BERT tutorial 1
2018.10 google 发布 BERT 模型. 引爆整个AI圈的 NLP 模型. 在 NLP领域 刷新 11 项记录.
BERT 其实是 language_encoder,把输入的 sentence 或 paragraph 转成 feature_vector(embedding).
Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT 创新点在于提出了一套完整的方案,利用之前最新的算法模型,去解决各种各样的 NLP 任务.
1. NLP 的发展
Language Model (语言模型就是要看到上文预测下文, So NNLM)
n-gram model(n元模型)(基于 马尔可夫假设 思想)上下文相关的特性 建立数学模型。
2001 - NNLM , @Bengio , 火于 2013 年, 沉寂十年终时来运转。 但很快又被NLP工作者祭入神殿。
2008 - Multi-task learning
2013 - Word2Vec (Word Embedding的工具word2vec : CBOW 和 Skip-gram)
2014 - sequence-to-sequence
2015 - Attention
2015 - Memory-based networks
2018 - Pretrained language models
good 张俊林: 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
NNLM vs Word2Vec
- NNLM 目标: 训练语言模型, 语言模型就是要看上文预测下文, word embedding 只是无心的一个副产品。
- Word2Vec目标: 它单纯就是要 word embedding 的,这是主产品。
2018 年之前的 Word Embedding 有个缺点就是无法处理 多义词 的问题, 静态词嵌.
ELMO: Embedding from Language Models
ELMO的论文题目:“Deep contextualized word representation”
NAACL 2018 最佳论文 - ELMO: Deep contextualized word representation
ELMO 本身是个根据当前上下文对Word Embedding动态调整的思路。
ELMO 有什么缺点?
- LSTM 抽取特征能力远弱于 Transformer
- 拼接方式双向融合特征能力偏弱
**GPT (Generative Pre-Training) **
- 第一个阶段是利用 language 进行 Pre-Training.
- 第二阶段通过 Fine-tuning 的模式解决下游任务。
GPT: 有什么缺点?
- 要是把 language model 改造成双向就好了
- 不太会炒作,GPT 也是非常重要的工作.
Bert 亮点 : 效果好 和 普适性强
- Transformer 特征抽取器
- Language Model 作为训练任务 (双向)
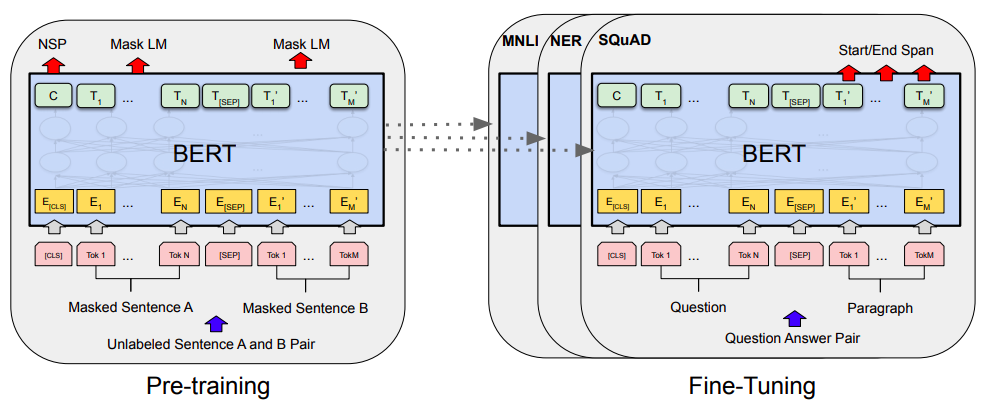
Bert 采用和 GPT 完全相同的 两阶段 模型:
- Pre-Train Language Model;
- Fine-> Tuning模式解决下游任务。
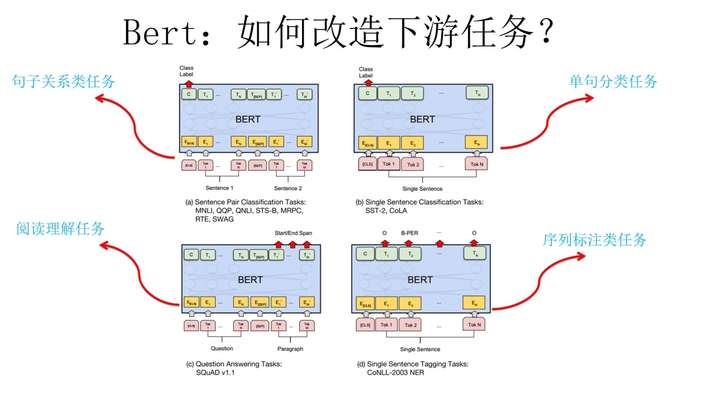
NLP 的 4大任务
| 4 NLP task | description |
|---|---|
| 序列标注 | 特点是句子中每个单词要求模型根据上下文都要给出一个 分类label; |
| 分类任务 | 特点是不管文章有多长,总体给出一个分类label 即可; |
| 句子关系判断 | 特点是给定两个句子,模型判断出两个句子 是否具备某种语义关系; |
| 生成式任务 | 特点是输入文本内容后,需要自主生成另外一段文字。 |
1. 简介
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
2. 原理篇
本章将会先给大家介绍BERT的核心transformer,而transformer又是由attention组合而成.
2.1 Attention机制讲解
2.2 Transrofmer模型讲解
Jay Alammar’s Blog
2.3 BERT原理
More Reading:
3. 代码篇
4. 实践篇
5. BERT
- hanxiao大佬开源出来的bert-as-service框架很适合初学者
- Netycc’s blog 利用Bert构建句向量并计算相似度
- BERT使用详解(实战)
- BERT中文文本相似度计算与文本分类
Reference
-
[从语言模型到Seq2Seq:Transformer如戏,全靠Mask][w1]
Checking if Disqus is accessible...