实战Google深度学习框架 笔记-第8章 循环神经网络-1-前向传播。 Github: RNN-1-Forward_Propagation.ipynb
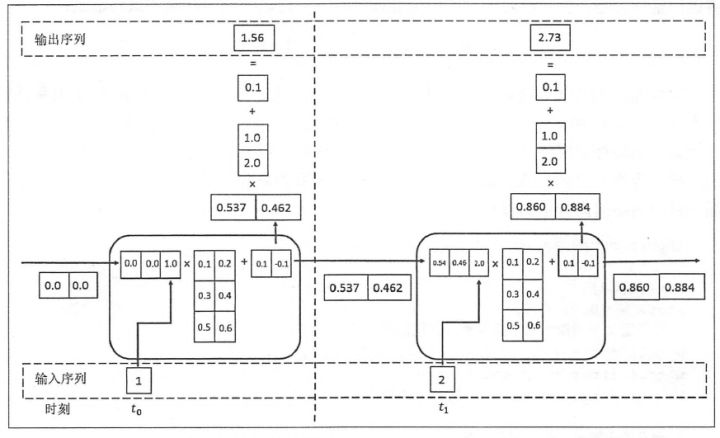
运算的流程图可参考下面这张图
RNN Forward Propagation
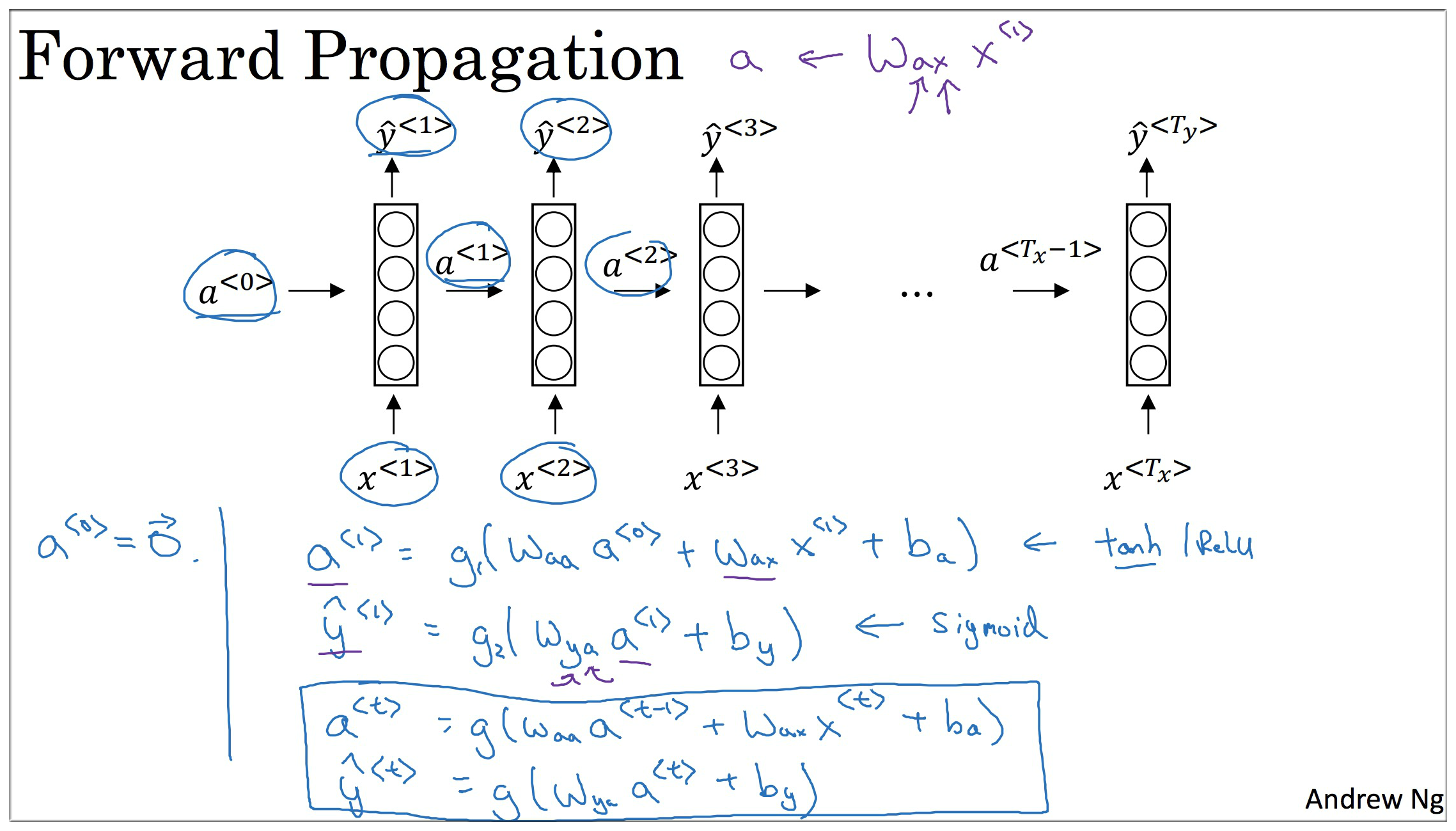
RNN 前向传播知识回顾
a<0>=0
a<1>=g_1(W_aaa<0>+W_axx<1>+b_a)
y<1>=g_2(W_yaa<1>+b_y)
a<t>=g_1(W_aaa<t−1>+W_axx<t>+b_a)
y<t>=g_2(W_yaa<t>+b_y)
激活函数:g_1 一般为 tanh函数 (或者是 Relu函数),g_2 一般是 Sigmod函数.
注意: 参数的下标是有顺序含义的,如 W_ax 下标的第一个参数表示要计算的量的类型,即要计算 a 矢量,第二个参数表示要进行乘法运算的数据类型,即需要与 x 矢量做运算。如 W_axxt→a
1. 定义RNN的参数
这个例子是用np写的,没用到tensorflow
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import numpy as np
X = [1, 2]
state = [0.0, 0.0]
w_cell_state = np.asarray([[0.1, 0.2], [0.3, 0.4]])
w_cell_input = np.asarray([[0.5, 0.6]])
b_cell = np.asarray([0.1, -0.1])
w_output = np.asarray([[0.1], [2.0]])
b_output = 0.1
|
2. 执行前向传播的过程
1
2
3
4
5
6
7
8
9
10
11
12
13
|
for i in range(len(X)):
before_activation = np.dot(state, w_cell_state) + X[i] * w_cell_input + b_cell
state = np.tanh(before_activation)
final_output = np.dot(state, w_output) + b_output
print("iteration round:", i+1)
print("before activation: ", before_activation)
print("state: ", state)
print("output: ", final_output)
|
output:
1
2
3
4
5
6
7
8
| iteration round: 1
before activation: [[0.95107374 1.0254142 ]]
state: [[0.74026877 0.7720626 ]]
output: [[1.71815207]]
iteration round: 2
before activation: [[1.40564566 1.55687879]]
state: [[0.88656589 0.91491336]]
output: [[2.0184833]]
|
和其他神经网络类似,在定义完损失函数之后,套用第4章中介绍的优化框架TensorFlow就可以自动完成模型训练的过程。这里唯一需要特别指出的是,理论上循环神经网络可以支持任意长度的序列,然而在实际中,如果序列过长会导致优化时出现梯度消散的问题(the vanishing gradient problem) (8) ,所以实际中一般会规定一个最大长度,当序列长度超过规定长度之后会对序列进行截断。
Reference
Checking if Disqus is accessible...