Chatbot Research 6 - 更多论文 (感谢 PaperWeekly)
Chatbot 更多 Paper 论文和参考资料 (感谢 PaperWeekly)
Paper 1
《A Neural Conversational Model》
代码: https://github.com/Conchylicultor/DeepQA 2128 star
- 作者: 来自 Google Brain,毕业于 UC Berkeley 的 Oriol Vinyals博士
- 对比 cleverbot (第二代基于检索的聊天机器人),部分回答 更智能。
- 如何客观地评价生成的效果? 有一些问题没有标准答案 来说,自动评价 VS 用户评价
作者对一些评估方法提出了一些自己的思考方式
DeepQA
- chatbot 训练的部分
- chatbot_website 服务的部分,网页端
DeepQA/chatbot/ 这几个文件比较重要
1 | from chatbot.corpus.cornelldata import CornellData |
语料太大的情况下,做一些采样或者层次化的 softmax 可行
1 | if 0 < self.args.softmaxSamples < self.textData.getVocabularySize(): |
Paper 2
《A Diversity-Promoting Objective Function for Neural Conversation Models》
- 作者: Jiwei Li, Jiwei Li’s Github
关于《A Persona-Based Neural Conversation Model》的pre-paper Seq2seq 容易产出”呵呵”,”都可以”,”我不知道”这种 safe 但无意义的回答
NLG 问题,常使用 MLE 作为目标函数,产出的结果通畅,但 diversity 差,可考虑 decoder 产出 n-best, 再 rank
- 提出 Maximum Mutual Information(MMI) 作为目标函数, 有 MMI-antiLM 和MMI-bidi 2种
Paper 3
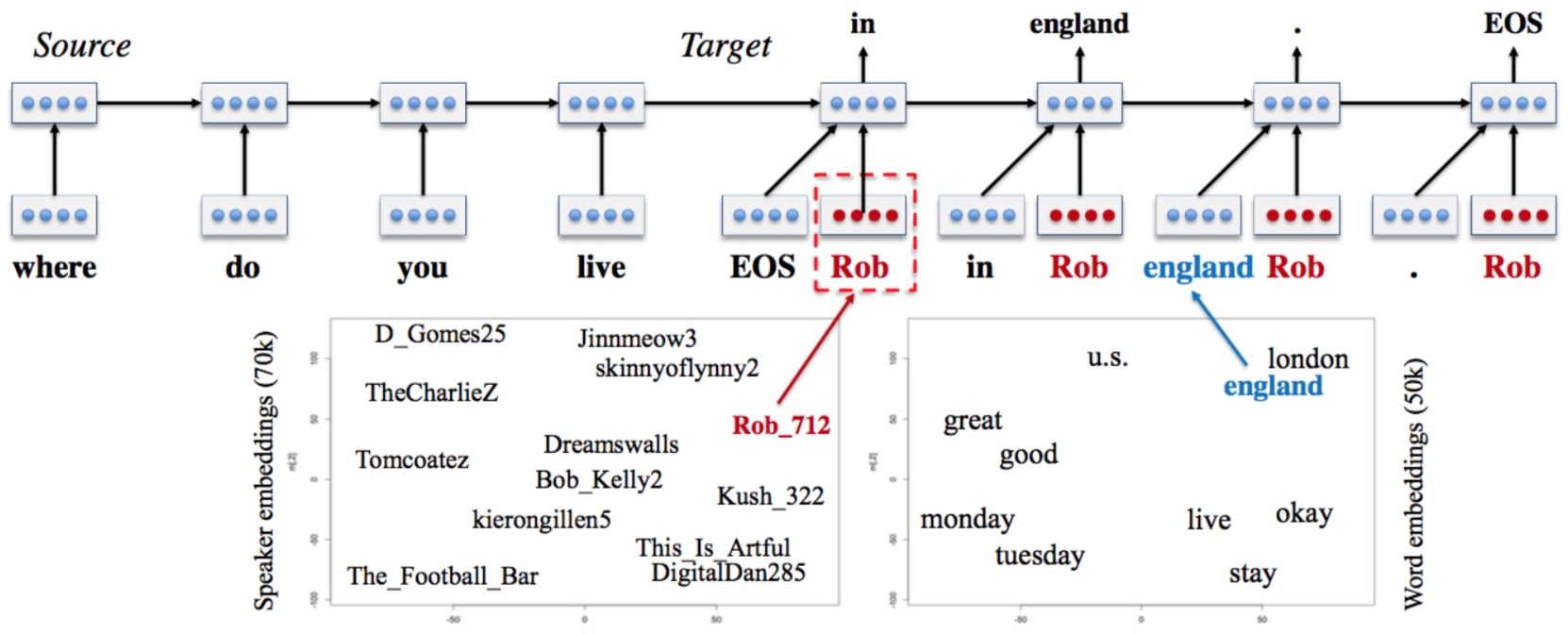
《A Persona-Based Neural Conversation Model》
- Speaker Model 和 Speaker-Addressee Model
- 作者: Jiwei Li, Jiwei Li’s Github
- 代码: https://github.com/jiweil/Neural-Dialogue-Generation
解决多轮对话回答不一致问题
Model 中融入 user identity (比如背景信息、用户画像,年龄等信息),构建出个性化的 seq2seq 模型,为不同的 user, 以及 同一个user 对不同的对象对话生成不同风格的 response
Paper 4
《A Hierarchical Latent Variable Encoder-Decoder Model for Generating Dialogues》
- 代码: https://github.com/julianser/hed-dlg-truncated
- 作者: 来自蒙特利尔大学和Maluuba公司
- 意在解决语言模型生成部分存在的问题
- 整个 seq2seq 框架中 decoder生成部分的问题,不仅是 bot领域对话生成的问题,都可以尝试用这个方式。
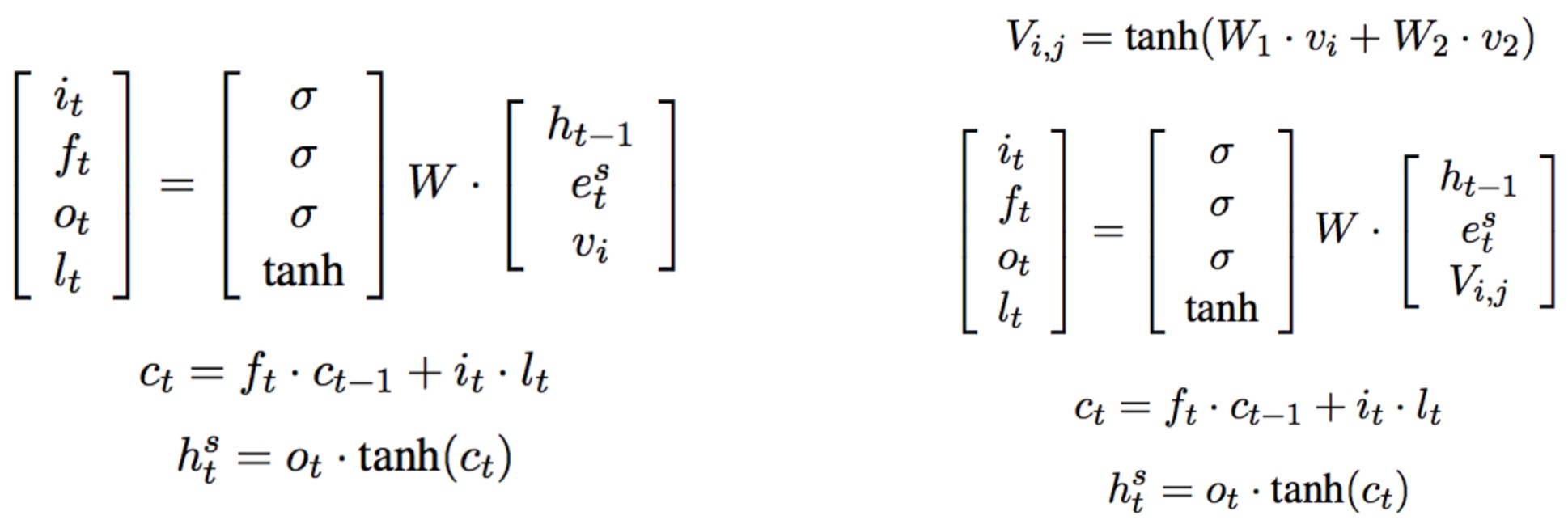
Paper 5
更多论文和参考资料(感谢PaperWeekly)
《End-to-end LSTM-based dialog control optimized with supervised and reinforcement learning》
http://rsarxiv.github.io/2016/07/17/End-to-end-LSTM-based-dialog-control-optimized-with-supervised-and-reinforcement-learning-PaperWeekly/《A Network-based End-to-End Trainable Task-oriented Dialogue System》
http://rsarxiv.github.io/2016/07/12/A-Network-based-End-to-End-Trainable-Task-oriented-Dialogue-System-PaperWeekly《A Neural Network Approach to Context-Sensitive Generation of Conversational Responses》
http://rsarxiv.github.io/2016/07/15/A-Neural-Network-Approach-to-Context-Sensitive-Generation-of-Conversational-Responses-PaperWeekly/- Sequence to Backward and Forward Sequences: A Content-Introducing Approach to Generative Short-Text Conversation
http://rsarxiv.github.io/2016/07/09/Sequence-to-Backward-and-Forward-Sequences-A-Content-Introducing-Approach-to-Generative-Short-Text-Conversation-PaperWeekly/
Reference
- 2015 DeepQA
- 聊天机器人深度学习应用-part1:引言
- dennybritz/chatbot-retrieval
- 更多论文和参考资料(感谢PaperWeekly)
Checking if Disqus is accessible...