SVM 和 LR 的区别与联系?
关于 SVM 的详细原理与推导过程,详见: Support Vecor Machine (六部曲)
其实我认为 SVM 的使用率已经明显在下降趋势了,主要原因是随着神经网络的兴起之后,所以我不建议一定要花非常多的经历去学习 SVM 的原理和推导了,可以简单了解下。 主要还是了解下适用范围和场景等就可以了。
1. LR vs SVM
要说有什么本质区别,那就是 loss function 不同,两者对数据和参数的敏感程度不同
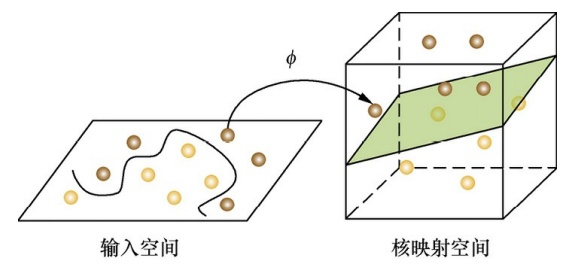
(1). 对非线性表达上,LR 只能通过人工的特征组合来实现,而 SVM 引入核函数来实现非线性表达。
(2). LR 产出的是概率值,而 SVM 只能产出是正类还是负类,不能产出概率。
(3). Linear SVM 依赖数据表达的距离测度,所以需要对数据先做 normalization;LR不受其影响.
(4). SVM 不直接依赖数据分布,而LR则依赖, SVM 主要关注的是“支持向量”,也就是和分类最相关的少数点,即关注局部关键信息;而 LR 是在全局进行优化的。这导致 SVM 天然比 LR 有更好的泛化能力,防止过拟合。 LR则受所有数据点的影响,如果数据不同类别 strongly unbalance 一般需要先对数据做 balancing。
(5). 损失函数的优化方法不同,LR 是使用 GD 来求解 对数似然函数 的最优解;SVM 使用 (Sequnential Minimal Optimal) 顺序最小优化,来求解条件约束损失函数的对偶形式。
一般用线性核和高斯核,也就是Linear核与RBF核需要注意的是需要对 数据归一化处理.
一般情况下RBF效果是不会差于Linear但是时间上RBF会耗费更多
扩展点:
注:不带正则化的LR,其做 normalization 的目的是为了方便选择优化过程的起始值,不代表最后的解的 performance 会跟 normalization 相关,而其线性约束是可以被放缩的(等式两边可同时乘以一个系数),所以做 normalization 只是为了求解优化模型过程中更容易选择初始值
2. Andrew Ng
- 如果Feature的数量很大,跟样本数量差不多,这时候选用LR或者是Linear Kernel的SVM
- 如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM+Gaussian Kernel
- 如果Feature的数量比较小,而样本数量很多,需要手工添加一些feature变成第一种情况
如何量化 feature number 和 sample number:
n 是feature的数量, m是样本数
1). feature number >> sample number,则使用LR算法或者不带核函数的SVM(线性分类)
feature number = 1W, sample number = 1K2). fn 小, sample number 一般1W,使用带有 kernel函数 的 SVM算法.
3). fn 小, sample number 很大5W+(n=1-1000,m=50000+)
增加更多的 feature 然后使用LR 算法或者 not have kernel 的 SVM
Reference
- LR 与 SVM的异同
- 懒死骆驼 - 统计学习方法笔记(一)
- 知乎 : 最小二乘、极大似然、梯度下降有何区别?
- 知乎 : Linear SVM 和 LR 有什么异同?
- 白开水加糖 SVM与LR的比较
- 懒死骆驼 - 口述模型整理
- 支持向量机(SVM)硬核入门-基础篇
- scikit-learn 逻辑回归类库使用小结
- LR 正负样本不均衡问题
Checking if Disqus is accessible...