Convolutional Neural Networks (week3) - Object detection
知道如何将卷积网络应用到视觉检测和识别任务。 知道如何使用神经风格迁移生成艺术。
1. Object Localization
这一小节视频主要介绍了我们在实现目标定位时标签该如何定义
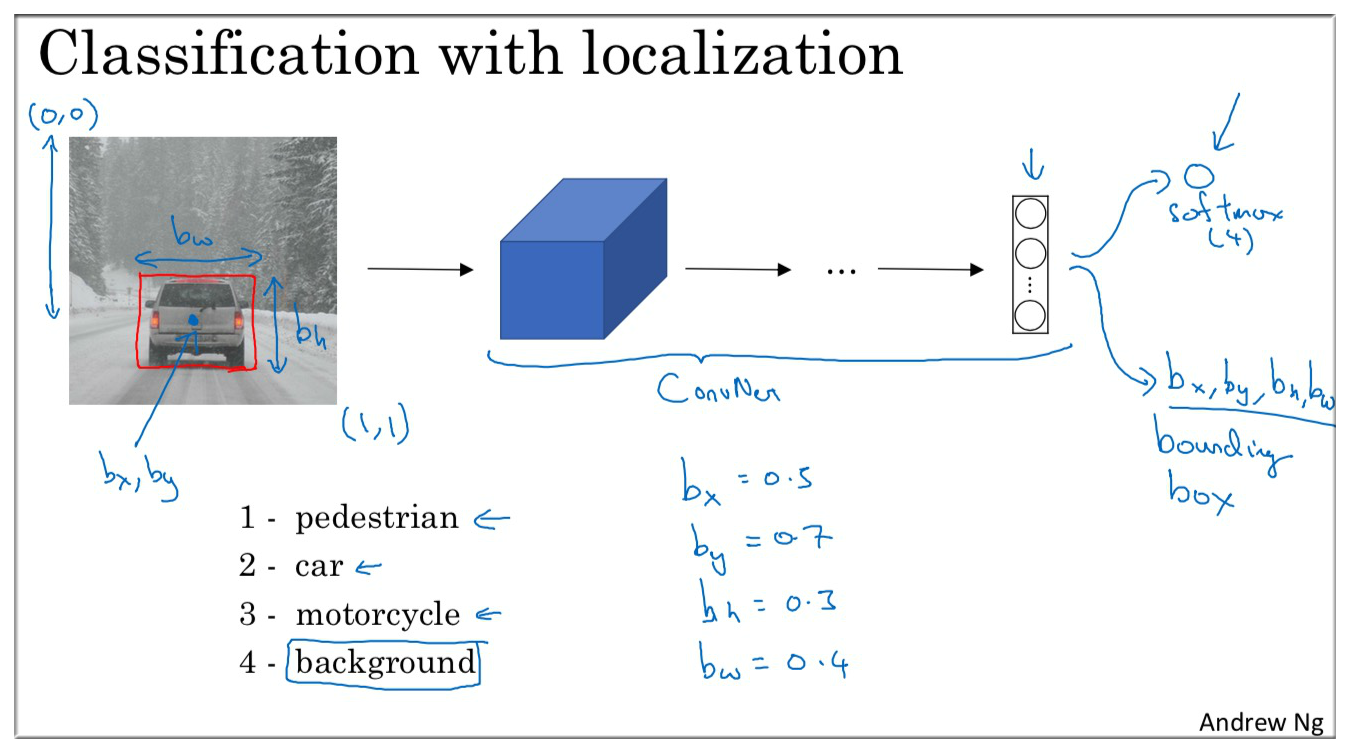
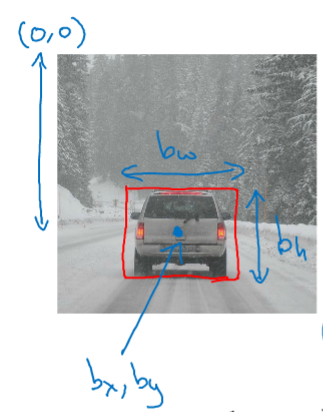
输出 softmax 的同时,在输出4个值 , 边界框的具体位置 (图片左上角坐标为 (0, 0), 右下角为 (1, 1) )
在上面的例子中, 的值大约为 0.5, 的值大约为 0.7,最佳位置.
how we define the target label for this as a supervised learning task.
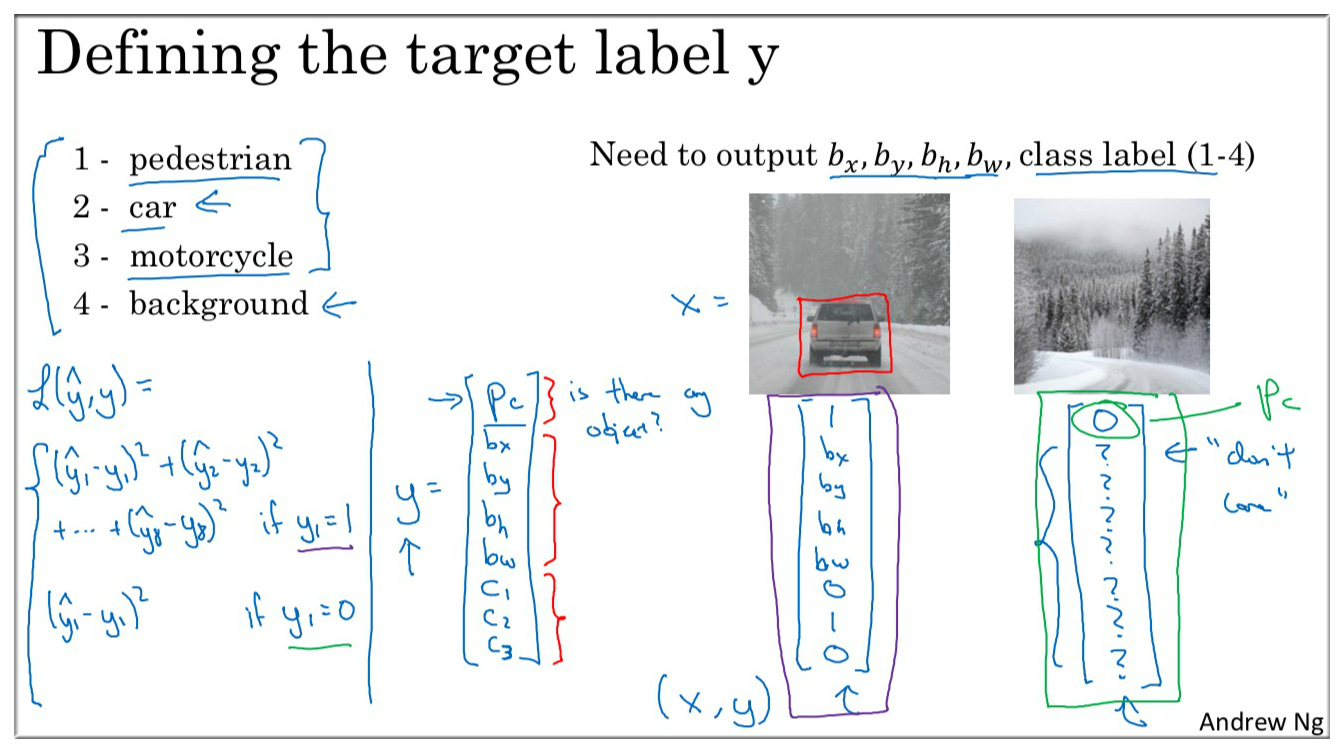
上图左下角给出了损失函数的计算公式 (这里使用的是平方差)
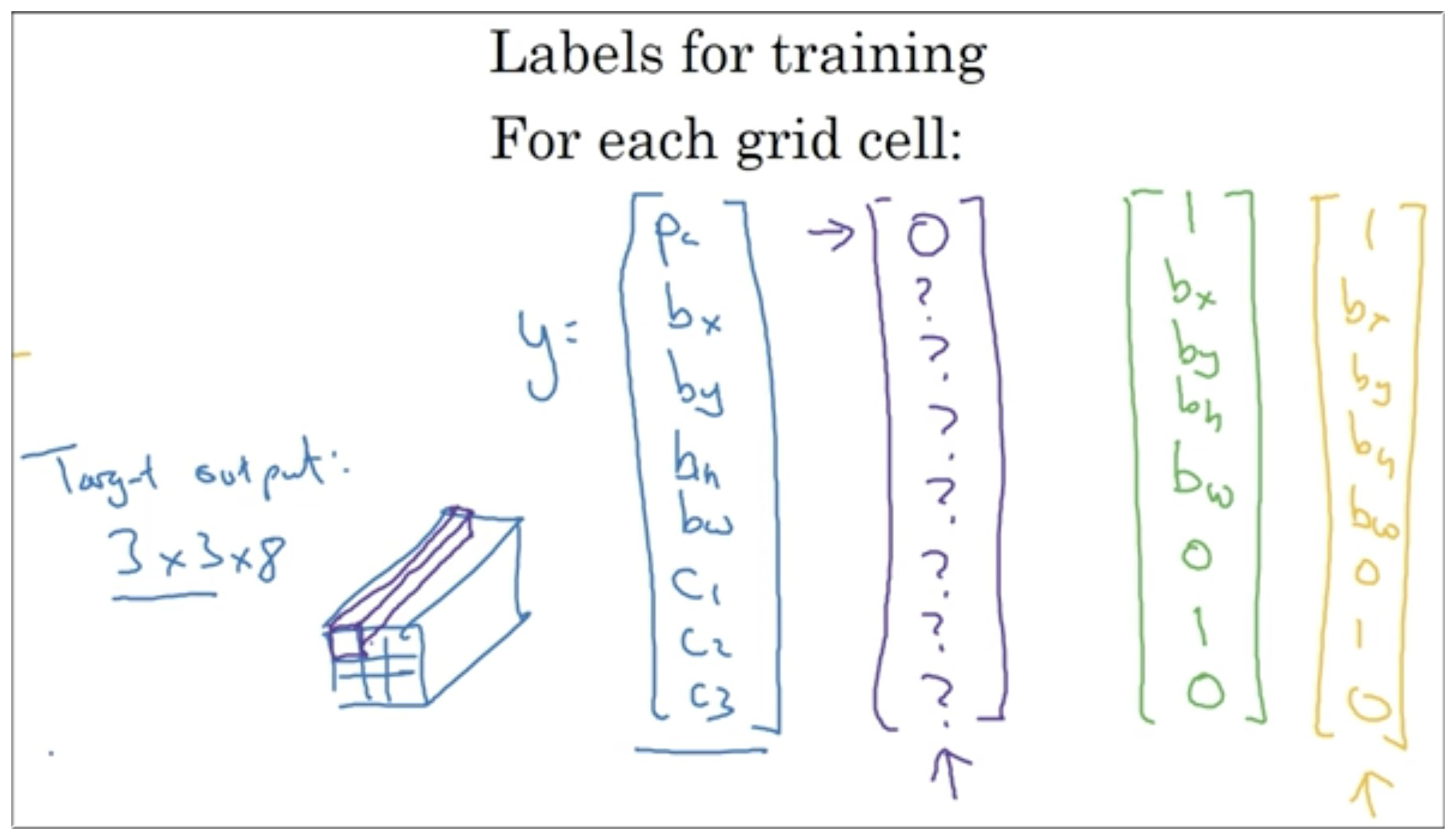
注意: 我们假设图像中存在这三者 (pedestrian,car,motorcycles) 中的一种 或者 都不存在,所以共有四种可能.
表示有三者中的一种
-
表示有 pedestrian,反之没有
-
表示有 car
-
表示有 motorcycles
b\_\* 用于标识所识别食物的位置
-
: 表示识别物体的中心坐标
-
: 表示识别物体的宽和高
注意: 表示三者都没有,所以此时 C\_\*,b\_\* 的值我们并不在乎了.
为了让大家便于了解对象定位的细节,这里我用平方误差简化了描述过程. (实际应用中 更多是应用逻辑回归函数)
2. Landmark Detection
特征点检测,这一节的内容和上一节感觉很类似.
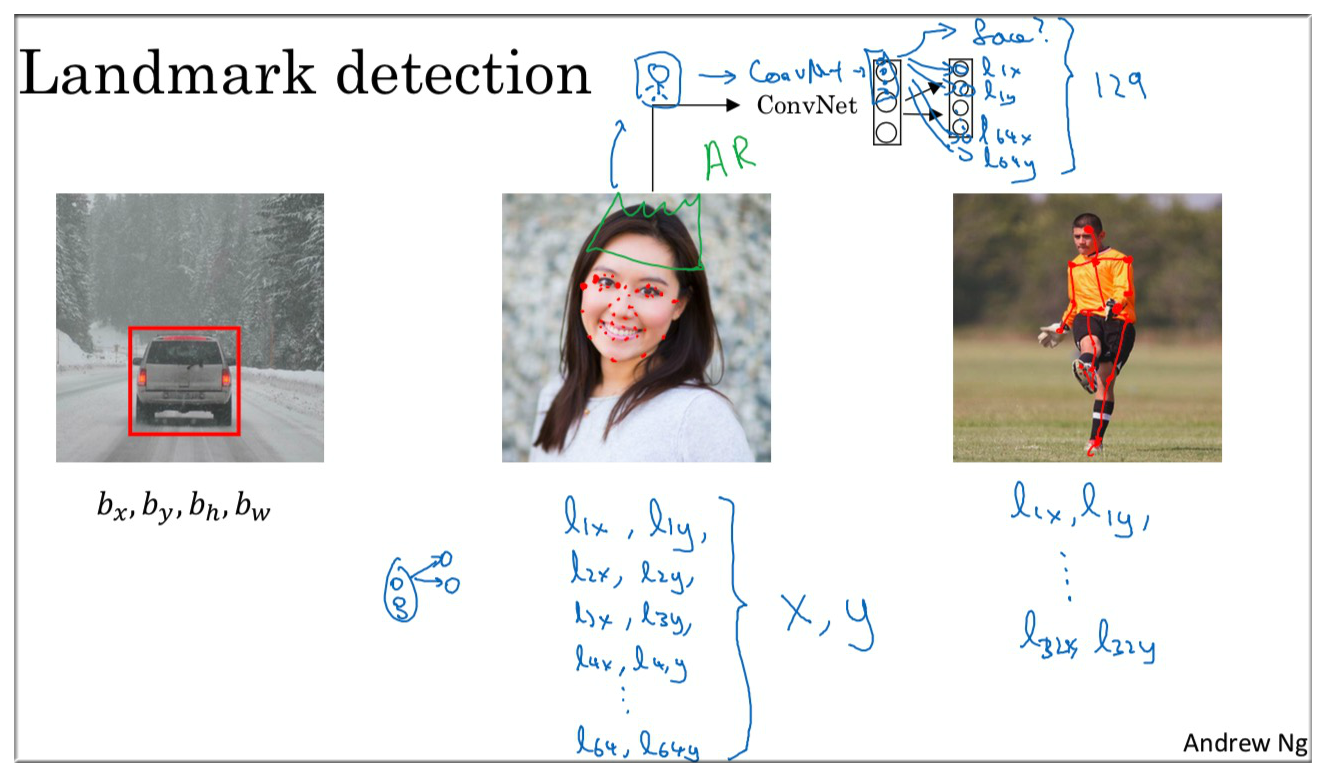
要输出眼角的位置,你可以让神经网络输出的最后一层,多输出 2 个数字 .
假设 脸部 有 64 个特征点. 具体做法是准备一个 CNN 和 一些关键特征集. 将人脸图片输入 CNN. 输出 1 或者 0.
1 表示有 人脸。 这里一共有 128 + 1 个输出单元,因为有 64 个特征 64 * 2, 来实现对人脸的检测和定位.
Snapchat 应用,AR (Augmented Reality) 增强现实 Filter 有所了解,Snapchat Filter 实现了在人脸上画皇冠 还有一些其他效果。检测脸部特征也是计算机图形学的关键构造模块.
最后一个例子是,检测人体姿态.
3. Object Detection
假设你想构造一个汽车检测算法:
- 首先,创建一个标签训练集 Training Set, 也就是 和
- 选定一个大小确定的窗口,输入 CNN,CNN 开始预测红色方框中是否有汽车.
- 然后,滑动窗口继续, 红色方框稍向右滑动之后的区域, 处理下一个,输入 CNN…
- 依次重复操作…, 知道这个红色的窗口滑过每一个角落。
- 如果上面到最后角落还是没有检测到汽车, 那么选用更大的窗口,然后还是以固定步长…依次重复…滑过…检测
这个算法叫做 : 滑动窗口目标检测

目标检测常使用的是滑动窗口技术检测,即使用一定大小的窗口按照指定的步长对图像进行遍历

因为图像中车辆的大小我们是不知道的,所以可以更改窗口大小,从而识别并定位出车辆的位置。


滑动窗口目标检测 算法的缺点就是计算成本的问题.
- 如果你把窗口调大,显然会减少输入CNN的窗口个数,但是粗粒度可能会影响性能.
- 如果采用小粒度,那么输入给CNN的窗口个数就会特别多。这意味着超高计算成本.
人们通常采用更简单的分类器做对象检测. 比如简单的线性分类器. 计算成本就会很低. 滑动窗口算法表现良好. 然而 CNN 运行单个分类任务的成本确高得多。 这样的滑动窗口太慢了。
庆幸的是,人们已经找到了方法解决计算成本,下一节见.
4. Convolutional Implementation of Sliding Windows
注意:该节视频的例子和上一节一样,都是识别图像中是否有 pedestrian,car,motorcycles,background,所以最后输出y是 4个节点
4.1 全连接层→卷积层
在介绍卷积滑动窗口之前我们首先要知道如何把神经网络的全连接层转化成卷积层,下面是使用了全连接层的网络结构

那么如何将全连接层转化成卷积层呢?如下图示
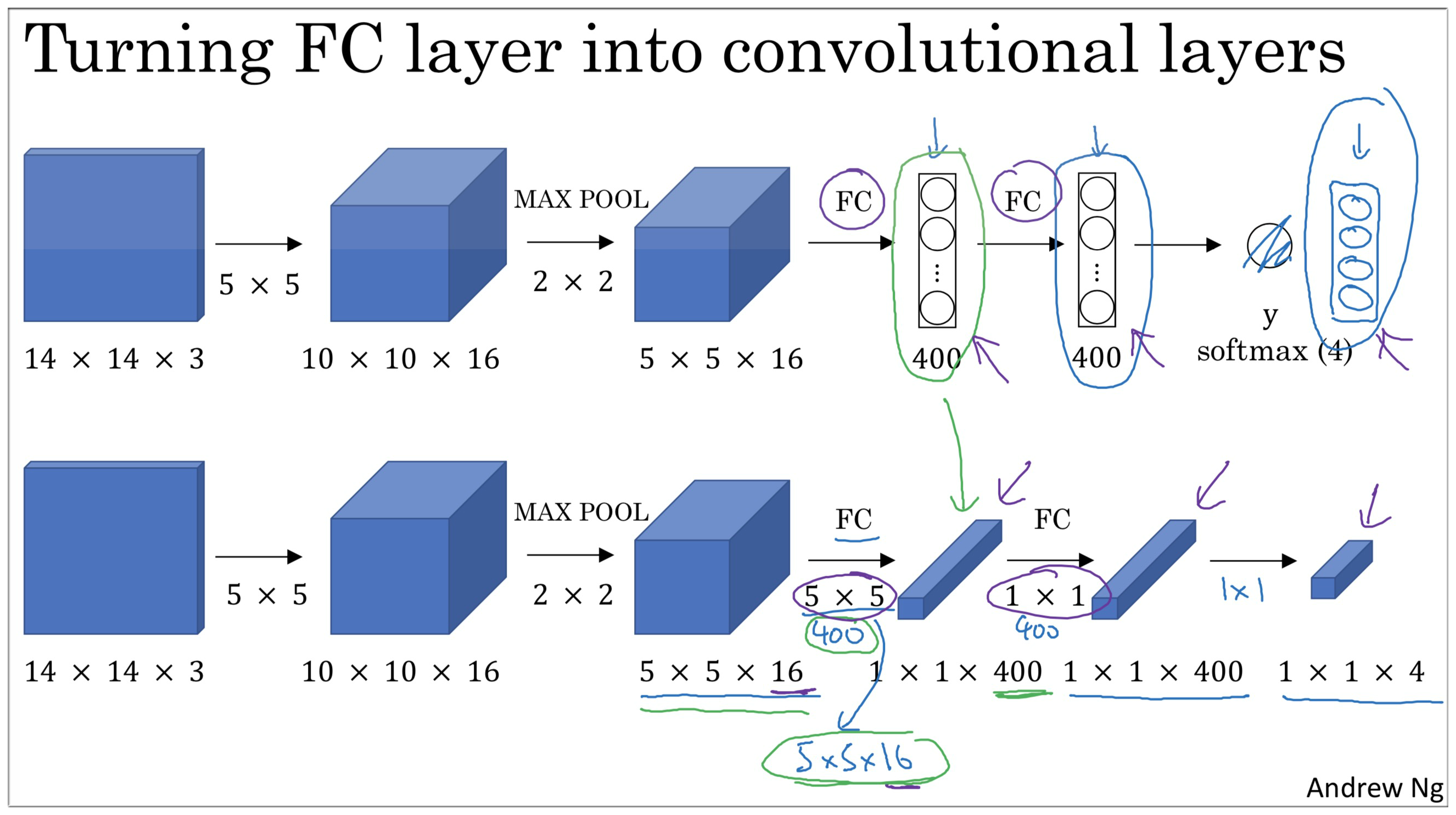
我们可以看到经过 Max Pooling 之后的数据大小是 (5, 5, 16), 第一个FC层是 400 个节点。我们可以使用 400 个 5*5 的过滤器进行卷积运算,随后我们就得到了 (1, 1, 400) 的矩阵。
第二个 FC层 也是 400 个节点,由之前的 1*1 过滤器的特点,我们可以使用 400 个 1*1 的过滤器,也可以得到 (1,1,400) 的矩阵。至此,我们已经成功将全连接层转化成了卷积层。
以上就是用卷积层代替全连接层的过程, 下面再看如何通过卷积实现滑动窗口对象检测算法,借鉴 OverFeat Paper。
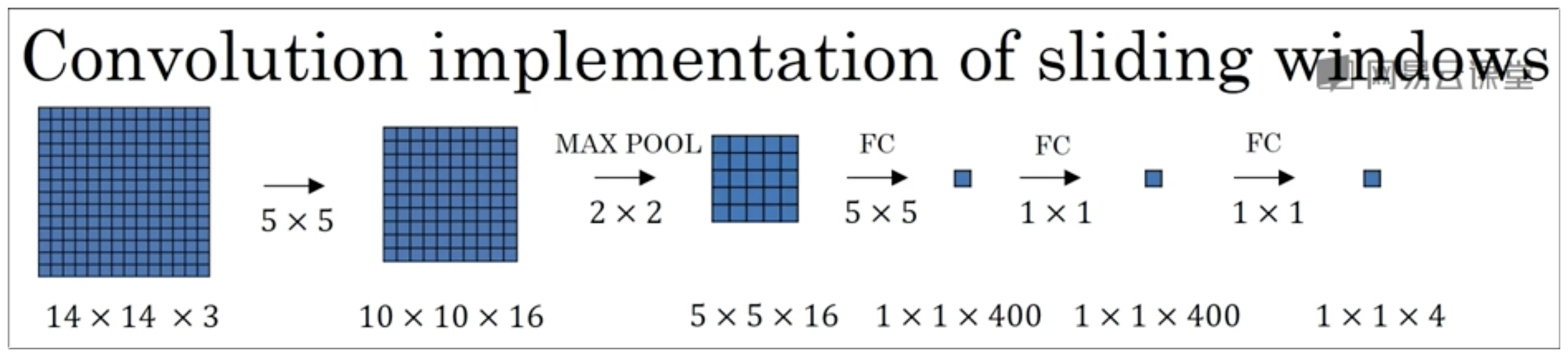
4.2 卷积滑动窗口实现
目标检测一节中介绍了滑动窗口。要实现窗口遍历,那么就需要很大的计算量,But 大神们自然已经有了解决办法。
注意: 下面的第一幅图,Andrew Ng 为了方便只花了平面图,就没有画出3D的效果了。
首先我们先看下图,这就是上面提到的将全连接层转化成卷积层的示意图:
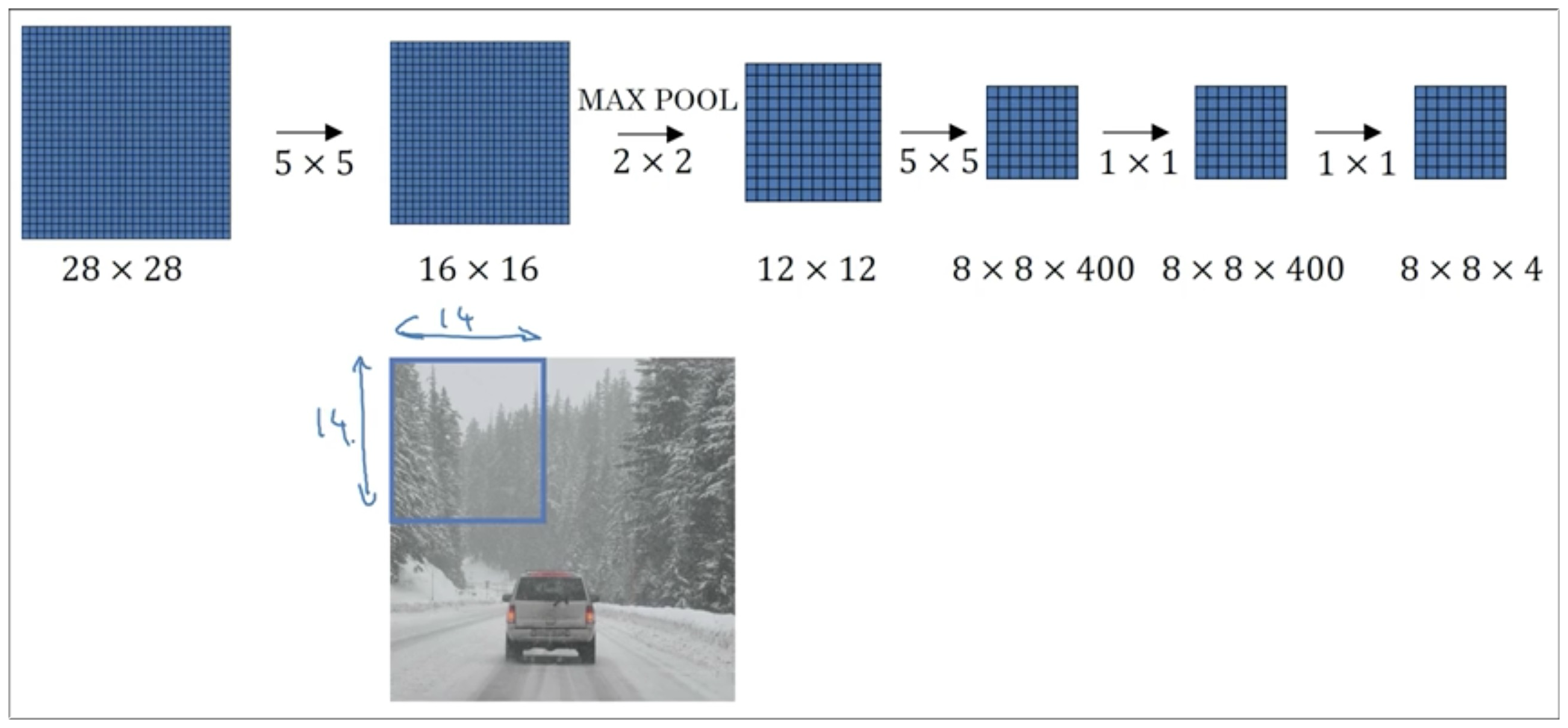
下面,假设我们的测试图大小是 16*16,并令滑动窗口大小是 14*14 的 (为了方便理解,下图用蓝色清楚地表明了 14*14 窗口的大小), 步长是 2,所以这个测试图可以被窗口划分成 4 个部分。随后和上面执行一样的操作,最后可以得到 (2,2,4) 的矩阵(这样发现很多计算部分是重复的),此时我们不难看出测试图被滑动窗口选取的左上角部分对应的结果也是输出矩阵的左上角部分,其他3个部分同理。

所以这说明了什么?
说明我们没有必要用滑动窗口截取一部分,然后带入卷积网络运算。相反我们可以整体进行运算,这样速度就快很多了。
下图很清楚的展示了卷积滑动窗口的实现。我们可以看到图片被划分成了 64 块
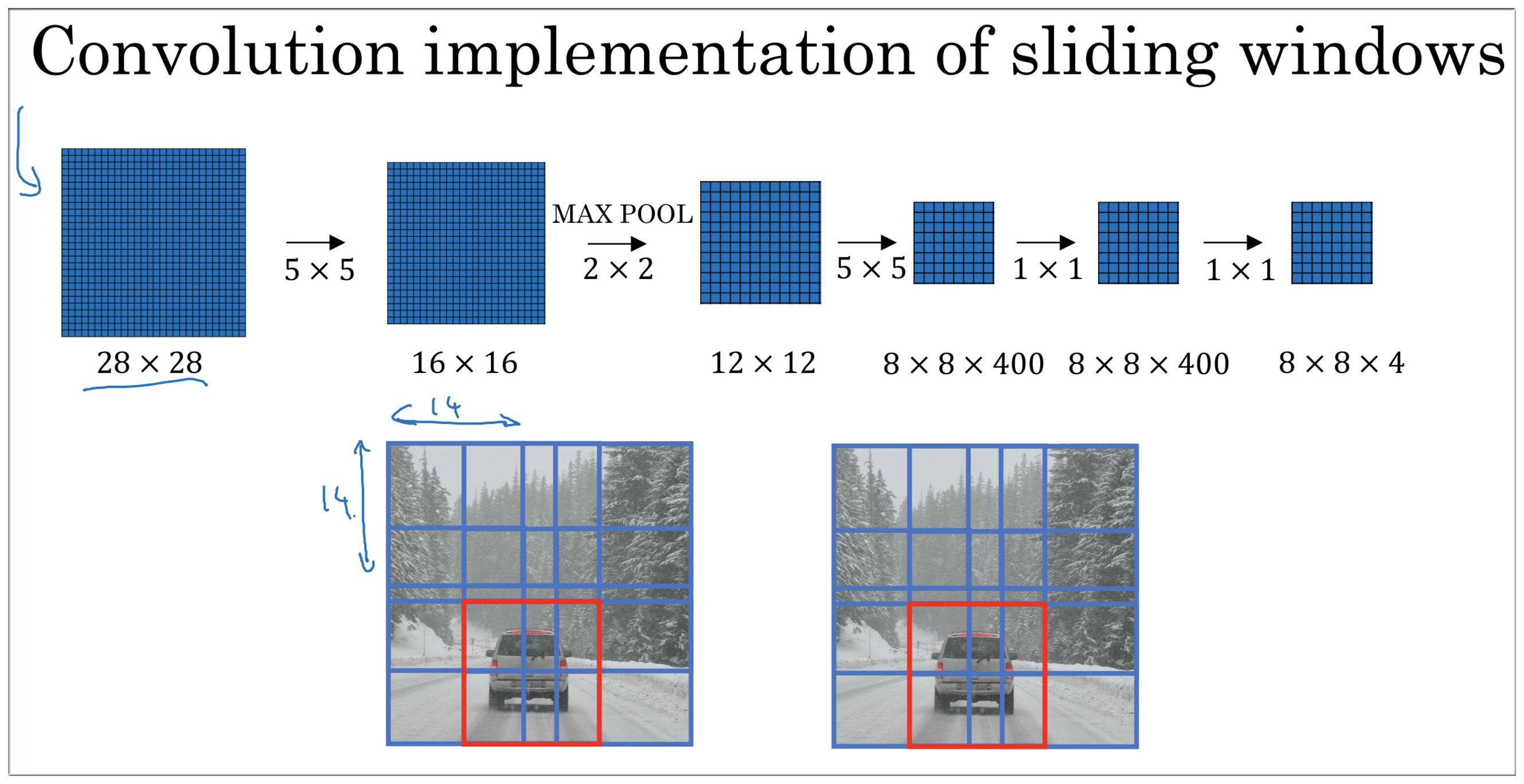
目前这个算法还有一个缺点,就是边界框的位置可能不够准确,下一节,我们将学习解决这个缺点。
5. Bounding Box Predictions
上面介绍的滑动窗口方法存在一个问题就是很多情况下滑动窗口并不能很好的切割出车体,如下图示:

上面中的蓝色框可能是滑动窗口的时候,最佳的匹配位置了,但是其实我们人看后,其实很明显发现,这并不是,这就是我们要解决的问题所在. 其实最佳的匹配位置应该是红色的框,稍微有点长方形,长宽比有点向水平方向延伸.
为了解决这个问题,就有了 YOLO (you only look once) 算法,即只需要计算一次便可确定需要识别物体的位置的大小。
原理如下:
首先将图像划分成 3*3 (即9份),每一份最后由一个向量表示,这个向量在本文最前面介绍过,即
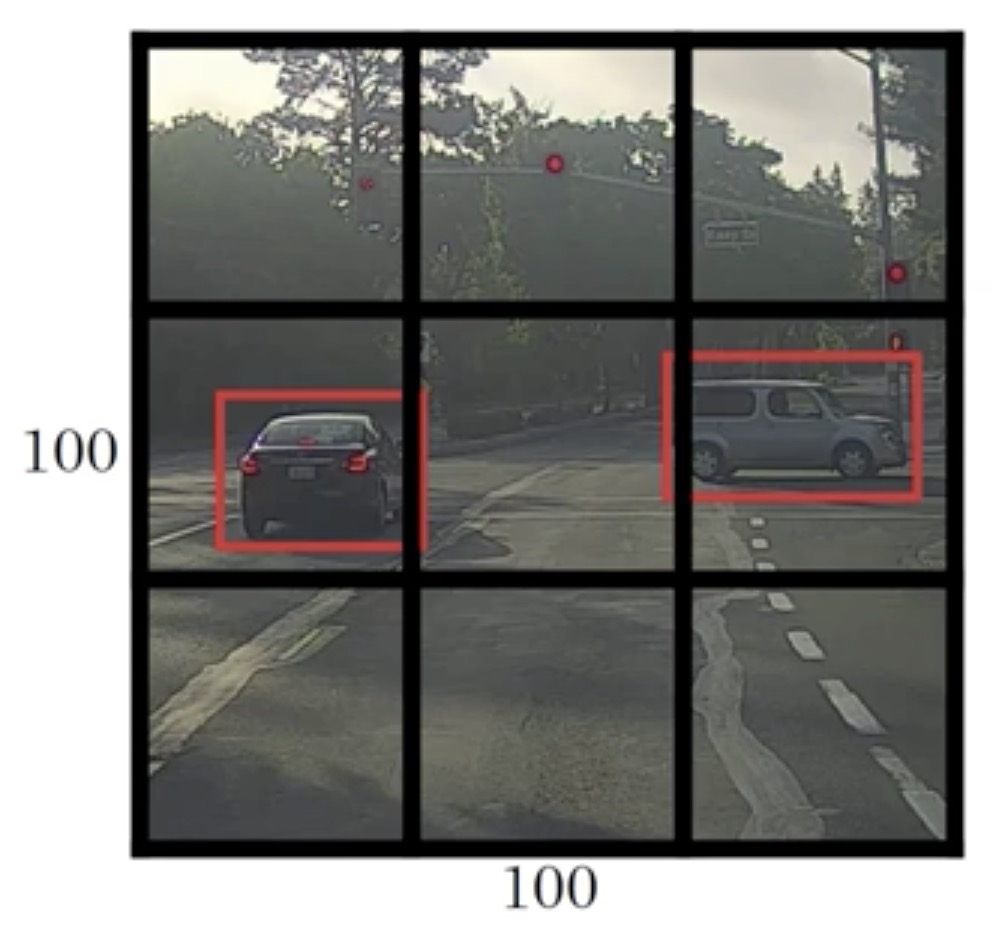
如果一个格子中有两个对象,那么就当做这个格子中不存在对象. 按照 处理.
(如果是 19 * 19 的情况,两个对象的中点分配到一个格子的情况,其实特别低)
因为有 9 份,所以最后输出矩阵大小是 (3,3,8) , 如下图示:
那么如何构建卷积网络呢?
输入矩阵是 (100, 100, 3), 然后是 Conv,Maxpool 层,……,最后只要确保输出矩阵大小是 (3,3,8) 即可。
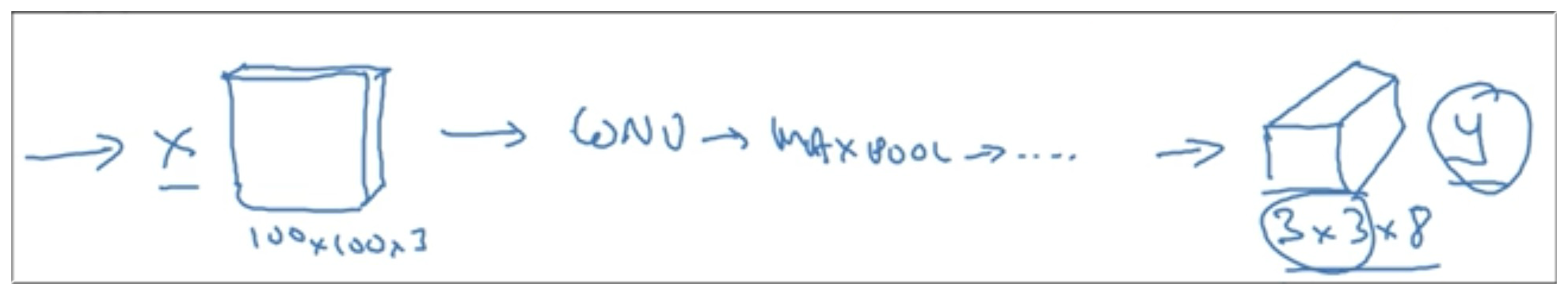
这是一个卷积实现,你并没有在 3 * 3 网格上跑 9 次算法,19 * 19 同样你不需要网格上跑 361 次,相反这是单次卷积的实现,但你使用了一个卷积网络,有很多共享计算步骤,比如在处理这 3 * 3 计算中很多计算步骤是共享的. 所以这个算法的效率很高.
YOLO 算法有一个好处是,它的计算特别快,可以达到实时识别。
下图是以右边的车辆作为示例介绍该车辆所在框的输出矩阵
- 很显然
- 然后 的值是右边车辆的中心点相对于该框的位置,所以它们的值是一定小于 1 的,我们可以很容易的得到近似值
- 的值同理也是车辆的宽高相对于其所在框的比例,但是要注意的是这两个值是可以大于 1 的,因为有可能部分车身在框外。但是也可以使用 sigmoid函数 将值控制在 1 以内。
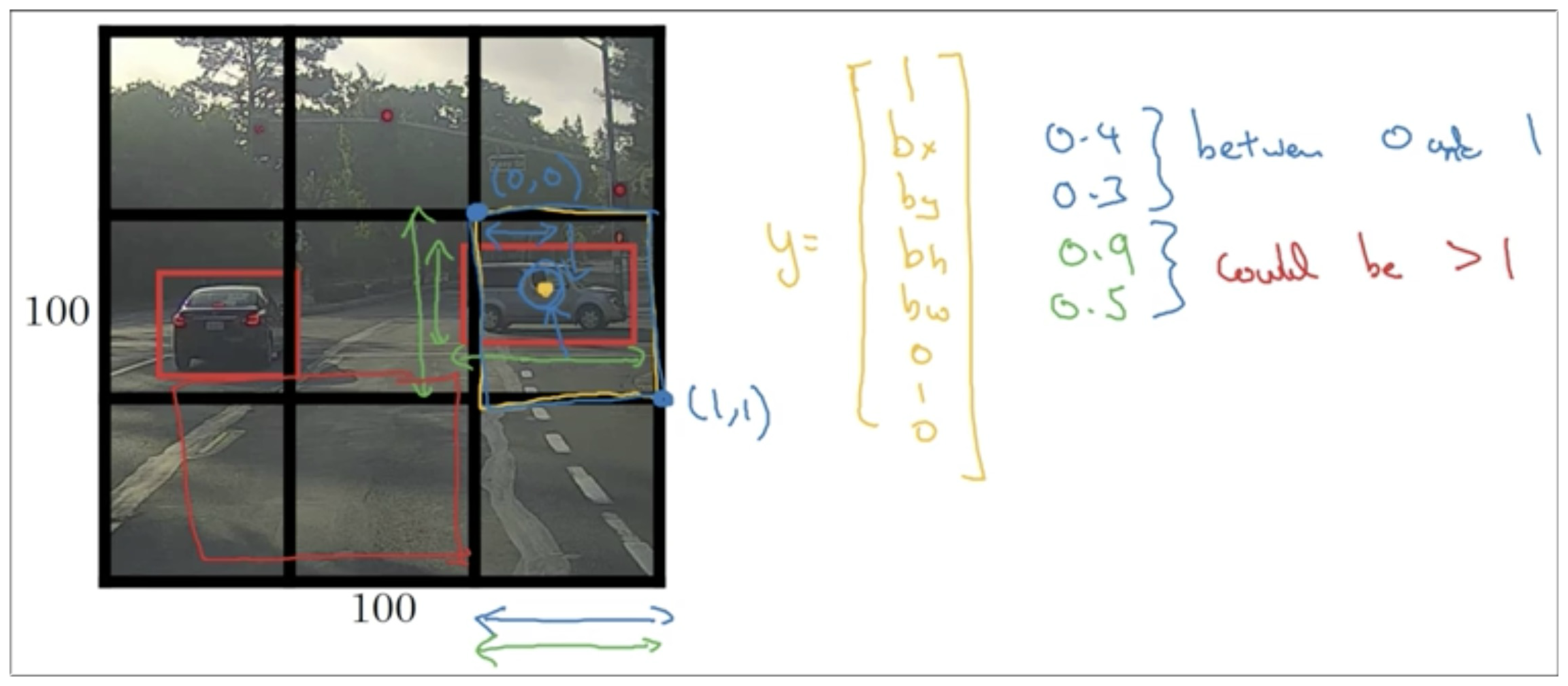
这里我用 3 * 3 的网格说明,在实践中可能 19 * 19 的网格会精细的多.
避免把 多个 对象分配到同一个格子中,观察这个对象的中点,然后将图像对象分配到其中点所在的格子. 19 * 19 的网格, 两个对象的中点处于同一个格子的概率会更低.
上面吴大大给出的是一个合理的约定,使用起来应该没什么问题. 其实还有其他更复杂的参数化形式.
YOLO 的论文是相对难度较高的论文, Andrew Ng 看的时候也看不懂很多.
6. Intersection Over Union
如何评价对象检测算法呢,IOU 交并比函数可以用来评价对象检测算法。
前面说到了实现目标定位时可能存在 滑动窗口 与 真实边框 存在出入,如下图示:

红色框是车身边界,紫色框是滑动窗口,那么此窗口返回的值是有车还是无车呢?
为了解决上面的问题引入了交并比(IoU),也就是两个框之间的交集与并集之比,依据这个值可以评价定位算法是否精准。

上图黄色区域表示紫色框和红色框的交集,绿色区域表示紫色框和红色框的并集,交并比(IoU)就等于 黄色区域大小 比上 绿色区域大小。
如果 ,则表示紫色框中有车辆,反之没有。
当然 0.5 这个阈值是人为设定的,没有深入的科学探究,所以如果希望结果更加精确,也可以用 0.6 或 0.7 设为阈值,但是不建议用小于 0.5 的阈值。
下一节讨论这个 Non-max Suppression 工具,可以让 YOLO 工作的更好
7. Non-max Suppression
非极大值抑制可以确保你对每个对象只检测一次。
算法大致思路
前面 Bounding Box 一节中介绍到将图片划分成若干等分,例如 3*3,那么一共就有9块,如下图示,我们可以很清楚的看到第二行第一块和第三块都有车,所以可以标出一个中心点坐标 ,这样我们就能通过最终的输出结果知道这两个框中有车。
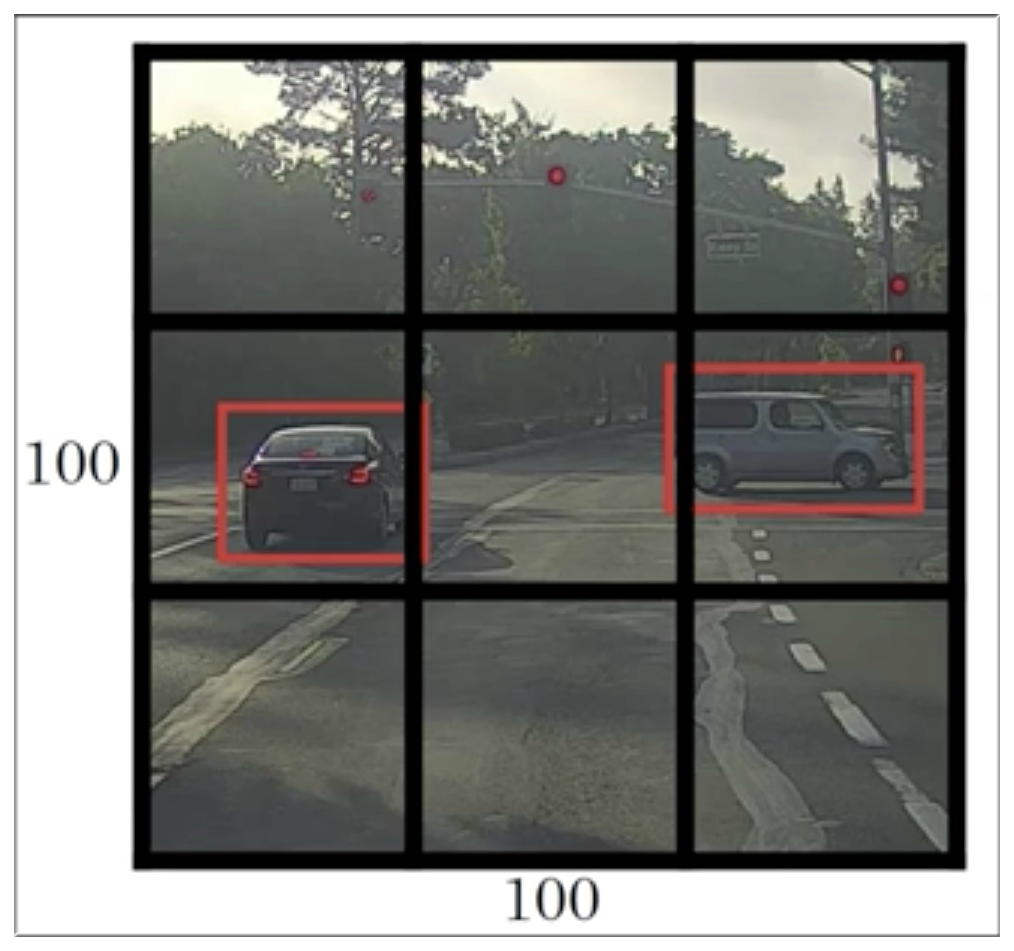
但是如果我们划分的数量变多之后呢?如下图示划分成了 19*19,图中标出的 3 个黄框和 3 个绿框最终结果都会都会返回[],但是最后我们该信谁的呢?是这三个框真的有车,而且还不是同一辆车?还是只是同一辆车?所以就有了非极大值抑制来解决这个问题。

Non-max Suppression 做的就是清理这些检测结果,这样一辆车只检测一次,而不是每辆车都出发多次检测。
其思路大致如下 (为了方便说明和理解,我们不使用 19*19 的方框):
首先每个框会对是否有目标返回一个 的概率值 (也可以是 P\_c\*C\_1\*C\_2\*C\_3 的概率之积),如下图示:
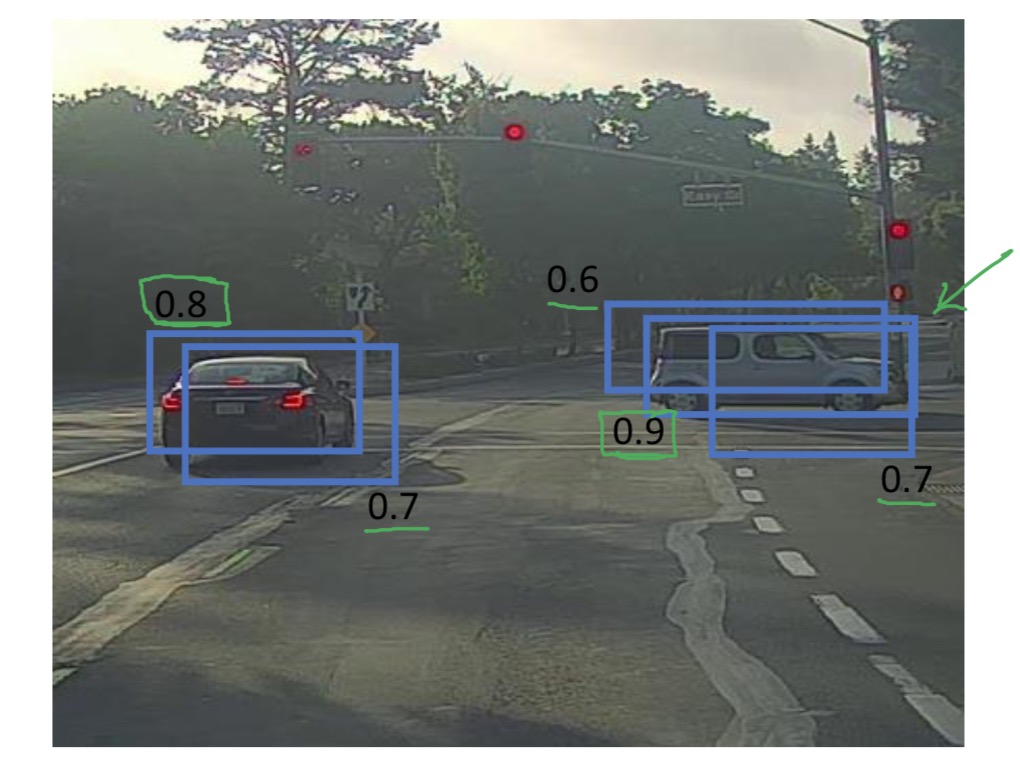
然后找到 最大的一个框,显然 0.9 的框有车的概率最大,所以该边框颜色高亮
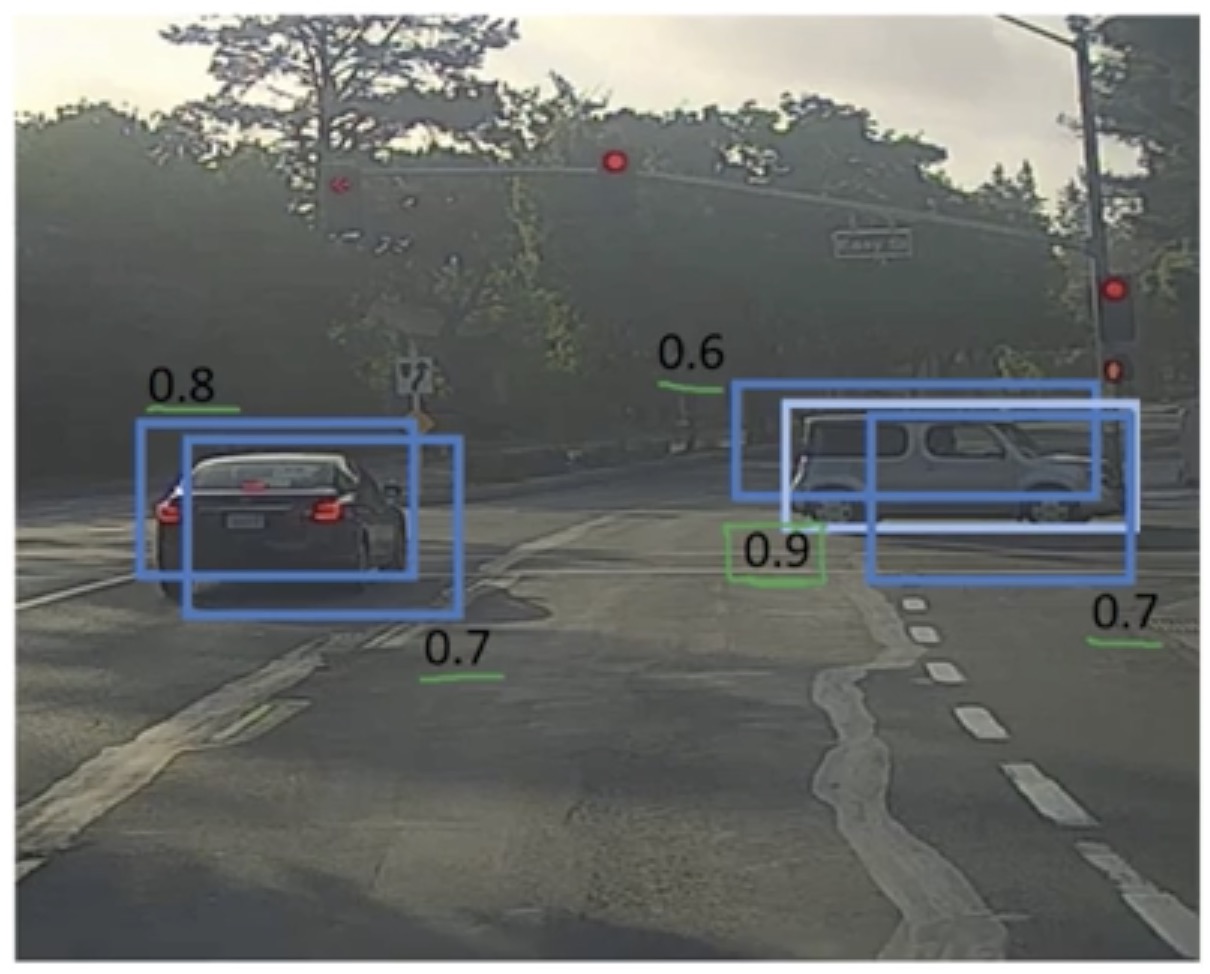
然后算法遍历其他边框,找出与上一个边框的交并比大于 0.5 的边框,很显然右边剩余两个边框符合条件,所以这两个边框变暗
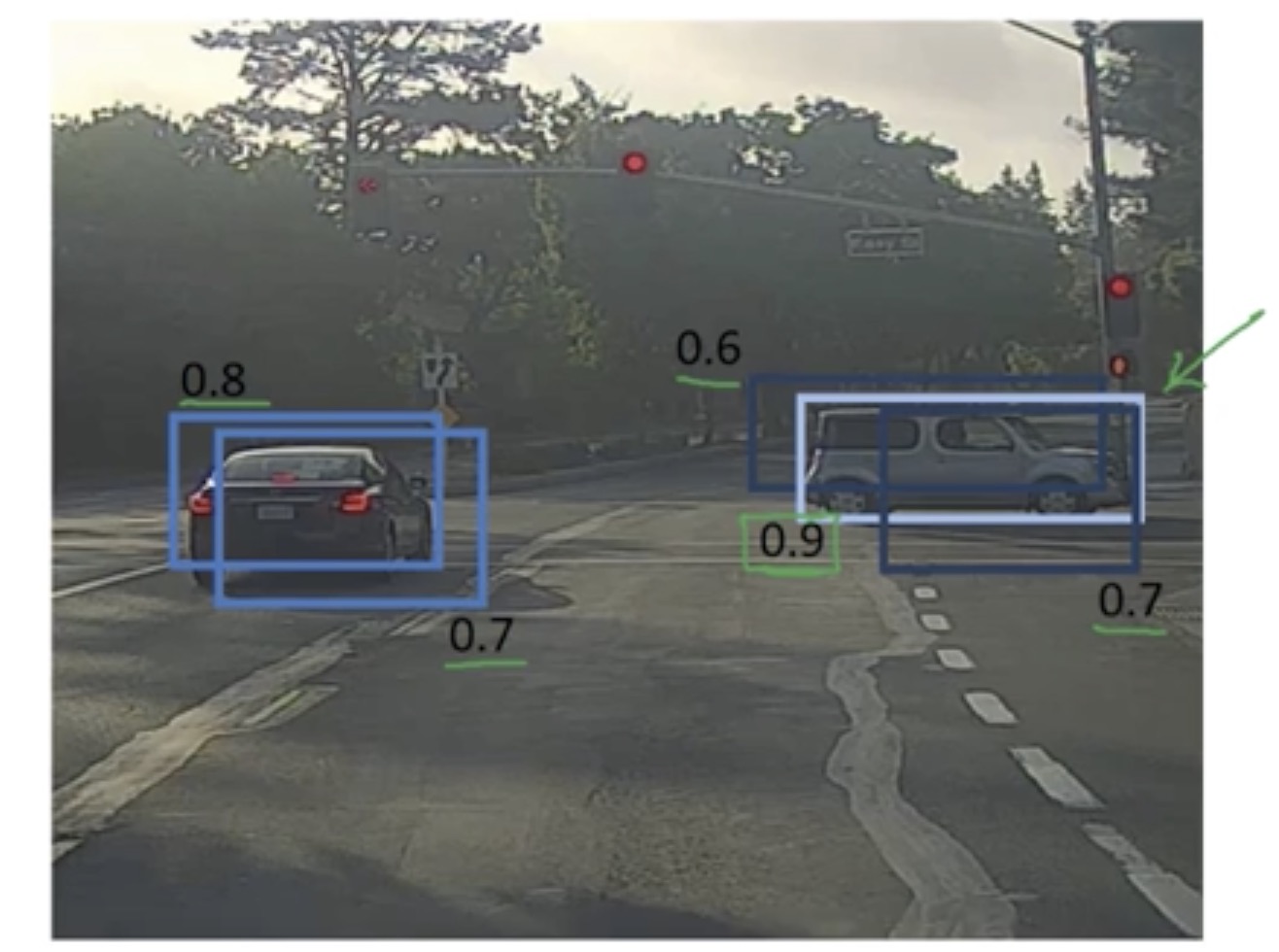
左边的车同理,不加赘述
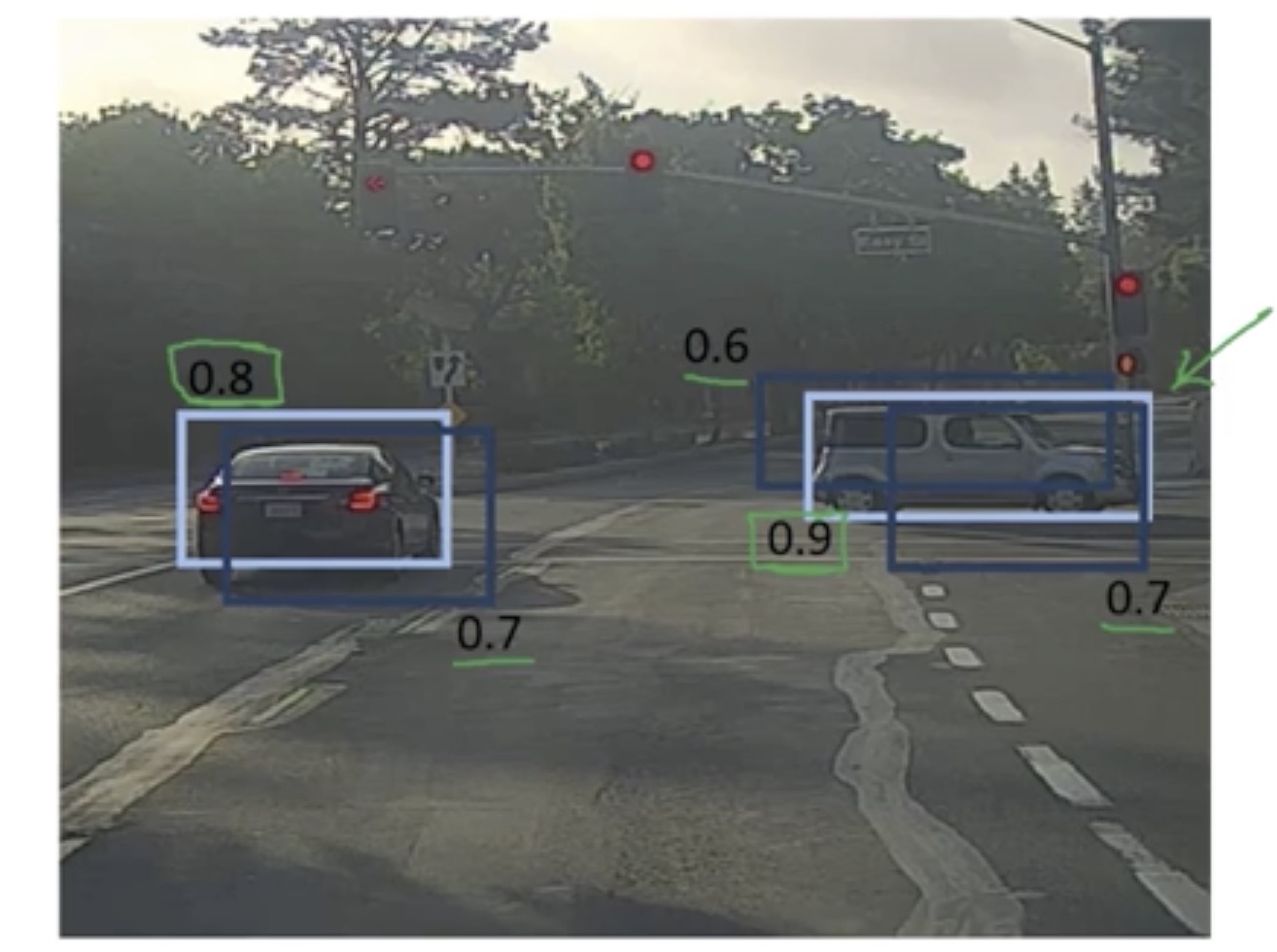
下面结合一个例子总结一下 非极大值抑制 算法的实现步骤:
在这里假设只需要识别定位车辆即可,所以输出格式为

这个例子中将图像划分成 19*19 方格,假设每个方格都已经计算出 的概率值
- 去掉所有满足 的方格 (0.6也可以进行人为修改)
- 对剩下的方格进行如下循环操作:
- 从剩下的方格中选取 最大的一个作为预测值输出,假设这个方格为
- 将与 方格交并比大于 0.5 的剔除
8. Anchor Boxes
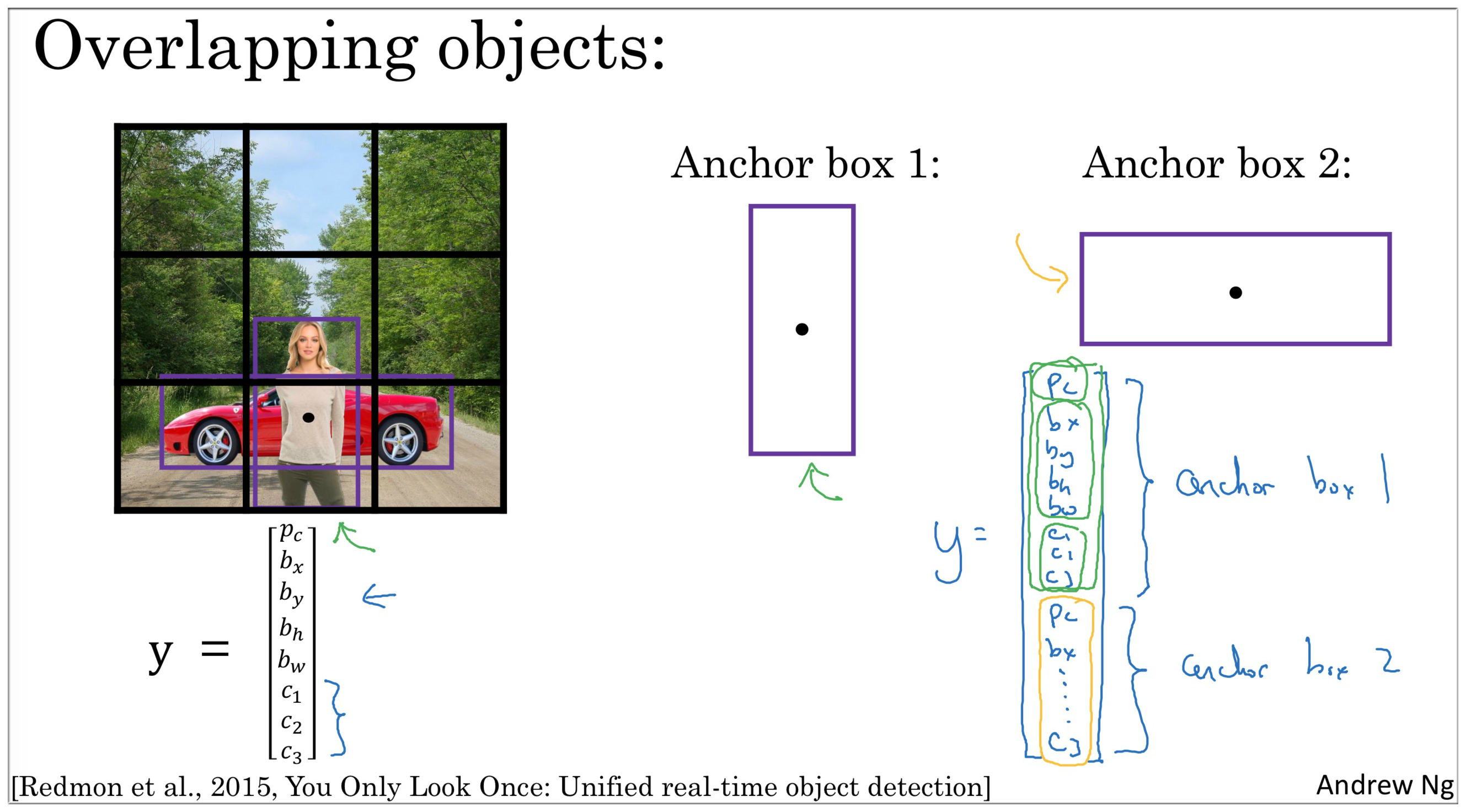
前面介绍了那么多,都只是识别单个物体,如果要同时识别多个物体该怎么办呢?而且识别的不同物体的中心点在同一个框中又该怎么呢 (如下图示,人和车的中心都在红点位置,处于同一个框中)?这时就需要使用 Anchor Boxes 了。

Anchor Boxes 思路是对于不同物体事先采用不同的框,例如人相对于车属于瘦高的,所以使用下图中的 Anchor Box 1,相反车辆就使用** Anchor Box 2**.
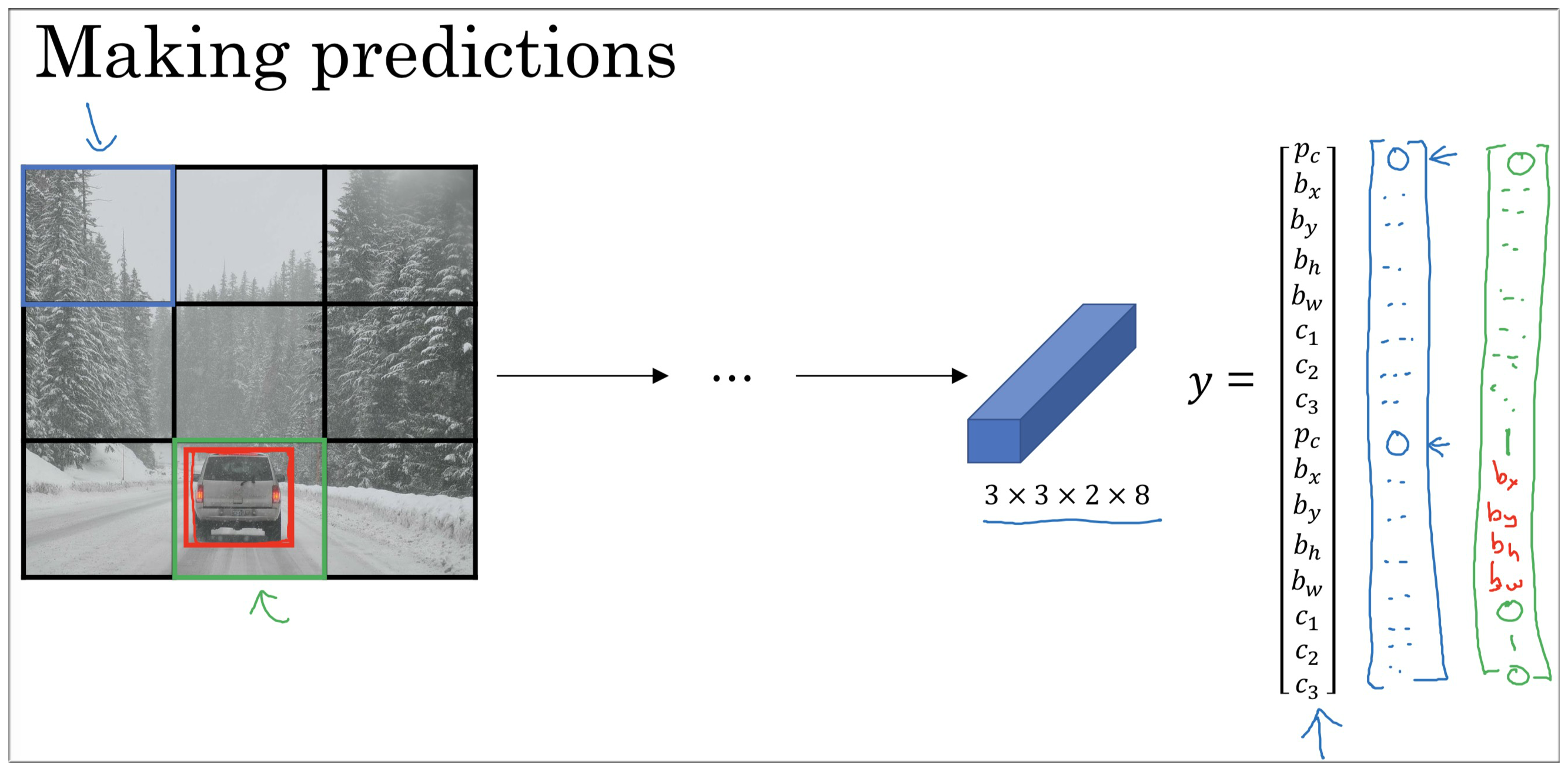
之前的输出值的格式都是 y=[P\_x,b\_x,b\]_y,b\_h,b\_w,C\_1,C\_2,C\_3],最后输出的矩阵大小(以该图为例) 是 (3,3,8), 但是这样只能确定一个物体。
所以为了同时检测不同物体,很自然的我们可以重复输出这个上面的值即可,即 , 所以输出矩阵是 (3,3,16), 也可以是(3,3,2,8)。
要注意的是我们需要提前设定好输出值前面的值对应 Anchor Box 1,后面的对应 Anchor Box 2.
例如我们得到了图中人的边框信息值,然后经过计算发现其边框与 Anchor Box 1更为接近,所以最后将人的边框信息对应在前面,同理车辆边框信息对应在后面。
总结起来 Anchor Box算法 和 之前的算法区别如下:
之前的算法:
对于训练集图像中的每个对象,都根据那个对象的中点位置分配到对应的格子中,所以在上面的示例中输出y就是(3,3,8)
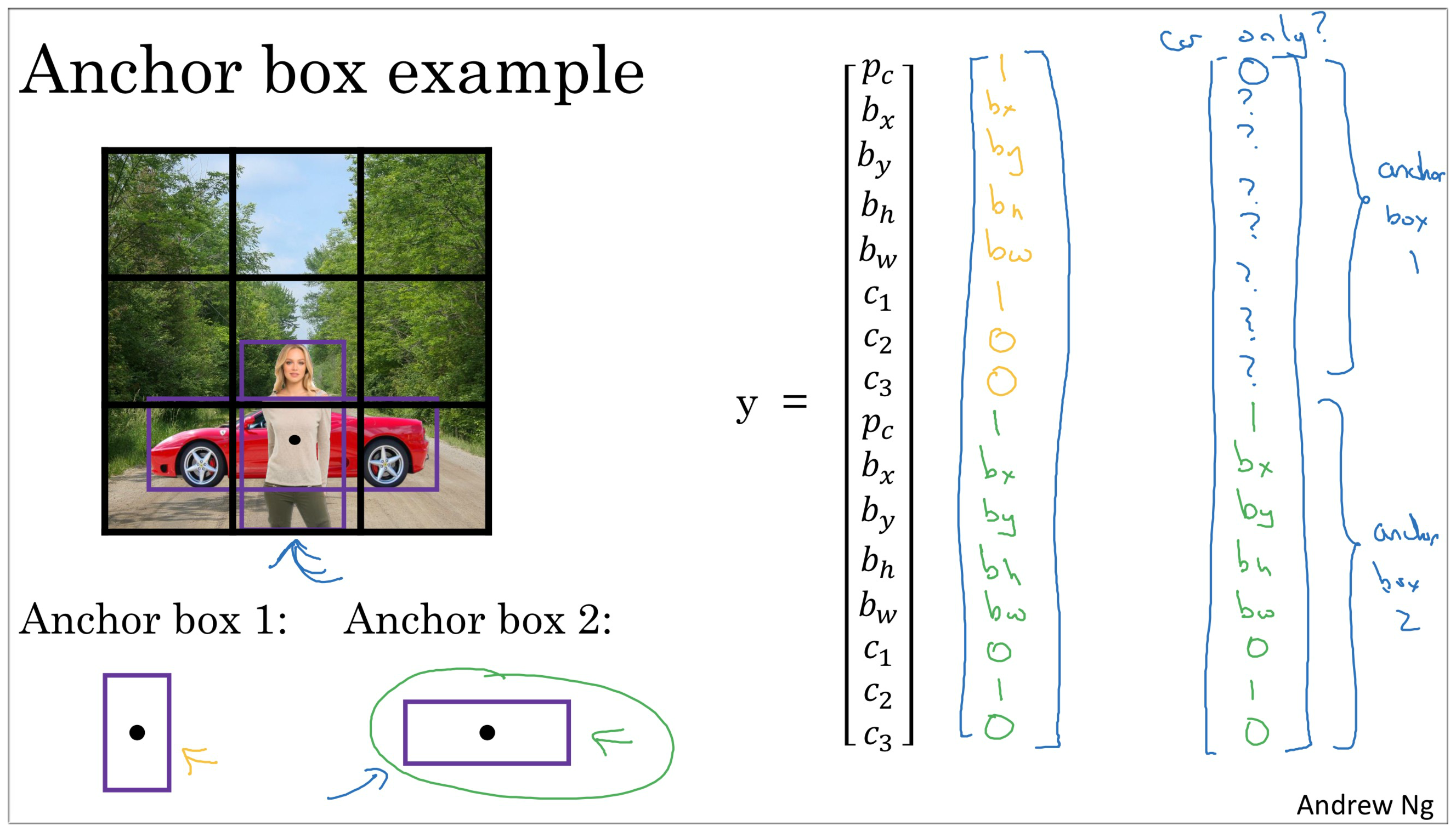
Anchor Boxes 算法
现在每个对象都和之前一样分配到同一个格子中, 即对象中心所在的格子。不同的是也需要分配到和对象形状交并比最高的 Anchor Box。
例如下图中的红色框不仅要分配到其中心所在的图像上的格子中,而且还需要分配到与其交并比最大的 Anchor Box 中,即竖条的紫色方格。

回到本小节最开始的例子,最后的输出值如下图示:
图中人的对应 Anchor Box 1, 输出值对应图中的黄色字体;车辆同理,对应绿色字体
如果两个对象所在一个格子,且两个对象圈出来的框也是一样的,这种情况非常非常少见,我们用其他方法来特殊处理.
9. YOLO Algorithm
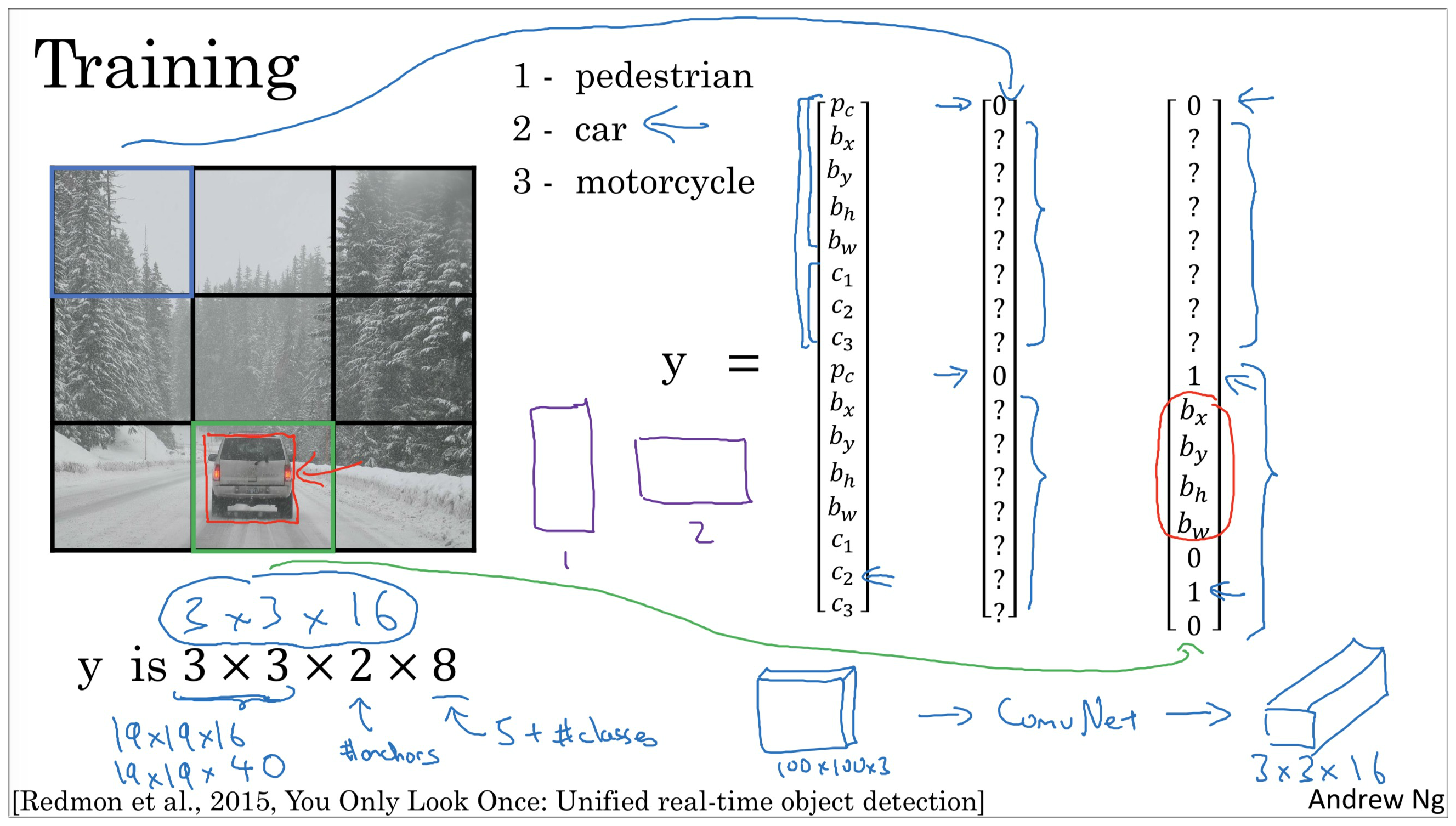

YOLO Algorithm, that also encompasses many of the best ideas across the entire computer vision literature the relate to object detection.
YOLO 计算机视觉对象检测领域文献中最精妙的思路。
10. Region Proposals (Optional)
候选区域,这些目前工作其实用的很少,但是还是非常有意义的,所以我作为可选视频可学习.

吴大大认为 YOLO 这种只看一次的算法,长远而言是CV领域更有希望的方向
Checking if Disqus is accessible...