CNN (week4) - Face recognition & Neural style transfer
Face recognition & Neural style transfer 能够在图像、视频以及其他 2D 或 3D 数据上应用这些算法。
1. What is face recognition?
这一节中的人脸识别技术的演示的确很NB…, 演技不错,😄

2. One Shot Learning
作为老板希望与时俱进,所以想使用人脸识别技术来实现打卡。
假如我们公司只有4个员工,按照之前的思路我们训练的神经网络模型应该如下:

如图示,输入一张图像,经过CNN,最后再通过 Softmax 输出 5 个可能值的大小 (4个员工中的一个,或者都不是,所以共5种可能性)。
看起来好像没什么毛病,但是我们要相信我们的公司会越来越好啊,所以难道公司每增加一个人就要重新训练CNN 及 最后一层的输出数量吗 ?
one-shot:
这显然有问题,所以有人提出了一次学习(one-shot),更具体地说是通过一个函数来求出输入图像与数据库中的图像的差异度,用 表示。

如上图示,如果两个图像之间的差异度不大于某一个阈值 τ,那么则认为两张图像是同一个人。反之,亦然。
下一小节介绍了如何计算差值。
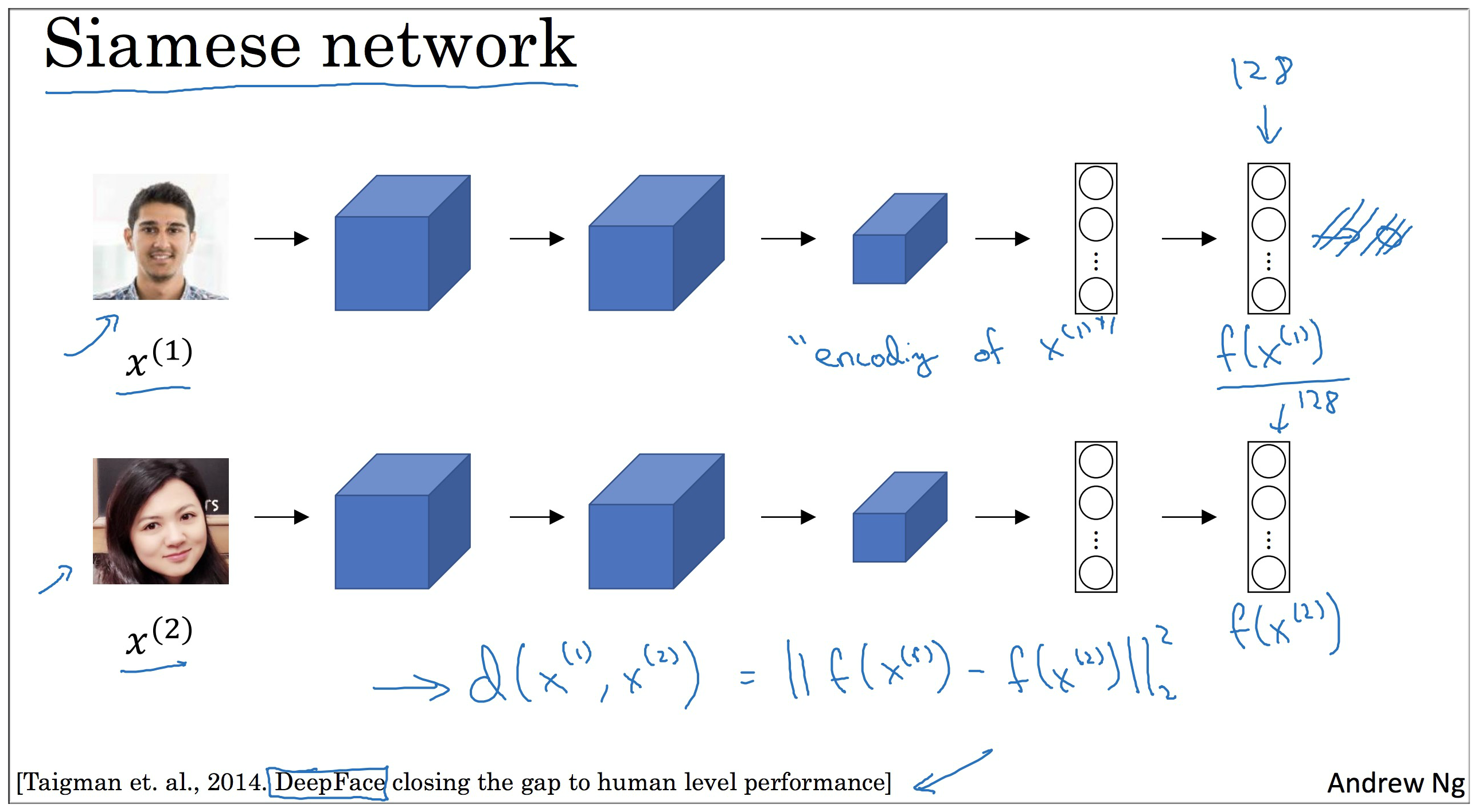
3. Siamese Network
注意:下图中两个网络参数是一样的。
先看上面的网络。记输入图像为 ,经过卷积层,池化层 和 全连接层 后得到了箭头所指位置的数据 (一般后面还会接上 层,但在这里暂时不用管),假设有 128 个节点,该层用 表示,可以理解为输入 的编码。
那么下一个网络同理,不再赘述。
因此上一节中所说的差异度函数即为
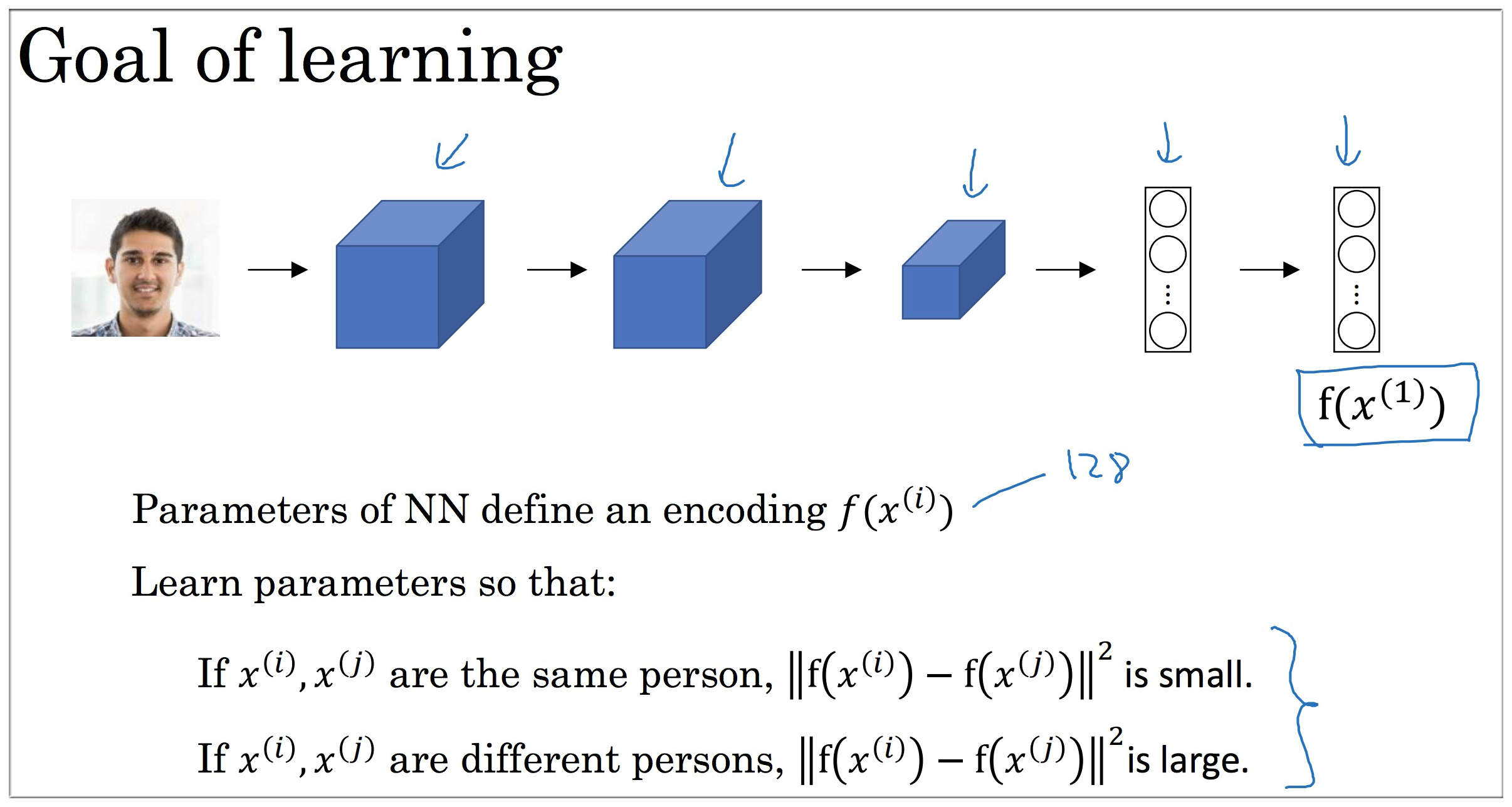
问题看起来好像解决了,但感觉还漏了点什么。。神经网络的参数咋确定啊?也就是说 的参数怎么计算呢?
首先可以很明确的是如果两个图像是同一个人,那所得到的参数应该使得 的值较小,反之较大。
4. Triplet Loss
4.1 Learning Objective
这里首先介绍一个三元组,即 (Anchor, Positive, Negative),简写为(A,P,N)
| (A,P,N) | 三元组 各个含义 |
|---|---|
| Anchor | 可以理解为用于识别的图像 (锚) |
| Positive | 表示是这个人 |
| Negative | 表示不是同一个人 |
由上一节中的思路,我们可以得到如下不等式:
, 即 (如下图示)

但是这样存在一个问题,即如果神经网络什么都没学到,返回的值是0,也就是说如果 的话,那么这个不等式是始终成立的。(如下图示)

为了避免上述特殊情况,且左边值必须小于0,所以在右边减去一个变量α,但按照惯例是加上一个值,所以将α加在左边。


综上,所得到的参数需要满足如下不等式
4.2 Lost function
介绍完三元组后,我们可以对单个图像定义如下的损失函数(如下图示)
解释一下为什么用max函数,因为如果只要满足 ,我们就认为已经正确识别出了图像中的人,所以对于该图像的损失值是 0.
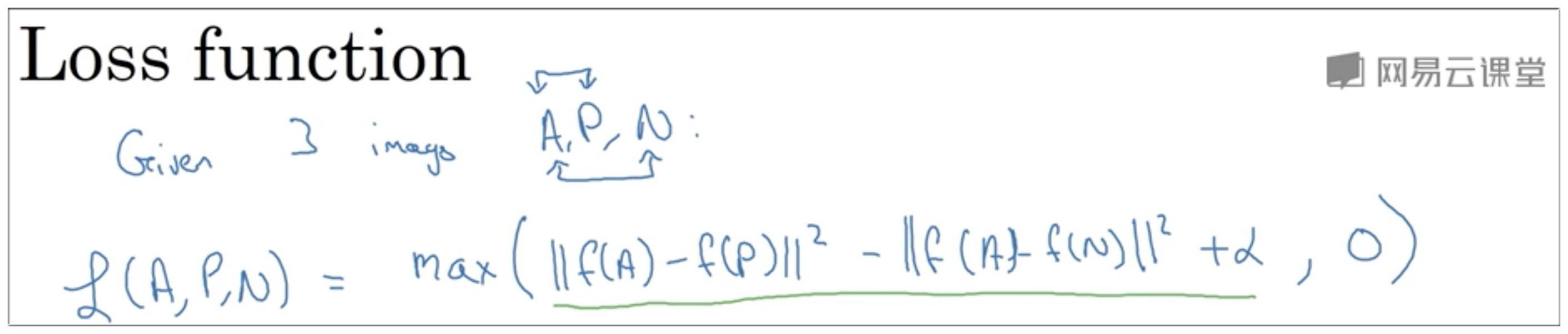
所以总的损失函数是 :
要注意的是使用这种方法要保证每一个人不止有一张图像,否则无法训练。另外要注意与前面的 One-shot 区分开来,这里是在训练模型,所以训练集的数量要多一些,每个人要有多张照片。而One-shot是进行测试了,所以只需一张用于输入的照片即可。
4.3 Choosing the triplets(A,P,N)
还有一个很重要的问题就是如何选择三元组 (A,P,N)。因为实际上要满足不等式 是比较简单的,即只要将 Negative 选择的比较极端便可,比如 Anchor 是一个小女孩,而 Negative 选择一个老大爷。
所以还应该尽量满足

5. Face Verification and Binary Classification
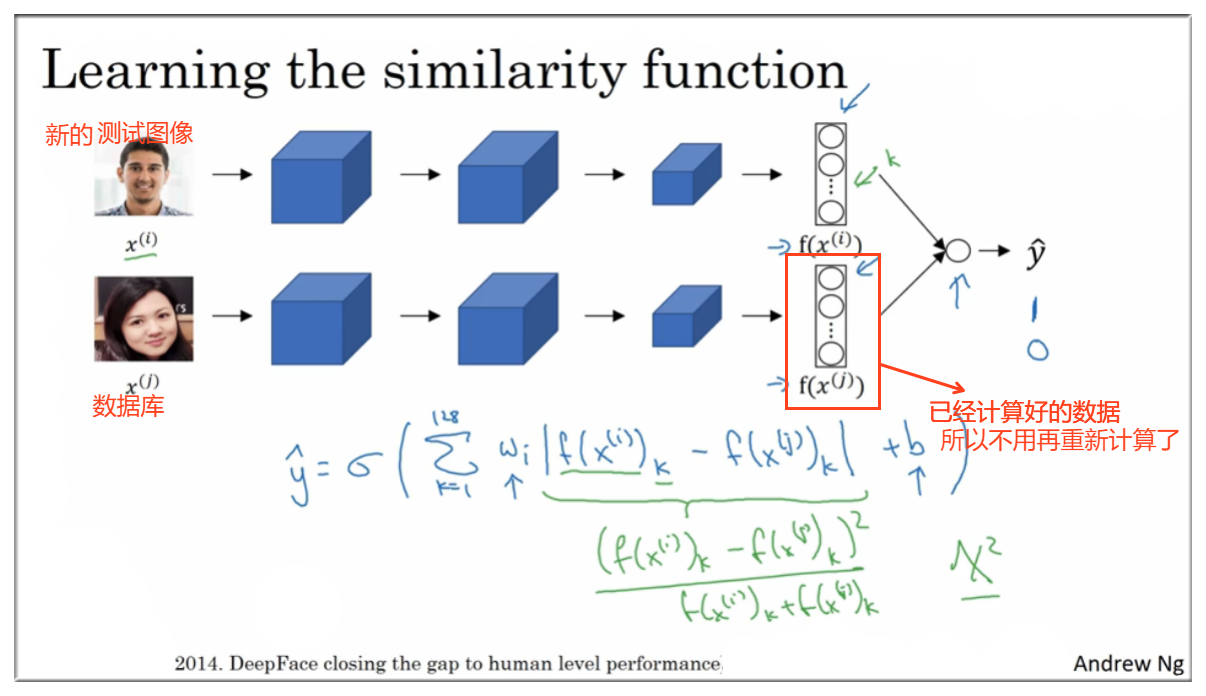
通过以上内容,我们可以确定下图中的网络的参数了,那么现在开始进行面部验证了。
上面的是测试图,下面的是数据库中的一张照片
和之前一样假设 有 128个节点,之后这两个数据作为输入数据输入到后面的逻辑回归模型中去,即
若 , 为同一人。反之,不是。
如下图示,绿色下划线部分可以用其他公式替换,即有
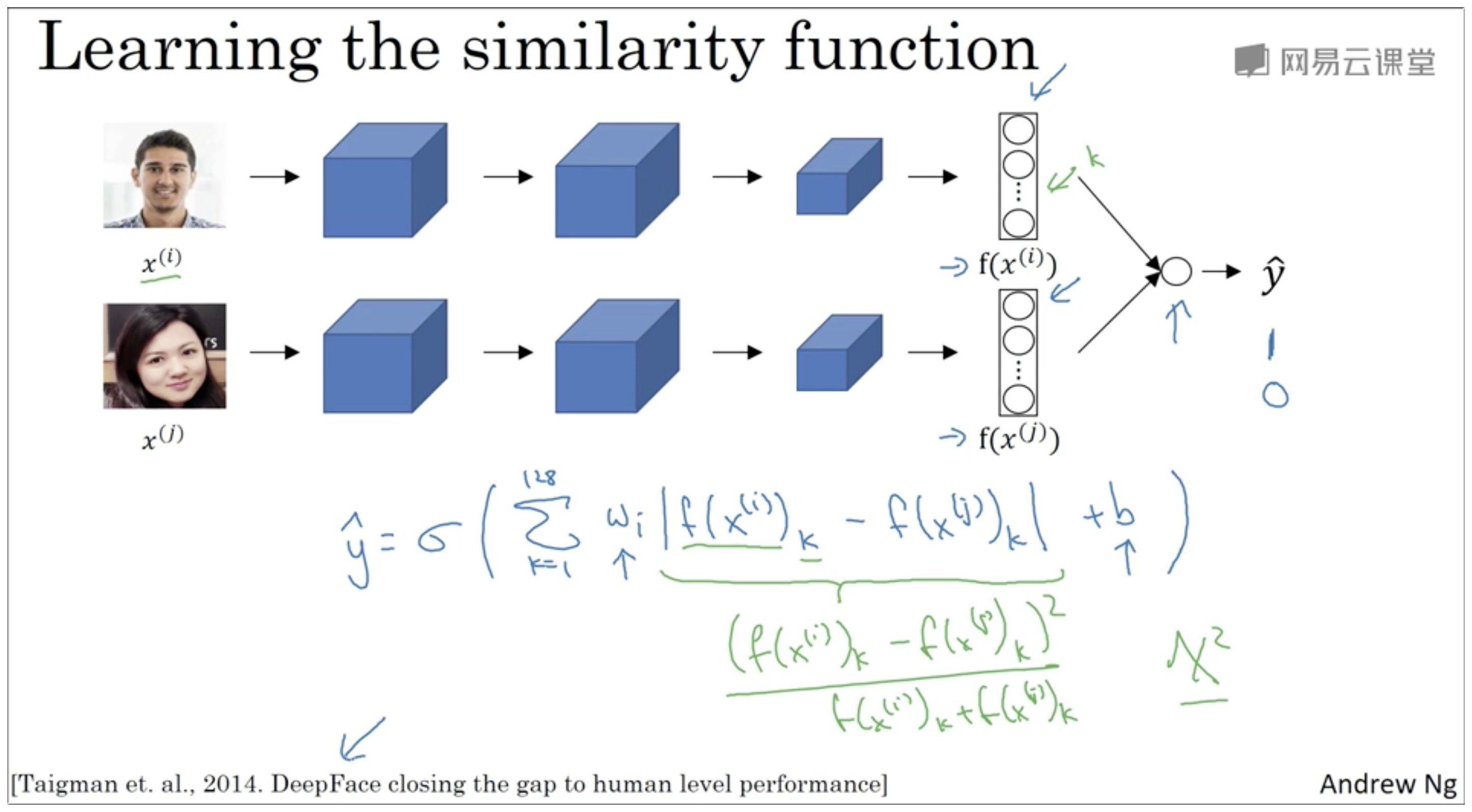
当然数据库中的图像不用每次来一张需要验证的图像都重新计算,其实可以提前计算好,将结果保存起来,这样就可以加快运算的速度了。
6. What is neural style transfer?

7. What are deep ConvNets learning?
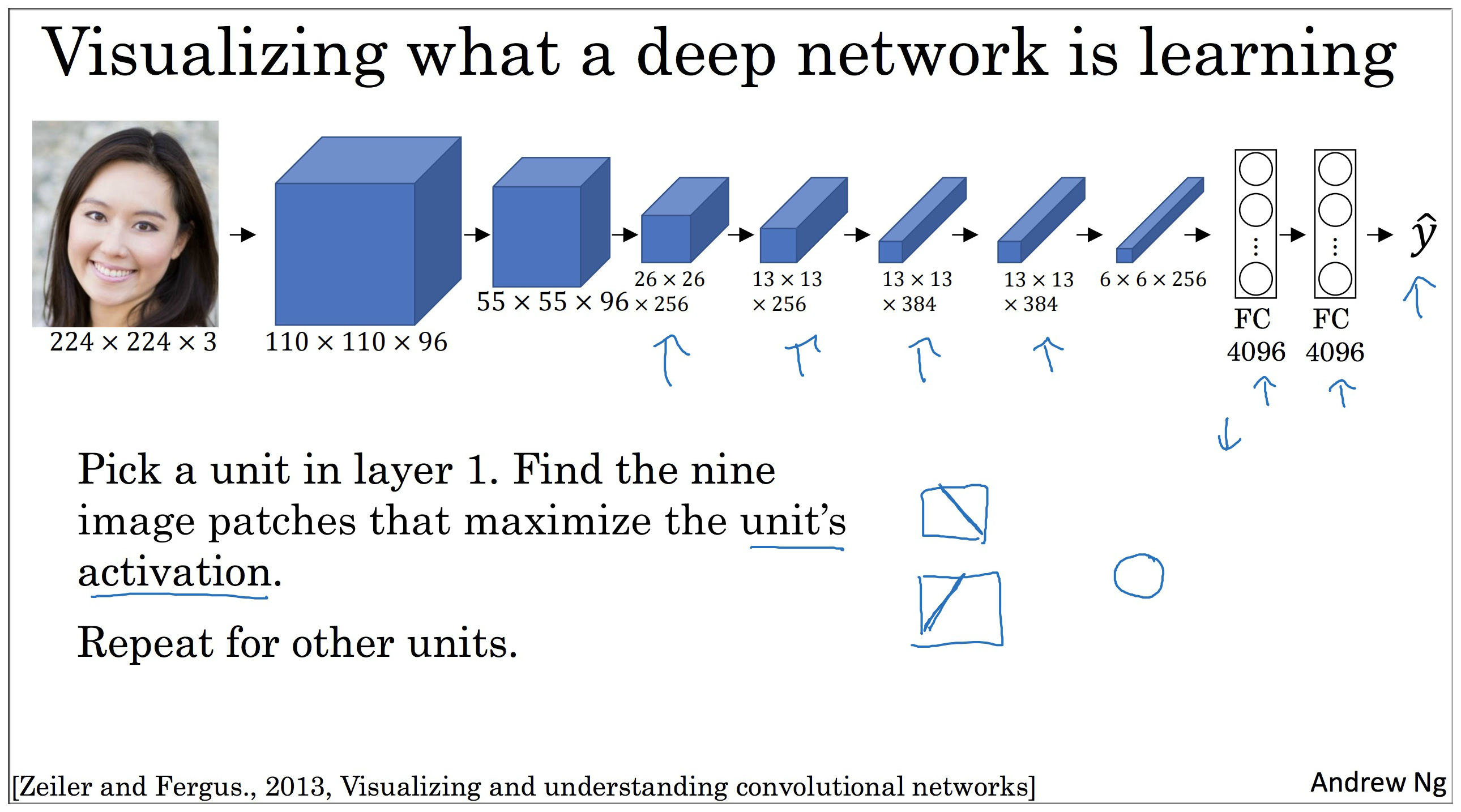
第一层只能看到小部分卷积神经.
你选择一个隐藏单元,发现有9个图片,最大化了单元激活,你可能找到类似这样的图片浅层区域.

8. Cost Function
如下图示:

左上角的包含 Content 的图片简称为 C,右上角包含 Style 的简称 S,二者融合后得到的图片简称为 G。
我们知道计算问题须是有限的,所以融合的标准是什么?也就是说 Content 的保留程度和 Style 的运用程度如何取舍呢?
此时引入损失函数,并对其进行最优化,这样便可得到最优解。
定义用来生成图像的好坏, 表示 图像 和 图像 之间的差异, 同理。
计算过程示例:
随机初始化图像 ,假设为 100*100*3 (maybe 500*500*3) (如下图右边四个图像最上面那个所示)
使用梯度下降不断优化 。 (优化过程如下图右边下面3个图像所示)

下面一小节将具体介绍 Cost Function 的计算。
9. Content Cost Function
首先假设我们使用 第 层 隐藏层 来计算 ,注意这里的 一般取在中间层,而不是最前面的层,或者最后层
原因如下:
- 假如取第1层,那么得到的 图像 将会与 图像 像素级别的相似,这显然不行。
- 假如取很深层,那么该层已经提取出了比较重要的特征,例如 图像 中有一条狗,那么得到的 图像 会过度的保留这个特征。
- 然后使用预先训练好的卷积神经网络,如 VGG网络。这样我们就可以得到 图像 和 图像 在第层的激活函数值,分别记为
- 内容损失函数

10. Style Cost Function
10.1 什么是“风格”
要计算风格损失函数,我们首先需要知道“风格(Style)”是什么。
我们使用 层的激活来度量“Style”,将“Style”定义为通道间激活值之间的相关系数。(Define style as correlation between activation across channels)
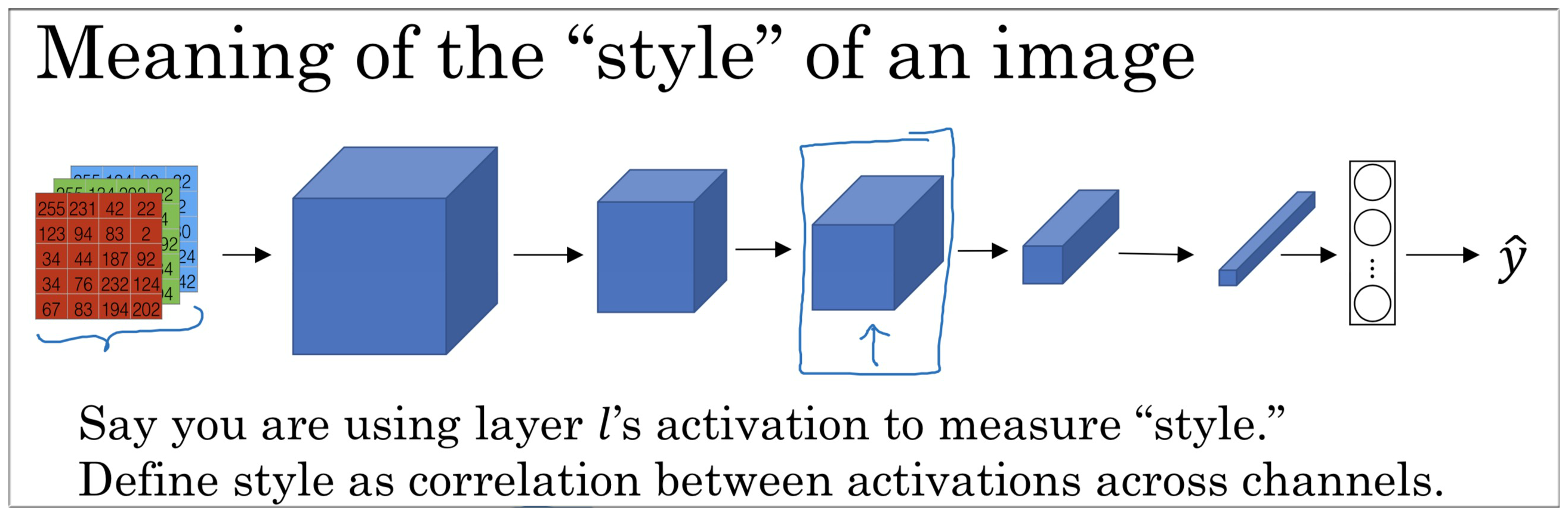
那么我们如何计算这个所谓的相关系数呢?
下图是我们从上图中所标识的第 层,为方便说明,假设只有 5 层通道。
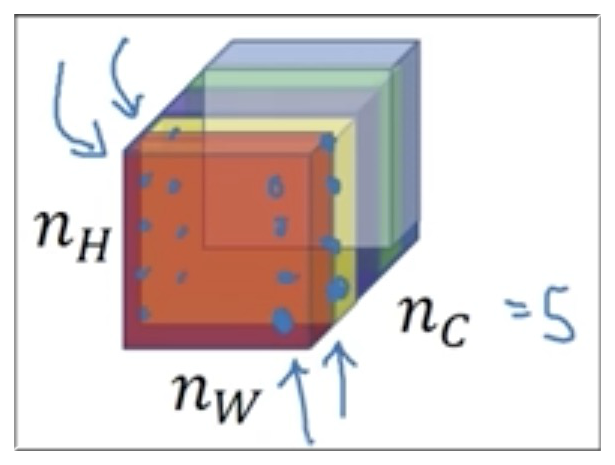
如上图示,红色通道和黄色通道对应位置都有激活项,而我们要求的便是它们之间的相关系数。
但是为什么这么求出来是有效的呢?为什么它们能够反映出风格呢?
继续往下看↓
10.2 图像风格的直观理解
如图风格图像有 5 层通道,且该图像的可视化特征如 左下角图 所示。

其中红色通道可视化特征如图中箭头所指是垂直条纹,而黄色通道的特征则是橘色背景。