以互相转换
- to_pandas
- to_spark
- DataSets : for Java
- Dataframe : for Python
- SQL : SQL
条条大路通罗马
Spark 适合大规模机器学习,不适合深度学习(tensorflow适合深度学习),这样理解对么?
5. RDD 的五个特性

6. Spark Api 如何使用
1 | 1. PYSPARK_PYTHON |
PYLIB maybe not setting
export PYSPARK_PYTHON=/Users/blair/.pyenv/versions/anaconda3/envs/spark/bin/python3
export PYSPARK_DRIVER_PYTHON=“jupyter”
export PYSPARK_DRIVER_PYTHON_OPTS=“notebook”
1 | 以下是 Mars 的设置 (我们直接用pyspark, 则不用直接这样显示在程序中指定): |
7. 利用 Pyspark 完成 WordCount
1 | from pyspark import SparkConf , SparkContext |
如果有3个节点, 则下列方法可以查看,数据分布在不同的 partition
1 | def indexedFunc(parindex,pariter): |
[‘partition : 0 => The’,
‘partition : 0 => history’,
‘partition : 0 => of’,
‘partition : 0 => New’,
‘partition : 0 => York’,
‘partition : 0 => begins’,
‘partition : 0 => around’,
‘partition : 0 => 10,000’,
查看 spark 运行状态: http://localhost:8080/

查看 spark Jobs 状态:http://localhost:4040/jobs/
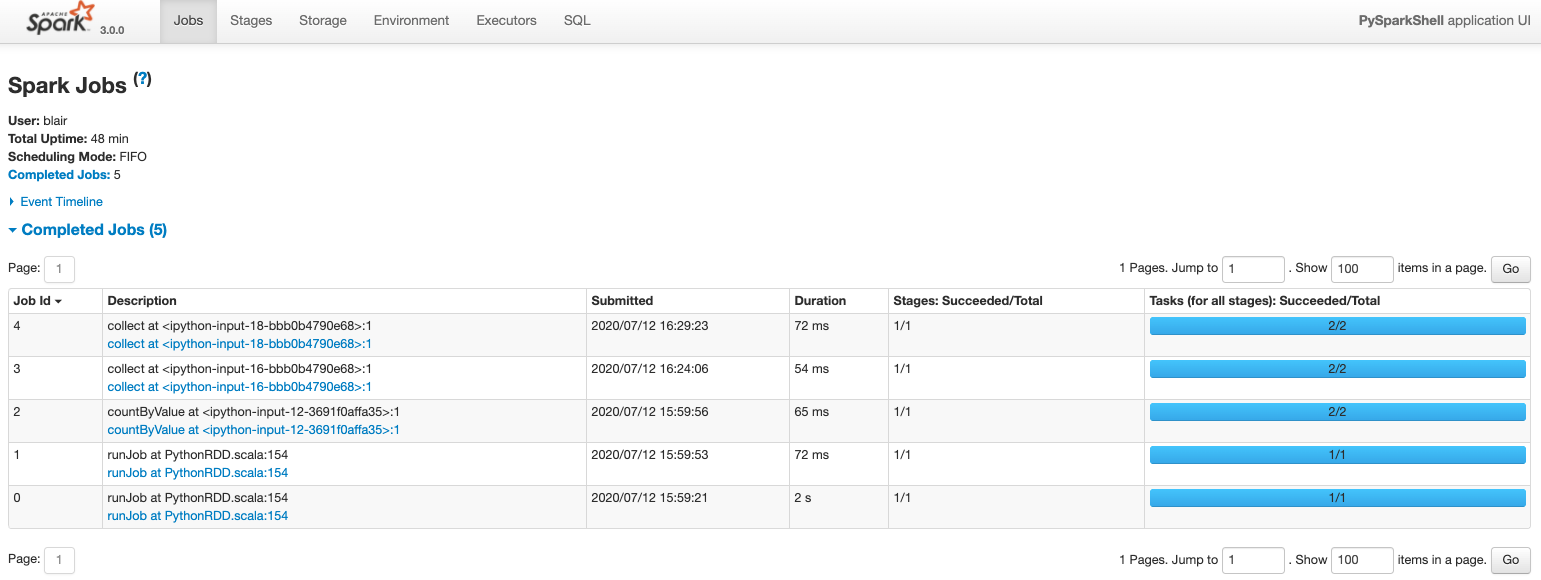
知识摘要:
如果用 Hadoop Mapreduce 来完成, 则代码写起来麻烦并繁多.
Spark 是 内存版的 Mapreduce, Mapreduce 可以说是所有分布式计算的鼻祖.
Spark 需要做性能调优的时候,还得再看 Mapreduce 的知识来修复.
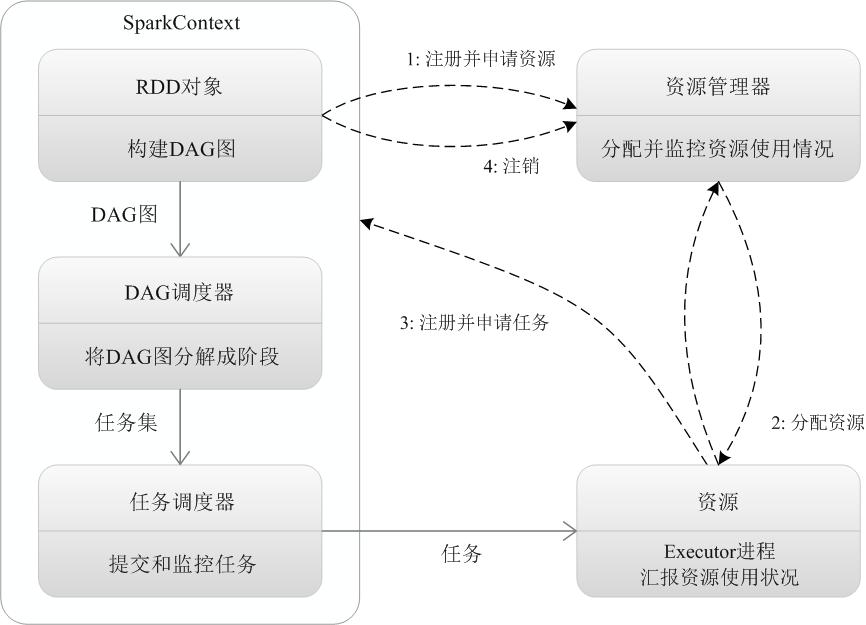
8. Spark 执行图
Reference
株式会社XG JAPAN 日本投资 | 过来人告诉你:日本创业移民的费用和坑
Checking if Disqus is accessible...