NN 可用来模拟 regression,给一组数据,用一条线对数据进行拟合,并可预测新输入 x 的输出值。
Regressor in Keras
创建数据
1 2 3 4 5 6 7 8 9 10 11 12
import numpy as np np.random.seed(1337) # for reproducibility from keras.models import Sequential from keras.layers import Dense import matplotlib.pyplot as plt # 可视化模块
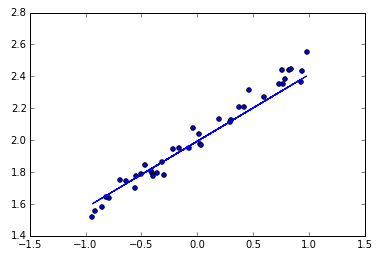
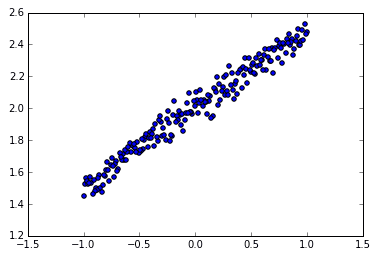
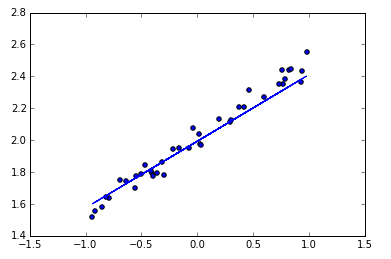
# create some data X = np.linspace(-1, 1, 200)
np.random.shuffle(X) # randomize the data
Y = 0.5 * X + 2 + np.random.normal(0, 0.05, (200, ))
1 2 3 4 5 6
# plot data plt.scatter(X, Y) plt.show()
X_train, Y_train = X[:160], Y[:160] # train 前 160 data points X_test, Y_test = X[160:], Y[160:] # test 后 40 data points
1. build model
1 2
model = Sequential() model.add(Dense(output_dim=1, input_dim=1))
用 Sequential 建立 model, 再用 model.add 添加神经层,添加的是 Dense FC 层
Checking if Disqus is accessible...