RNN 的语言模型 TensorFlow 实现
上篇 PTB 数据集 batching 中我们介绍了如何对 PTB 数据集进行 连接、切割 成多个 batch,作为 NNLM 的输入。
本文将介绍如何采用 TensorFlow 实现 RNN-based NNLM。
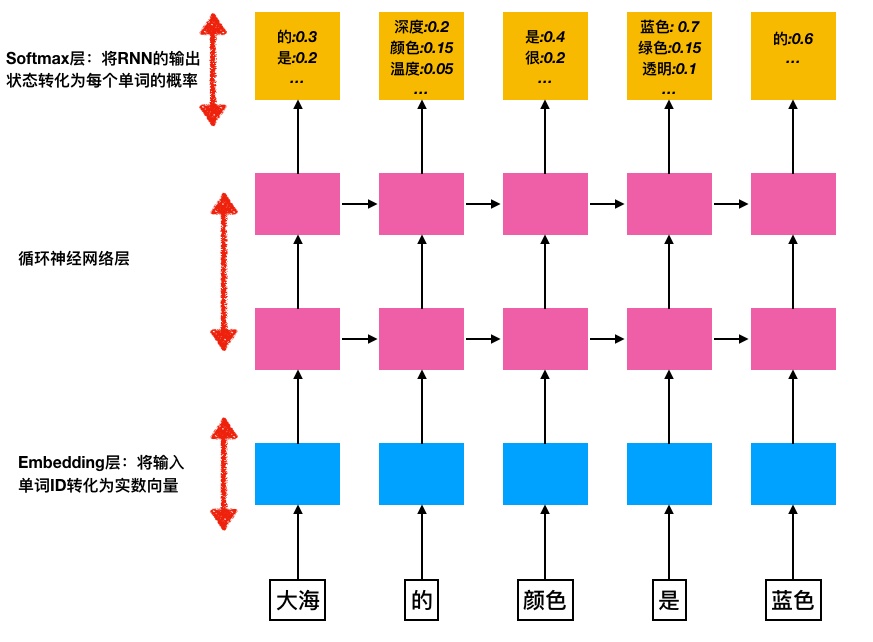
1. Embedding 层
将 word 编号 转化为 word embedding 两大作用 :
| No. | function | desc |
|---|---|---|
| 1. | 降低输入的维度 | 词向量的维度通常在 200 ~ 1000 之间, 大大减少 RNN 网络的参数数量 与 计算量 |
| 2. | 增加语义信息 | 简单的单词编号是不包含任何语义信息的. |
词向量维度: EMB_SIZE,词汇表大小: VOCAB_SIZE
所有单词的词向量可以放入一个大小为 (EMB_SIZE, VOCAB_SIZE) 的矩阵内
在读取词向量时,可以调用 tf.nn.embedding_lookup 方法。
用 tf.Variable 来表示词向量,这样就可以采用任意初始化的词向量,学习过程中也会优化词向量。

1 | # 定义单词的词向量矩阵 |
其中输入数据 input_data 的维度是 (batch_size * num_steps)
而输出的 input_embedding 的维度成为 (batch_size * num_steps * EMB_SIZE).
在本文中,我们输入数据维度是 () ,EMB_SIZE = 300, 输入词向量维度时 () .
2. Softmax 层
Softmax层 的作用是将 RNN 的输出 转化为一个单词表中每个单词的输出概率,为此需要两个步骤:
2.1 第一步
使用一个线性映射将 RNN 的输出映射为一个维度与词汇表大小相同的向量,这一步的输出叫做 logits. 代码如下所示:
1 | # 首先定义映射用到的参数 |
其中 output 是 RNN 的输出,维度是 [batch_size * num_steps, HIDDEN_SIZE]
经过线性映射后,输出结果是 [batch_size * num_steps, VOCAB_SIZE].
Reference
- tensorflow.org
- tf.nn.embedding_lookup函数原理?
- 求通俗讲解下tensorflow的embedding_lookup接口的意思?
- Tomas Mikolov PTB 数据
- 如何理解深度学习源码里经常出现的logits?
- 基于循环神经网络的语言模型的介绍与TensorFlow实现(4):TensorFlow实现RNN-based语言模型
Checking if Disqus is accessible...