Chatbot Research 1 - 聊天机器人的行业综述
英文原文: 《Deep Learning For Chatbots, Part 1 - Introduction》
中文翻译: 《聊天机器人中的深度学习导读》
这篇博文主要概述了目前聊天机器人主要用到的技术,从宏观上进行介绍,不涉及具体的技术细节。
聊天机器人 (Chatbot),也被称为对话引擎或者对话系统,是目前的热点之一。微软公司在聊天机器人上的投入巨大(链接),著名产品有小冰 (xiaoice)、bot framework等,其他公司也纷纷在这个领域发力,如Facebook的M,苹果公司的Siri等等。此外,一大批的创业公司发布了类似的产品,例如客户应用Operator,x.ai,bot framework Chatfuel,bot开发工具 Howdy’s Botkit。微软也发布了供开发者使用的 bot developer framework
还有一些应用案例,列举如下:
- 案例:语音助手 Siri
- 案例:餐饮 Pizza Hut
- 案例:健身 Fitness Tips
- 案例:旅游 expedia
- 案例:医疗 healthtap
- 案例:新闻 wordpress
- 案例:财经 meetcleo
许多公司希望能开发出与用户进行自然语言式对话的机器人,并且声称使用了NLP和深度学习相关技术使之成为可能,然而这并不容易实现。在这个博文系列中,我将会重温一些被用于聊天机器人中的深度学习技术,披露出目前技术能够解决或者可能解决的问题以及几乎难以解决的问题。这篇文章是个概述,在接下来的博文中将介绍具体的技术细节。
1. 模型分类
1.1 检索技术模型 VS 生成式模型
基于检索技术的模型较为简单,主要是根据用户的输入和上下文内容,使用了知识库(存储了事先定义好的回复内容)和一些启发式方法来得到一个合适的回复。启发式方法简单的有基于规则的表达式匹配,复杂的有一些机器学习里的分类器。这些系统不能够生成任何新的内容,只是从一个固定的数据集中找到合适的内容作为回复。
生成式模型则更加复杂,它不依赖于预定义好的回复内容,而是通过抓取(Scratch)的方法生成新的回复内容。生成式模型典型的有基于机器翻译模型的,与传统机器翻译模型不同的是,生成式模型的任务不是将一句话翻译成其他语言的一句话,而是将用户的输入[翻译]为一个回答(response)
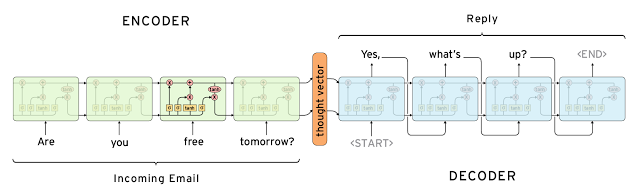
1.2 模型分类总结
以上两种模型均有优缺点。对于基于检索技术的模型,由于使用了知识库且数据为预先定义好的,因此进行回复的内容语法上较为通顺,较少出现语法错误;但是基于检索技术的模型中没有会话概念,不能结合上下文给出更加[智能]的回复。而生成式模型则更加[智能]一些,它能够更加有效地利用上下文信息从而知道你在讨论的东西是什么;然而生成式模型比较难以训练,并且输出的内容经常存在一些语法错误(尤其对于长句子而言),以及模型训练需要大规模的数据。
深度学习技术都能够用于基于检索技术的模型和生成式模型中,但是目前的研究热点在生成式模型上。深度学习框架例如Sequence to Sequence非常适合用来生成文本,非常多的研究者希望能够在这个领域取得成功。然而目前这一块的研究还在初期阶段,工业界的产品更多的还是使用基于检索计算的模型。
2. 问题分类
2.1 短对话 VS 长对话
直观上处理长对话内容将更加困难,这是因为你需要在当前对话的情境下知道之前的对话说过什么。如果是一问一答的形式,技术上这将简单的多。通常对于客服对话而言,长对话更加常见,一次对话中往往会伴随着多个关联问题。
2.2 开放域 VS 特定领域
面向开放域的聊天机器人技术面临更多困难,这是因为会话可能涉及的面太广,没有一个清晰的目标和意图。在一些社交网站例如Twitter和Reddit上的会话是属于开放域的,会话涉及的主题多种多样,需要的知识量也将非常巨大。
面向特定领域的相关技术则相对简单一些,这是因为特定领域给会话的主题进行了限制,目标和意图也更加清晰,典型的例子有客服系统助手和购物助手。这些系统通常是为了完成某些特定任务,尽管用户在该系统中也能够问些其他方面的东西,但是系统并不会给出相应的回复。
3. 面临的挑战
下面介绍一下聊天机器人技术所面临的挑战。
3.1 如何结合上下文信息
为了产生质量更高的回复,聊天机器人系统通常需要利用一些上下文信息(Context),这里的上下文信息包括了对话过程中的语言上下文信息和用户的身份信息等。在长对话中人们关注的是之前说了什么内容以及产生了什么内容的交换,这是语言上下文信息的典型。常见的方法是将一个会话转化为向量形式,但这对长会话而言是困难的。论文Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models和Attention with Intention for a Neural Network Conversation Model中的实验结果表明了这一点。另外,可以结合的上下文信息还包括会话进行时的日期地点信息、用户信息等。
3.2 语义一致性
理论上来说,机器人面对相同语义而不同形式的问题应该给予一致的回复,例如这两个问题[How old are you?]和[What’s your age?]。这理解起来是简单的,但却是学术界目前的难题之一(如下图)。许多系统都试图对相同语义而不同形式的问题给予语义上合理的回复,但却没有考虑一致性,最大的原因在于训练模型的数据来源于大量不同的用户,这导致机器人失去了固定统一的人格。论文A Persona-Based Neural Conversation Model中提及的模型旨在创建具有固定统一人格的机器人。

3.3 对话模型的评测
评价一个对话模型的好坏在于它是否很好地完成了某项任务,例如在对话中解决了客户的问题。这样的训练数据需要人工标注和评测,所以获取上需要一定人力代价。有时在开放域中的对话系统也没有一个清晰的优化目标。用于机器翻译的评测指标BLEU不能适用于此,是因为它的计算基础是语言表面上的匹配程度,而对话中的回答可以是完全不同词型但语义通顺的语句。论文How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation中给出结论,目前常用的评测指标均与人工评测无关。
3.4 意图和回复多样性
生成式模型中的一个普遍问题是,它们都想要生成一些通用的回答,例如[That’s great!]和[I don’t know]这样的可以应付许多的用户询问。早期的Google智能回复基本上以[I love you]回复所有的东西链接,这是一些模型最终训练出来的结果,原因在于训练数据和训练的优化目标。因此,有些研究学者开始关注如何提升机器人的回复的多样性,然而人们在对话过程中的回复与询问有一定特定关系,是有一定意图的,而许多面向开放域的机器人不具备特定的意图。
3.5 实际效果
以目前的研究水平所制造的机器人能够取得的效果如何?使用基于检索技术的显然无法制作出面向开放域的机器人,这是因为你不能编写覆盖所有领域的语料;而生成式的面向开放域的机器人还属于通用人工智能(Artifical General Intelligence, AGI)水平,距离理想状态还相距甚远,但相关研究学者还在致力于此。
对于特定领域的机器人,基于检索的技术和生成式模型都能够利用。但是对于长对话的情境,也面临许多困难。
在最近对Andrew NG的采访中,NG提到:
目前深度学习的价值主要体现在能够获取大量数据的特定领域。
目前一个无法做的事情是产生一个有意义的对话。
详细: 当今深度学习的价值在你可以获得许多数据的狭窄领域内。有一件事它做不到:进行有意义的对话。存在一些演示,并且如果你仔细挑选这些对话,看起来就像它正在进行有意义的对话,但是如果你亲自尝试,它就会快速偏离轨道。
许多创业公司声称只要有足够多的数据,就能够产生自动智能的对话系统。然而,目前的水平生产出面向一个特定的子领域的对话应用(如利用Uber打车),而对于一个稍微开放点的领域就难以实现了(如自动销售)。但是,帮助用户提供自动回复建议以及语法纠正还是可行的。
使用基于检索技术的对话系统更加可控和稳定,给出的回复出现语法错误的几率更低。而使用生成式模型的风险在于回复不可控,且容易出现一些风险,例如微软的Tay。
4. 即将到来的事情和阅读列表
在之后的博文中将具体介绍深度学习方面的技术细节。提前阅读下面的文章将会对后面的学习更加有帮助。
-
Neural Responding Machine for Short-Text Conversation (2015-03)
-
A Neural Network Approach to Context-Sensitive Generation of Conversational Responses (2015-06)
-
Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models (2015-07)
-
A Diversity-Promoting Objective Function for Neural Conversation Models (2015-10)
-
Attention with Intention for a Neural Network Conversation Model (2015-10)
-
Improved Deep Learning Baselines for Ubuntu Corpus Dialogs (2015-10)
-
A Survey of Available Corpora for Building Data-Driven Dialogue Systems (2015-12)
-
Incorporating Copying Mechanism in Sequence-to-Sequence Learning (2016-03)
数据驱动的意义是:
- 算法越简单,解释性越好
- 数据量足够大,覆盖的真实世界的大部分场景
Checking if Disqus is accessible...