Sequence Models (week1) - Recurrent Neural Networks
这次我们要学习专项课程中第五门课 Sequence Models.
第一周: Recurrent Neural Networks 已被证明在时间数据上表现好,它有几个变体,包括 LSTM、GRU 和双向神经网络.
1. Why sequence models?
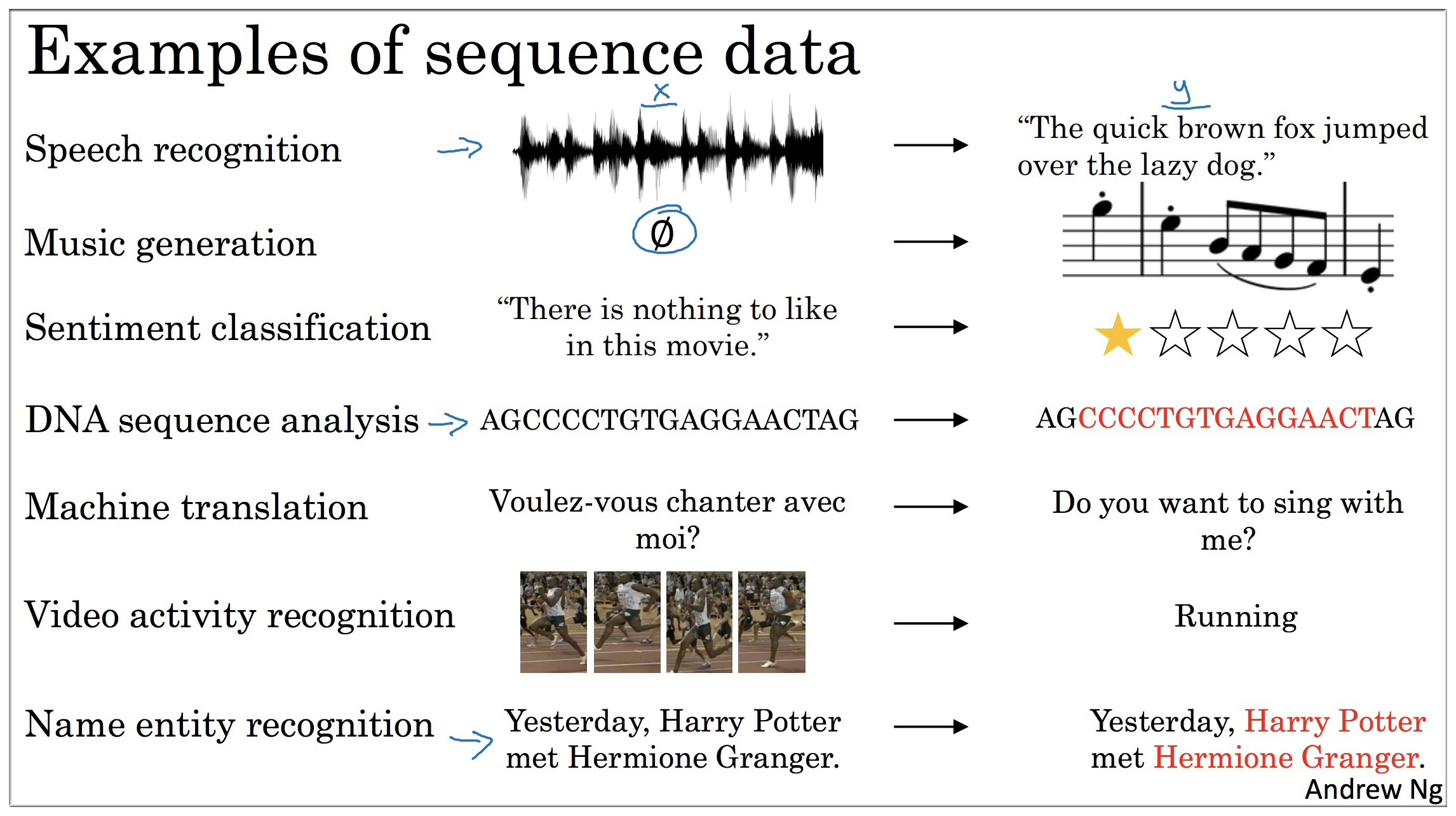
为什么要学习序列模型呢? 序列模型, 普遍称为 RNN (递归神经网络 - Recurrent Neural Network), 做为深度学习中非常重要的一环,有着比普通神经网络更广的宽度与更多的可能性,其应用领域包括但不限于“语音识别”, “NLP”, “DNA序列分析”,“Machine Translation”, “视频动作分析”,等等… 有这样一种说法,也许并不严谨,但有助于我们理解RNN,大意是这样的:
普通神经网络处理的是一维的数据,CNN 处理的是二维的数据,RNN 处理的是三维的数据
最直观的理解是在 CNN 对图片的分析基础上,RNN 可以对视频进行分析,这里也就引入了第三维“时间”的概念
这一小节通过一个小例子为我们打开序列模型的大门,例子如下:
给出这样一个句子 “Harry Potter and Herminone Granger invented a new spell."(哈利波特与赫敏格兰杰发明了 一个新的咒语。), 我们的任务是在这个句子中准确的定位到人名 Harry Potter 和 Herminone Granger. 用深度学习的语言来描述如下图 - 每一个单词对应一个输出 0 或者 1,1 代表着是人名,0 代表不是。

接下来我们要解决的一个问题是
如何才能代表一个单词?,比如我们例子中的 “Harry”,这里我们介绍一种新的编码方式, 就是用另一种方式来代表每一个单词 - 独热编码(One-Hot Encoding)。 具体流程是这样,假设我们有 10000 个常用词,为其构建一个10000*1 的矩阵(column matrix),假如第一个词是苹果(apple), 那么对应的第一个位置为 1,其他都为 0,所以称之为独热。这样每个单词都有对应的矩阵进行表示,如果这个词没有出现在我们的字典中,那么我们可以给一个特殊的符号代替,常用的是(unknown)
2. Notation
为了后面方便说明,先将会用到的数学符号进行介绍. 以下图为例,假如我们需要定位一句话中人名出现的位置.
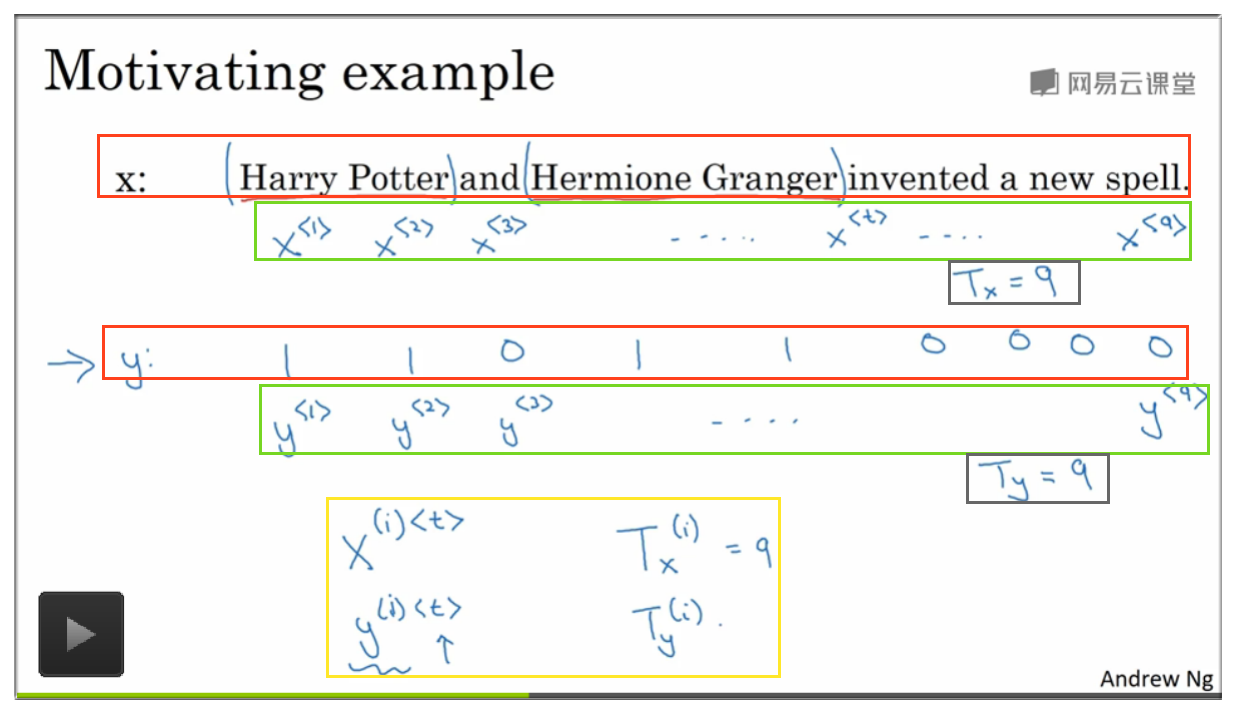
红色框中的为输入、输出值。可以看到人名输出用 1 表示,反之用 0 表示;
绿色框中的 , 表示对应红色框中的输入输出值的数学表示,注意从 1 开始.
灰色框中的 分别表示输入输出序列的长度,在该例中,
黄色框中 上的表示第 个输入样本的第 个输入值, 则表示第 个输入样本的长度。输出 也同理.
输入值中每个单词使用 One-Hot 来表示。即首先会构建一个字典(Dictionary), 假设该例中的字典维度是 10000*1 (如图示)。第一个单词 “Harry” 的数学表示形式即为 [0,0,0,……,1 (在第4075位) ,0,……,0],其他单词同理。
但是如果某一个单词并没有被包含在字典中怎么办呢?此时我们可以添加一个新的标记,也就是一个叫做 Unknown Word 的伪造单词,用 <UNK> 表示。具体的细节会在后面介绍。

3. Recurrent Neural Network Model
在介绍 RNN 之前,首先解释一下为什么之前的标准网络不再适用了。因为它有两个缺点:
- 输入和输出的长度不尽相同
- 无法共享从其他位置学来的特征
例如上一节中的 Harry 这个词是用 表示的,网络从该位置学习了它是一个人名。但我们希望无论 Harry 在哪个位置出现网络都能识别出这是一个人名的一部分,而标准网络无法做到这一点.
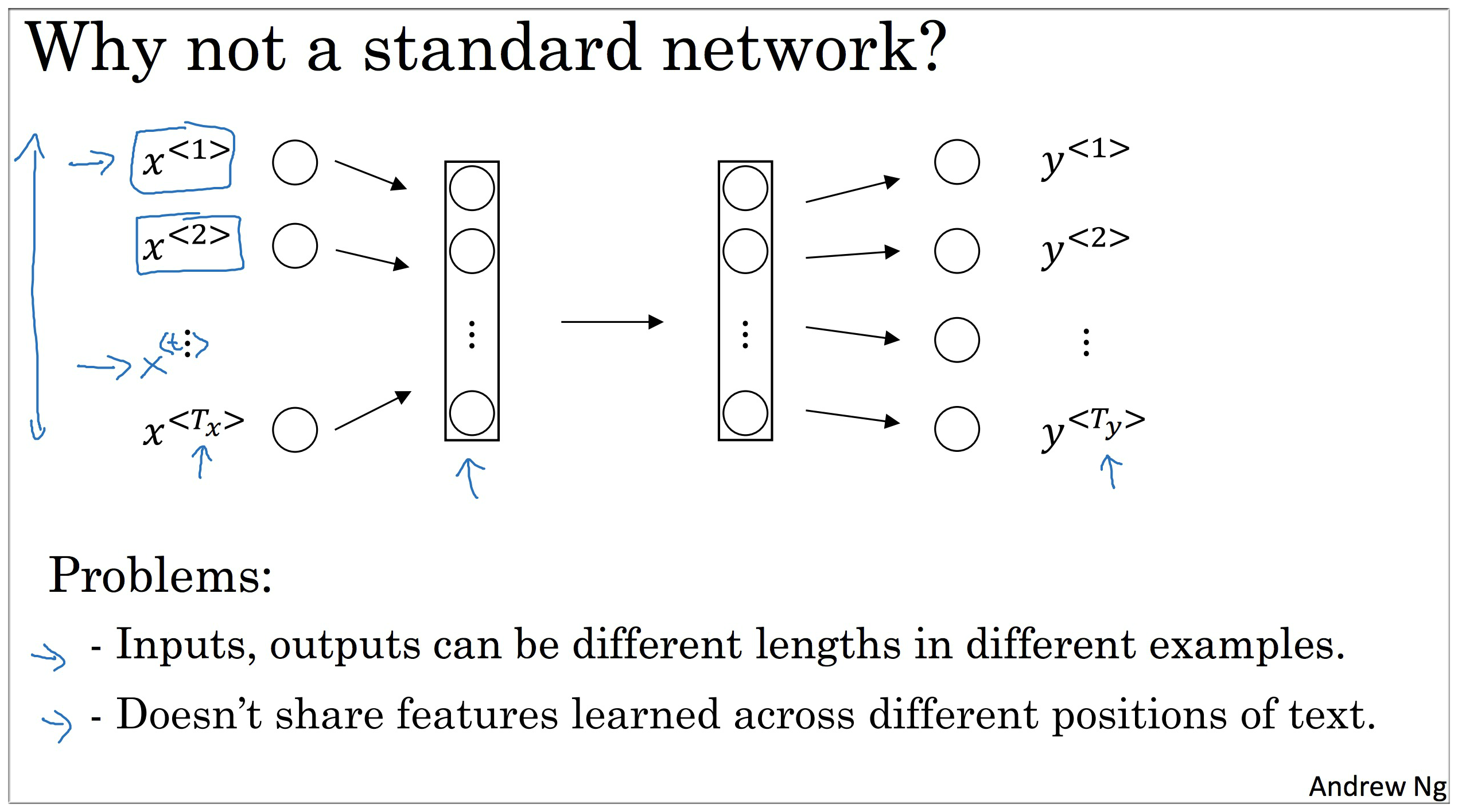
输入层,比如每个 都是一个 1000 维的向量,这样输入层很庞大, 那么第一层的权重矩阵就有着巨大的参数.
3.1 RNN 结构
还是以识别人名为例,第一个单词 输入神经网络得到输出
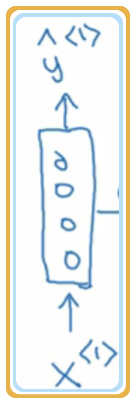
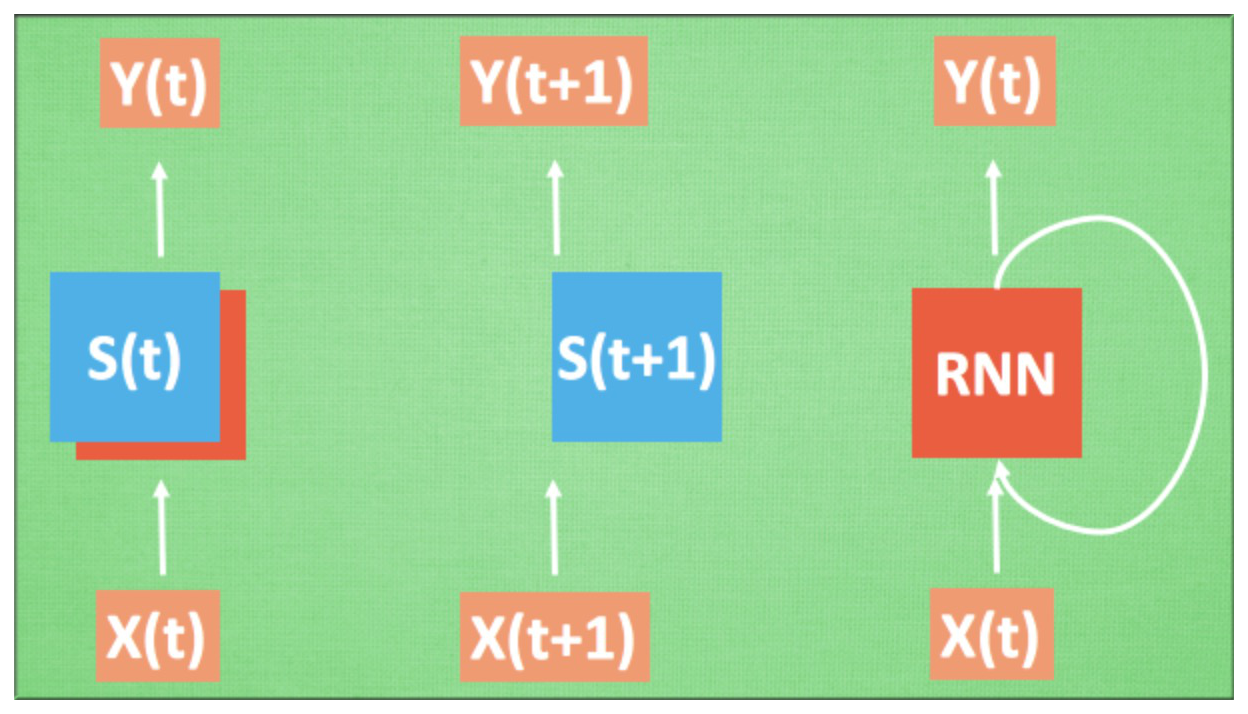
同理, 由 将得到 ,以此类推。但是这就是传统网络存在的问题,即单词之间没有联系
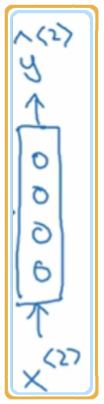
为了将单词之间关联起来,所以将前一层的结果也作为下一层的输入数据。如下图示
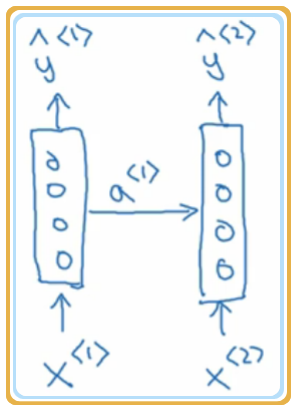
整体的 RNN 结构有两种表示形式,如下图示, 左边是完整的表达形式,注意第一层的 一般设置为 0向量.
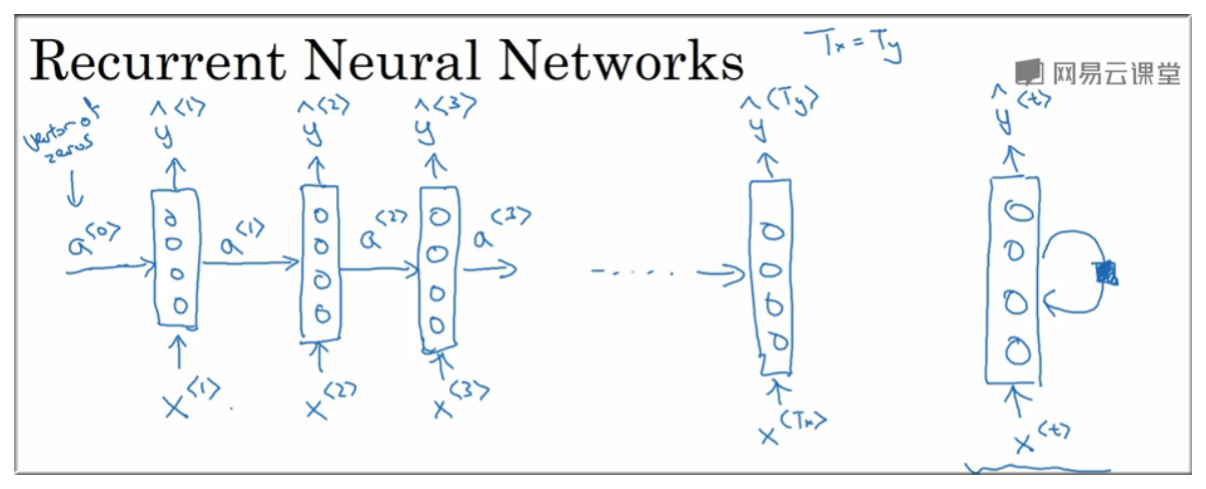
要开始整个流程, 需要编造一个激活值, 这通常是 0向量, 有些研究人员会用其他方法随机初始化 . 不过使用 0向量,作为 0时刻 的伪激活值 是最常见的选择. 因此我们把它输入神经网络.
(右边的示意图是 RNN 的简写示意图)
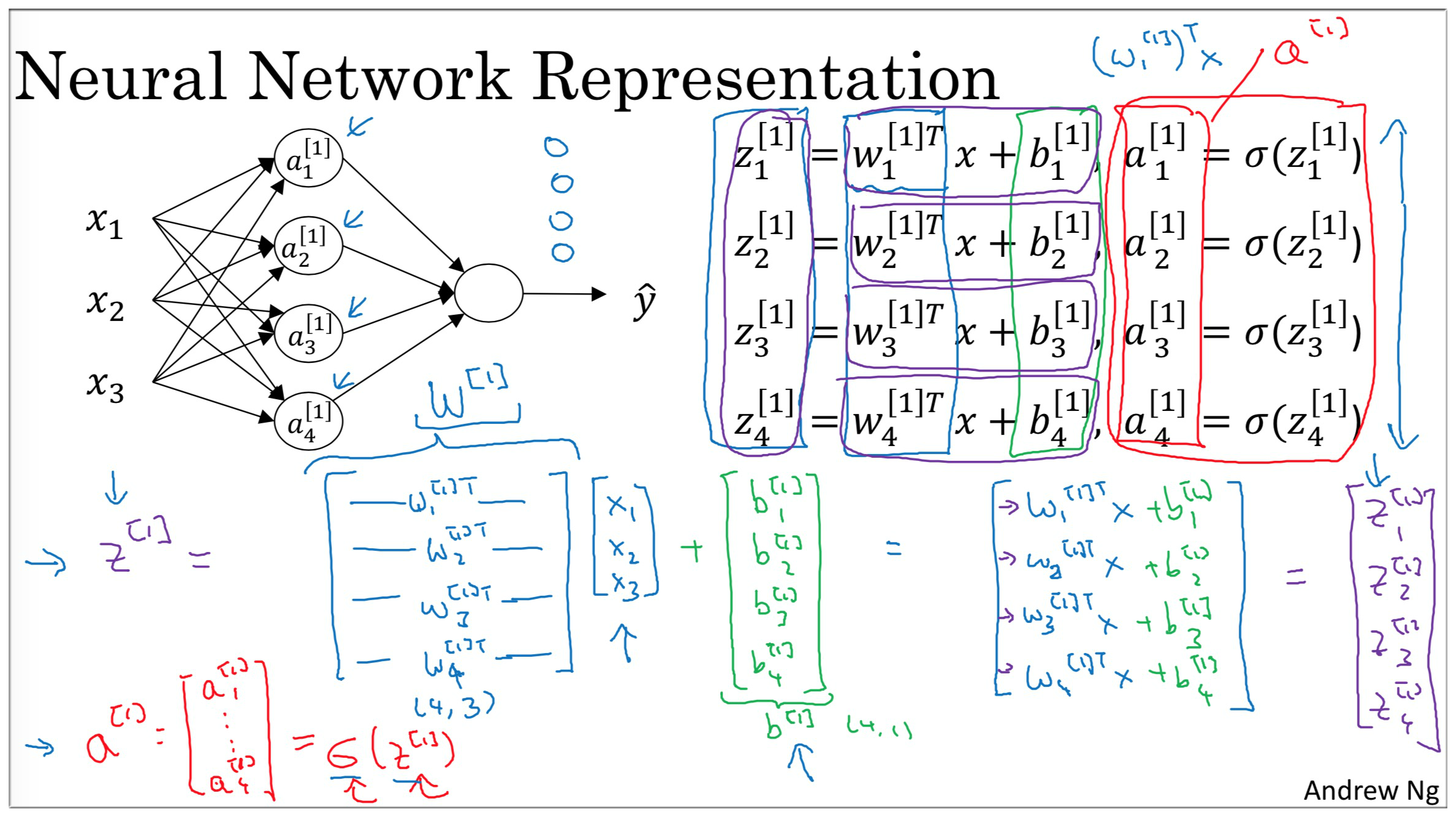
介绍完结构之后,我们还需要知道网络中参数的表达方式及其含义。如下图示, 到网络的参数用 表示, 到网络的参数用 表示, 到网络的参数用 表示,具体含义将在下面进行说明.
通过网络可以传递到
但是这存在一个问题,即每个输出只与前面的输入有关,而与后面的无关。这个问题会在后续内容中进行改进.
举个🌰: He said, “Teddy Roosevelt was a great President.”
对于这句话,只知道 He said 前面两个词,来判断 Teddy 是否是人名是不够的,还需后面的信息.(BRNN 可处理这问题)
3.2 RNN Forward Propagation
看 RNN Forward Propagation 之前,先看下基本的标准网络
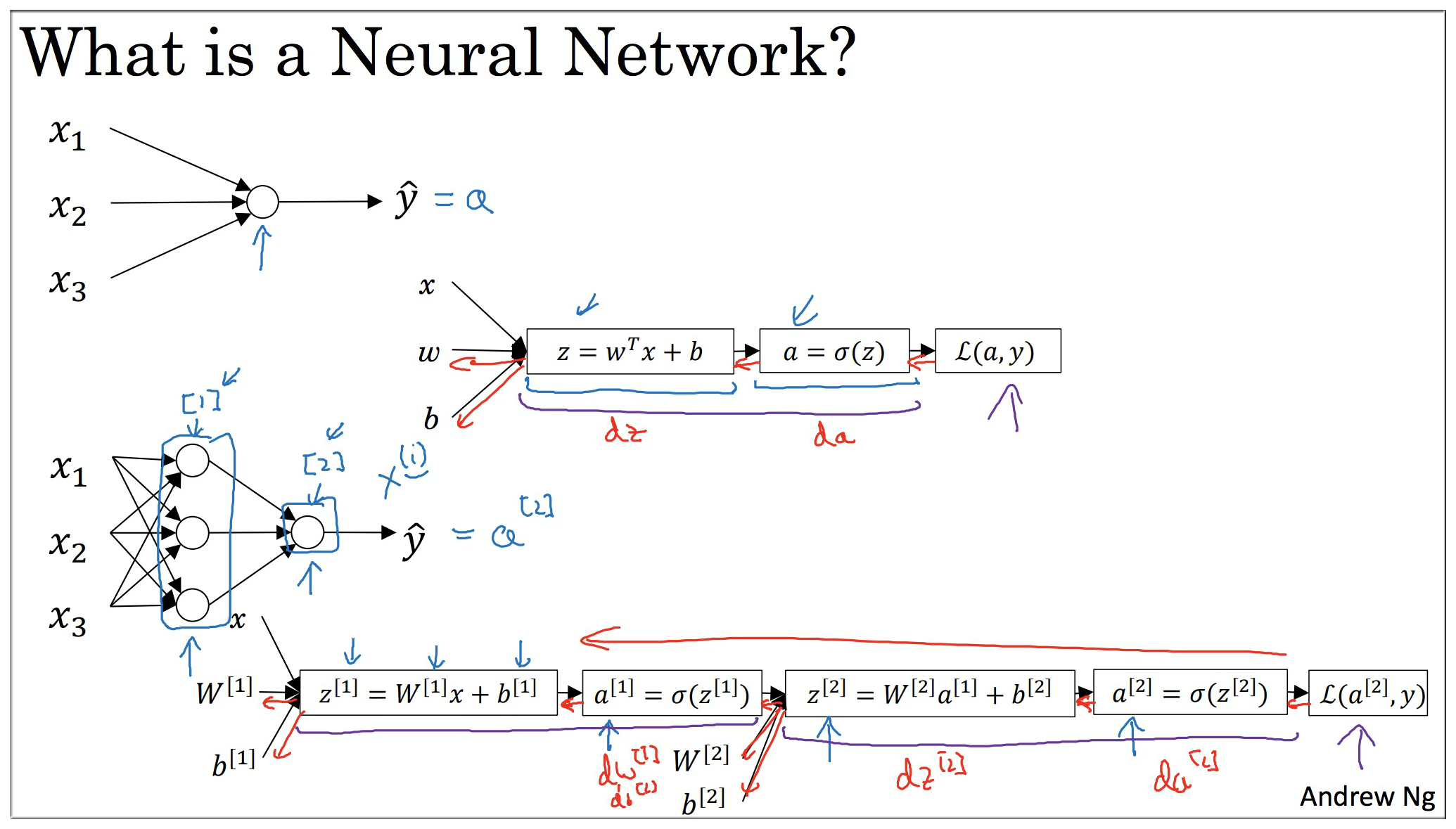
RNN 在正向传播的过程中可以看到 a 的值随着时间的推移被传播了出去,也就一定程度上保存了单词之间的特性:
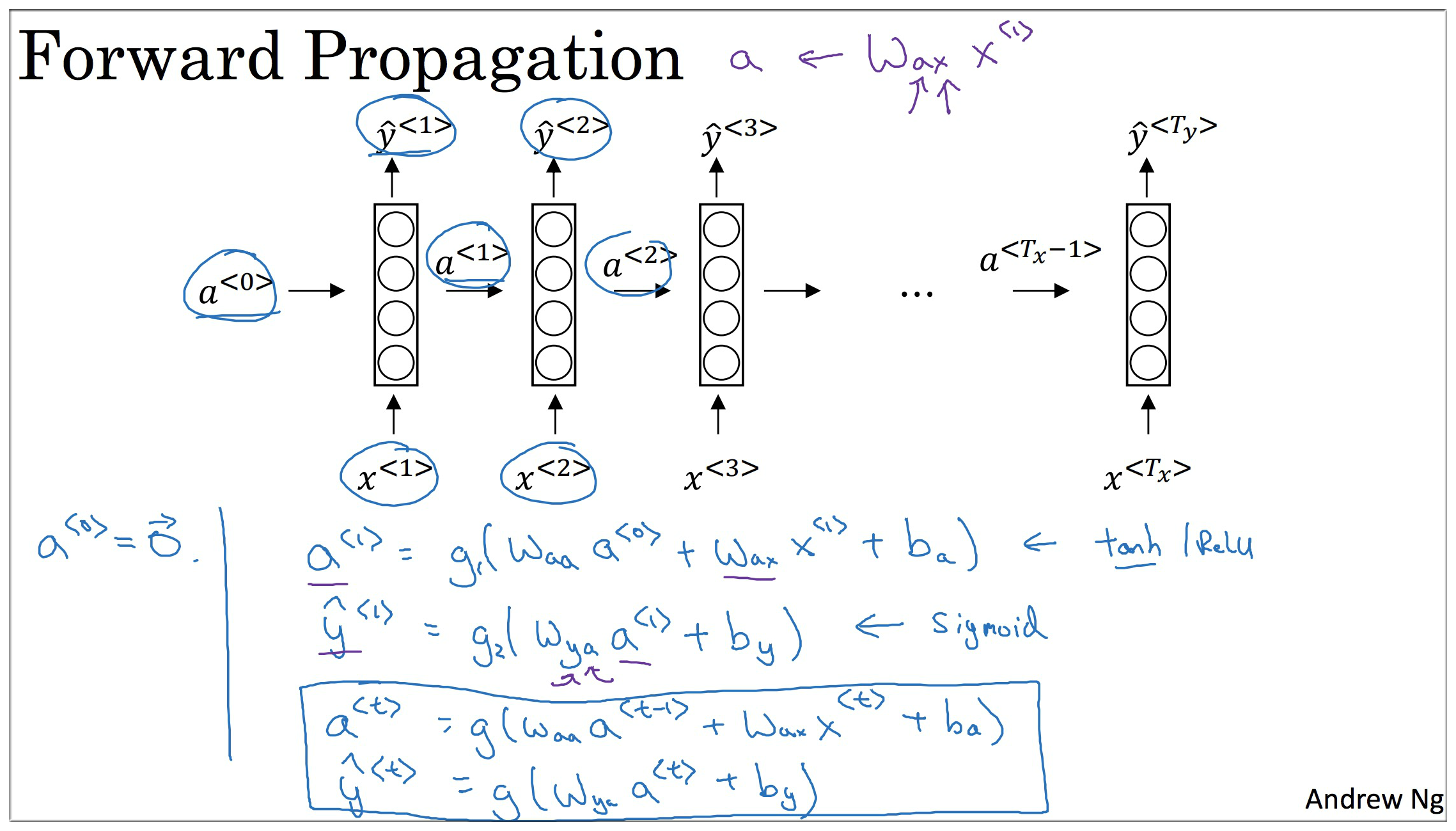
激活函数: 一般为
tanh函数 (或者是Relu函数), 一般是Sigmod函数.注意: 参数的下标是有顺序含义的,如 下标的第一个参数表示要计算的量的类型,即要计算 矢量,第二个参数表示要进行乘法运算的数据类型,即需要与 矢量做运算。如
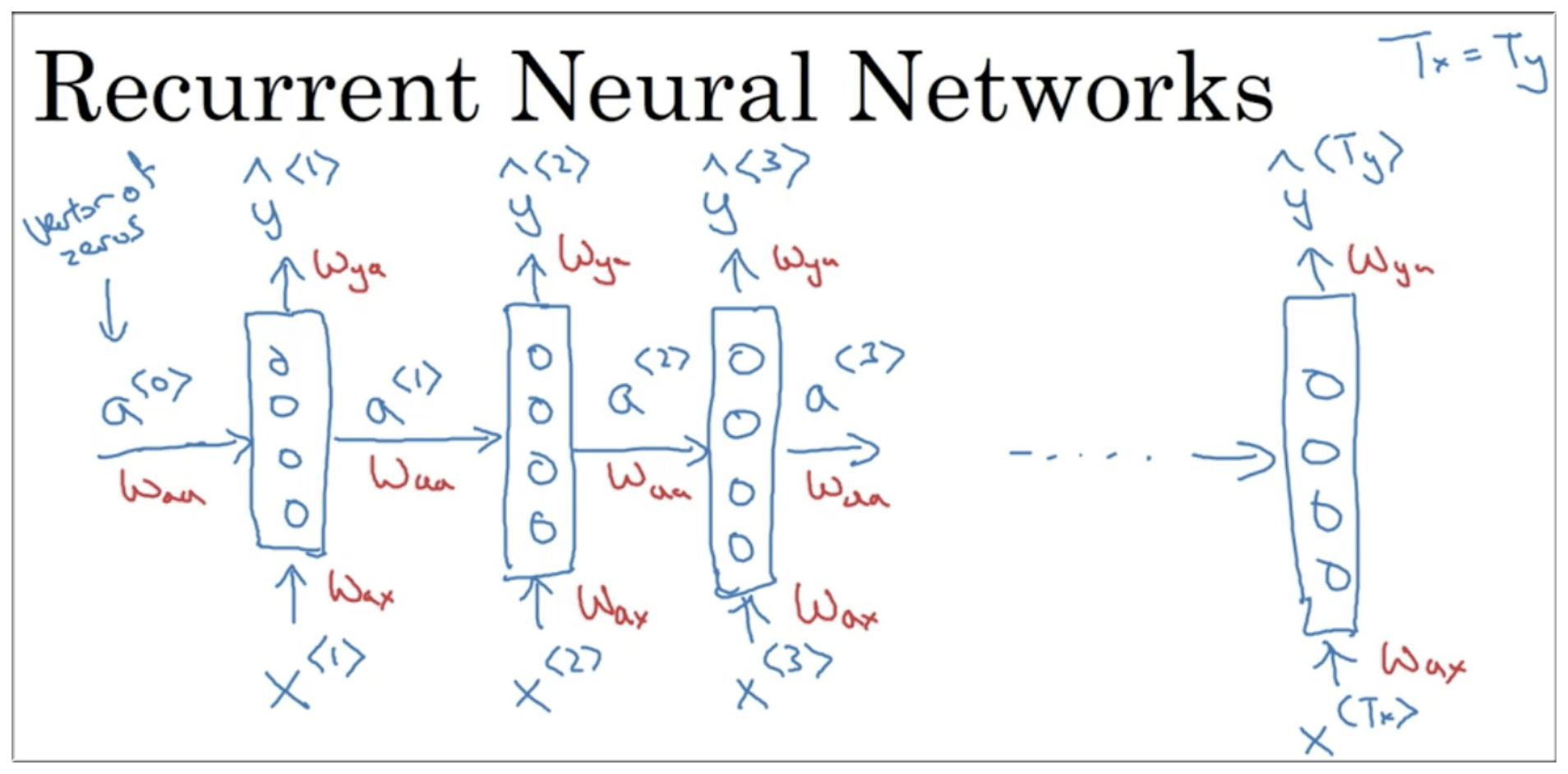
Tx , Ty 是时间单位, 这里统称为“时刻”,在这例子中对应不同时刻是输入的第几个单词, x 是“输入值”,例子中是当前时刻的单词(以独热编码的形式), y 是“输出值” 0 或者 1, a 称为激活值用于将前一个单元的输出结果传递到下一个单元, Wax Way Waa 是不同的“权重矩阵”也就是我们神经网络 update 的值。每一个单元有两个输入, 和 x ,有两个输出 和 y . 图中没有出现的 g 是“激活函数”。
| 符号 | 名字 |
|---|---|
| 输入值 | |
| 激活值 | |
| , | , 时刻 |
| Wax, Way, Waa | 权重矩阵 |
3.3 Simplified RNN notation
下面将对如下公式进行化简:
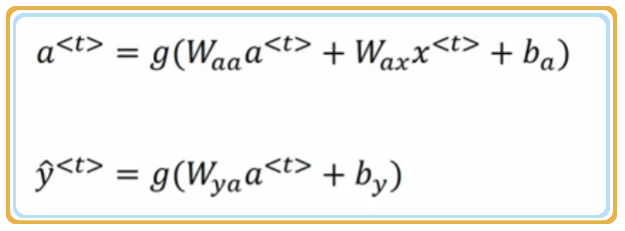
1. 简化
\begin{align} a^{<{t}>}&= g(W\_{aa}a^{<{t-1}>}+W\_{ax}x^{<{t}>}+b\_a) \notag \\\\ &= g(W\_a [a^{<{t-1}>},x^{<{t}>}]^{T}+b\_a) \notag \end{align}

注意,公式中使用了两个矩阵进行化简,分别是 和 (使用转置符号更易理解),下面分别进行说明:
, 假设 是 (100,100) 的矩阵, 是 (100,10000) 的矩阵,那么 则是 (100,10100) 的矩阵.
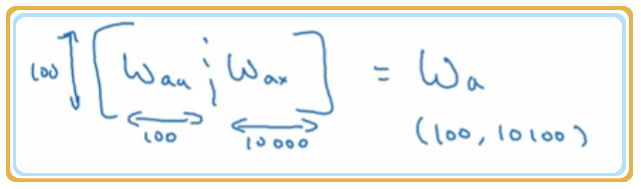
是下图示意:
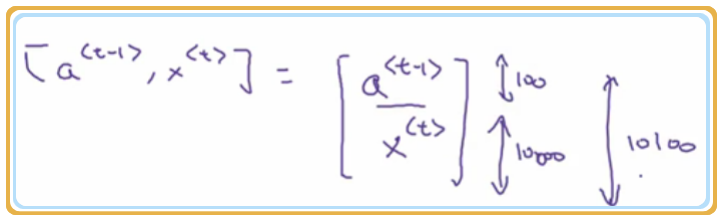
故 矩阵计算如下图示:
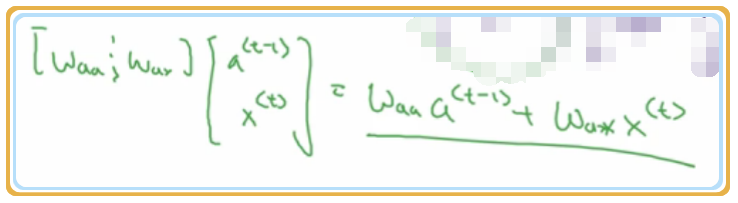
2. 简化
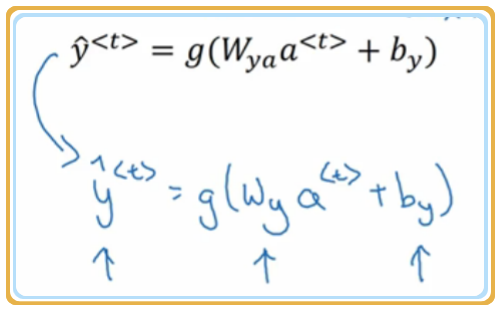
该节PPT内容:
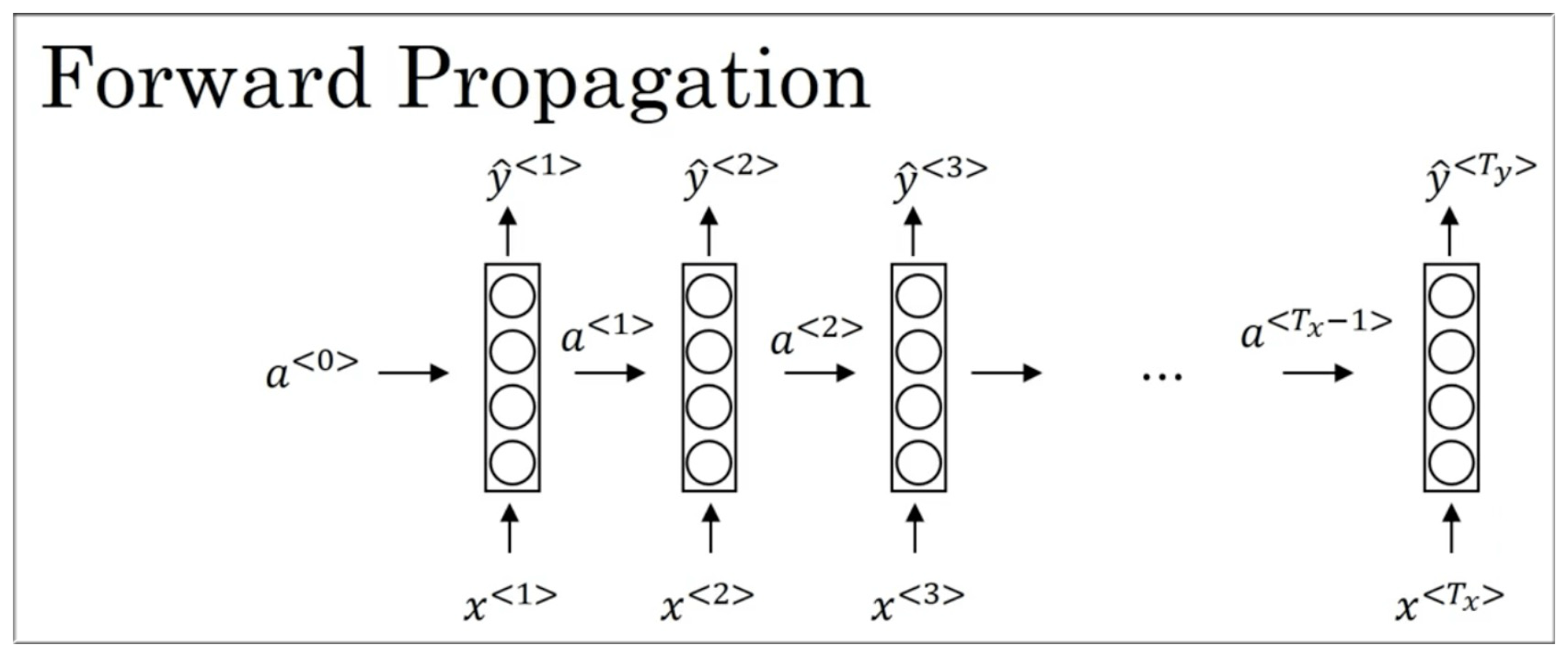
再回顾下干净的前向传播概览图:
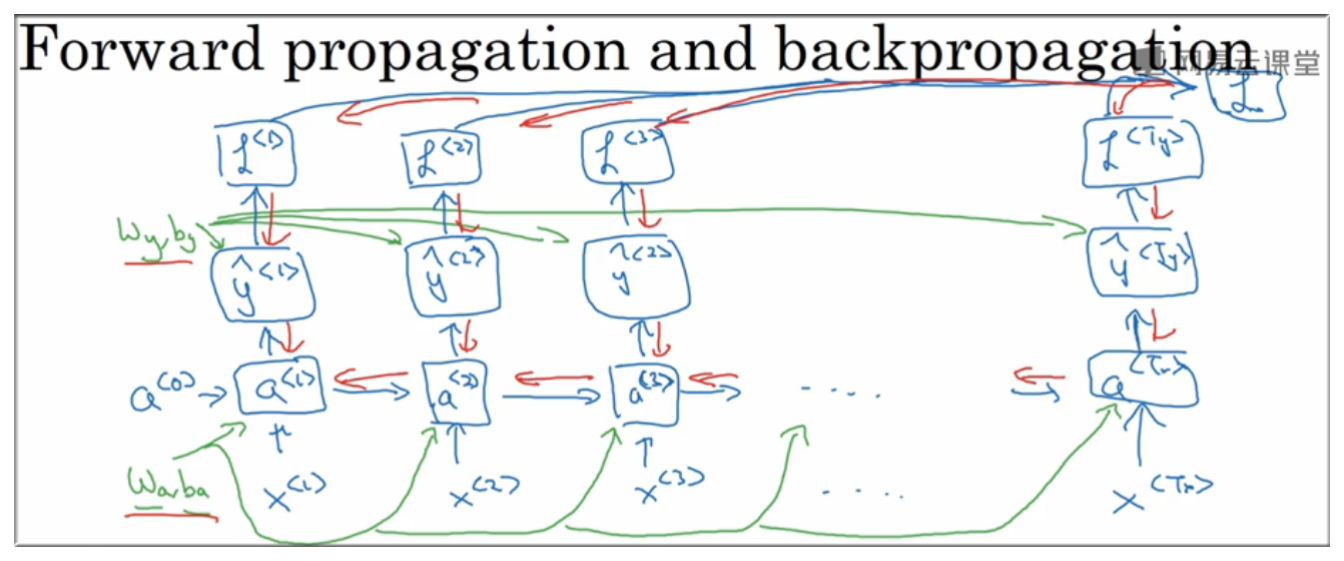
4. Backpropagation through time
RNN 的反向传播通常都由类似 Tensorflow、Torch 之类的库或者框架帮你完成,不过感官上和普通神经网络类似,算梯度值然后更新权重矩阵.
但是下面这里依然会对反向传播进行详细的介绍,跟着下面一张一张的图片走起来 😄😄:
4.1 整体感受
首先再回顾一下 RNN 的整体结构:
要进行反向传播,首先需要前向传播,传播方向如蓝色箭头所示,其次再按照红色箭头进行反向传播
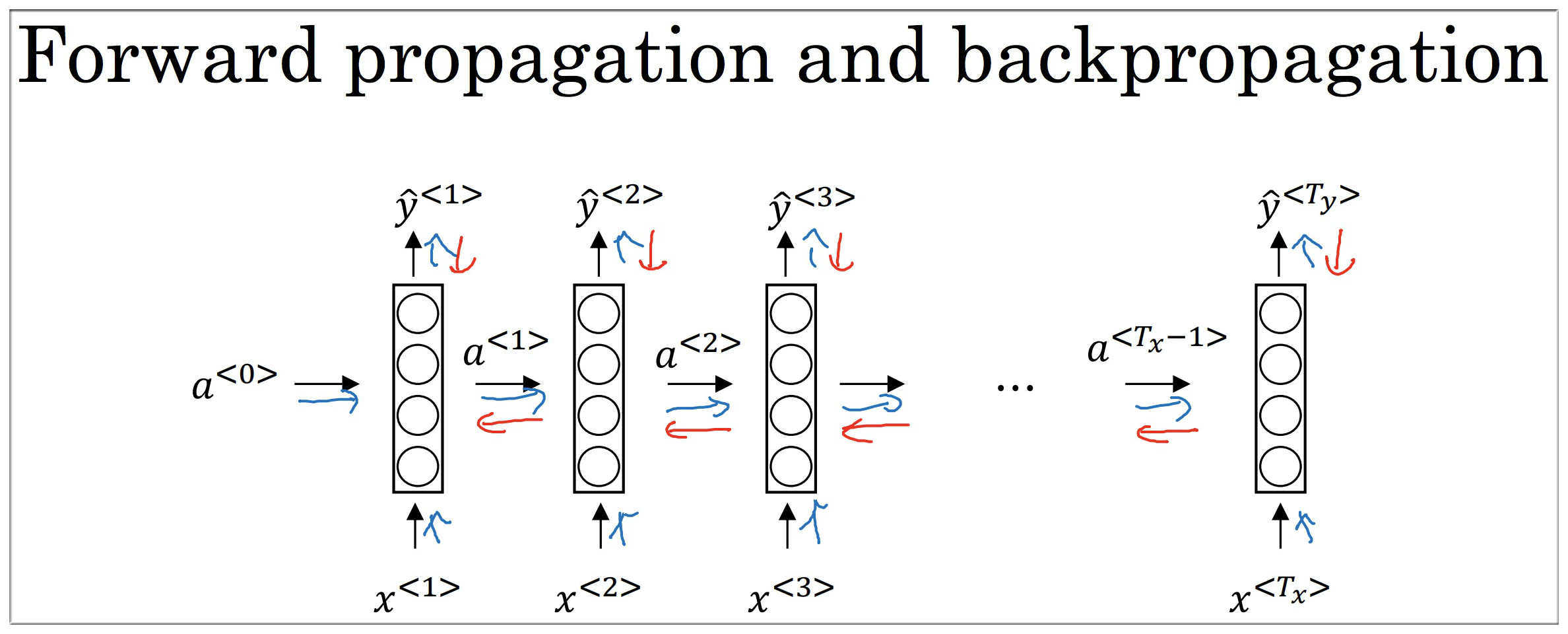
4.2 前向传播
首先给出所有输入数据,即从 到 , 表示输入数据的数量.

初始化参数 , ,将输入数据输入网络得到对应的
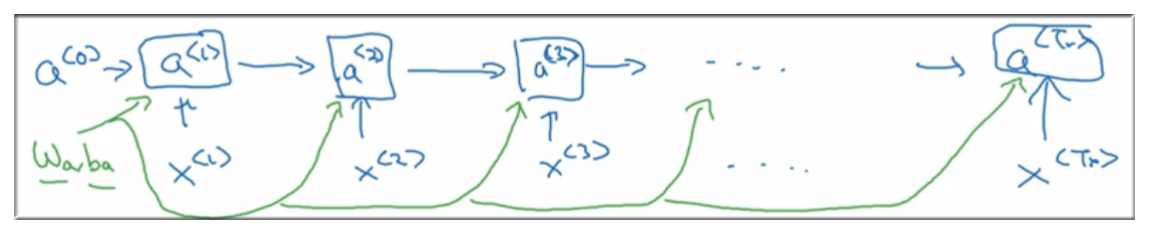
再通过与初始化参数 , 得到
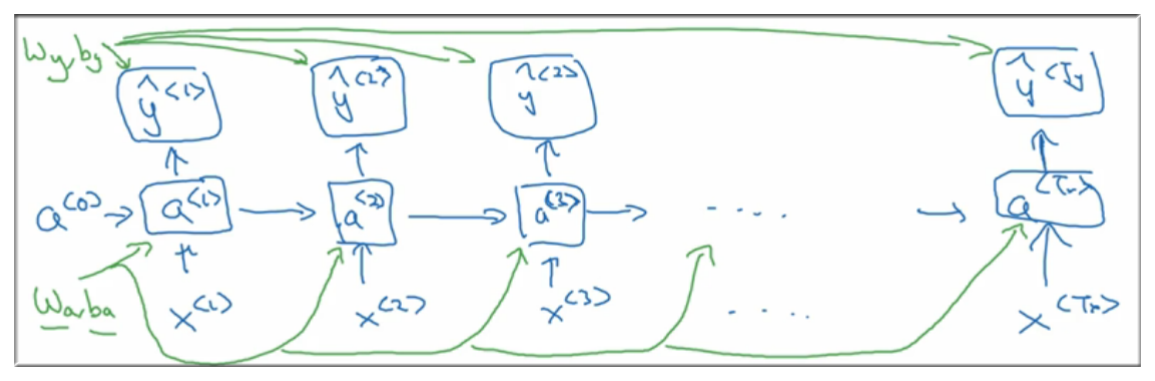
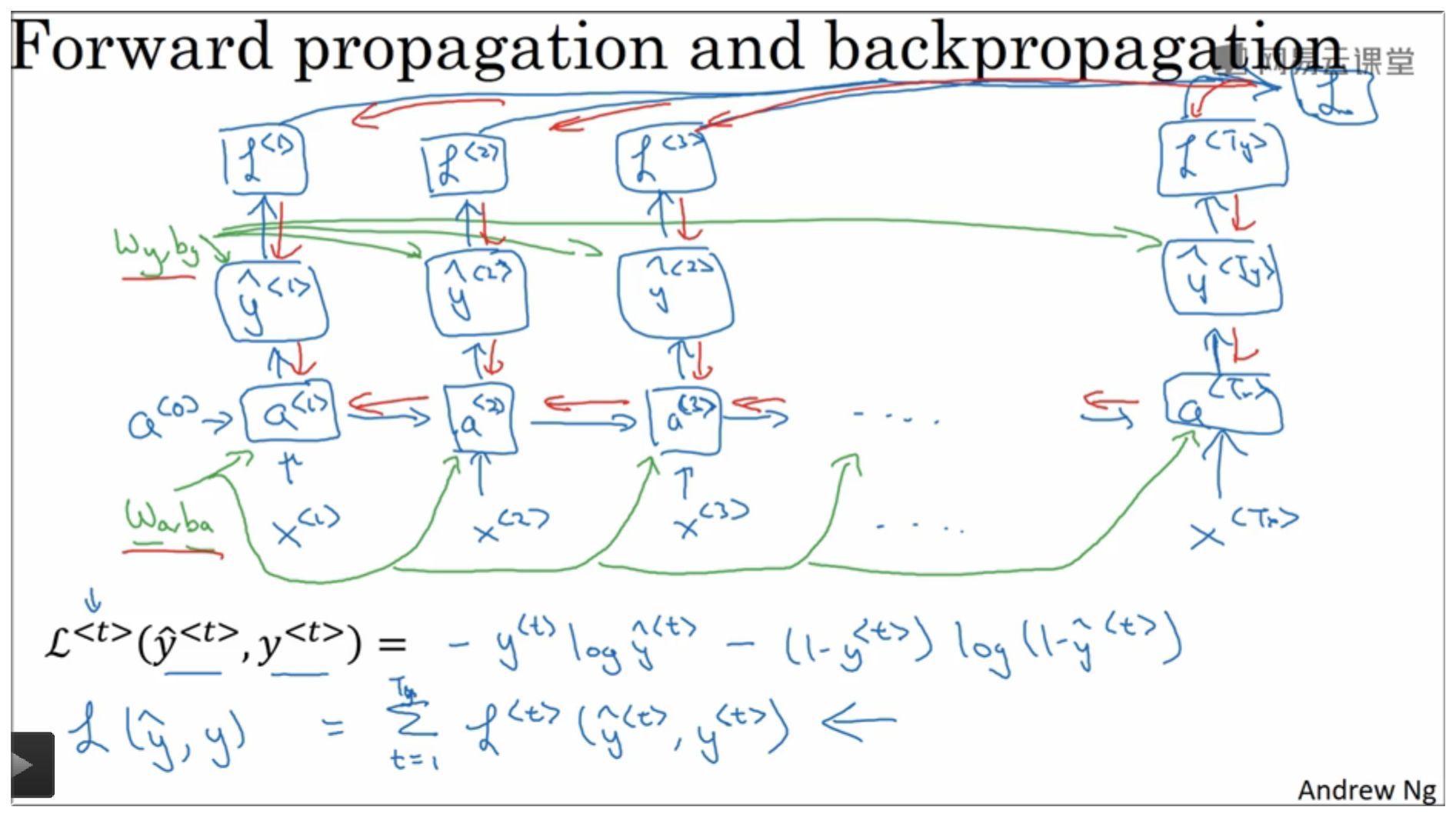
4.3 损失函数定义
要进行反向传播,必须得有损失函数嘛,所以我们将损失函数定义如下:
每个节点的损失函数:
整个网络的损失函数:
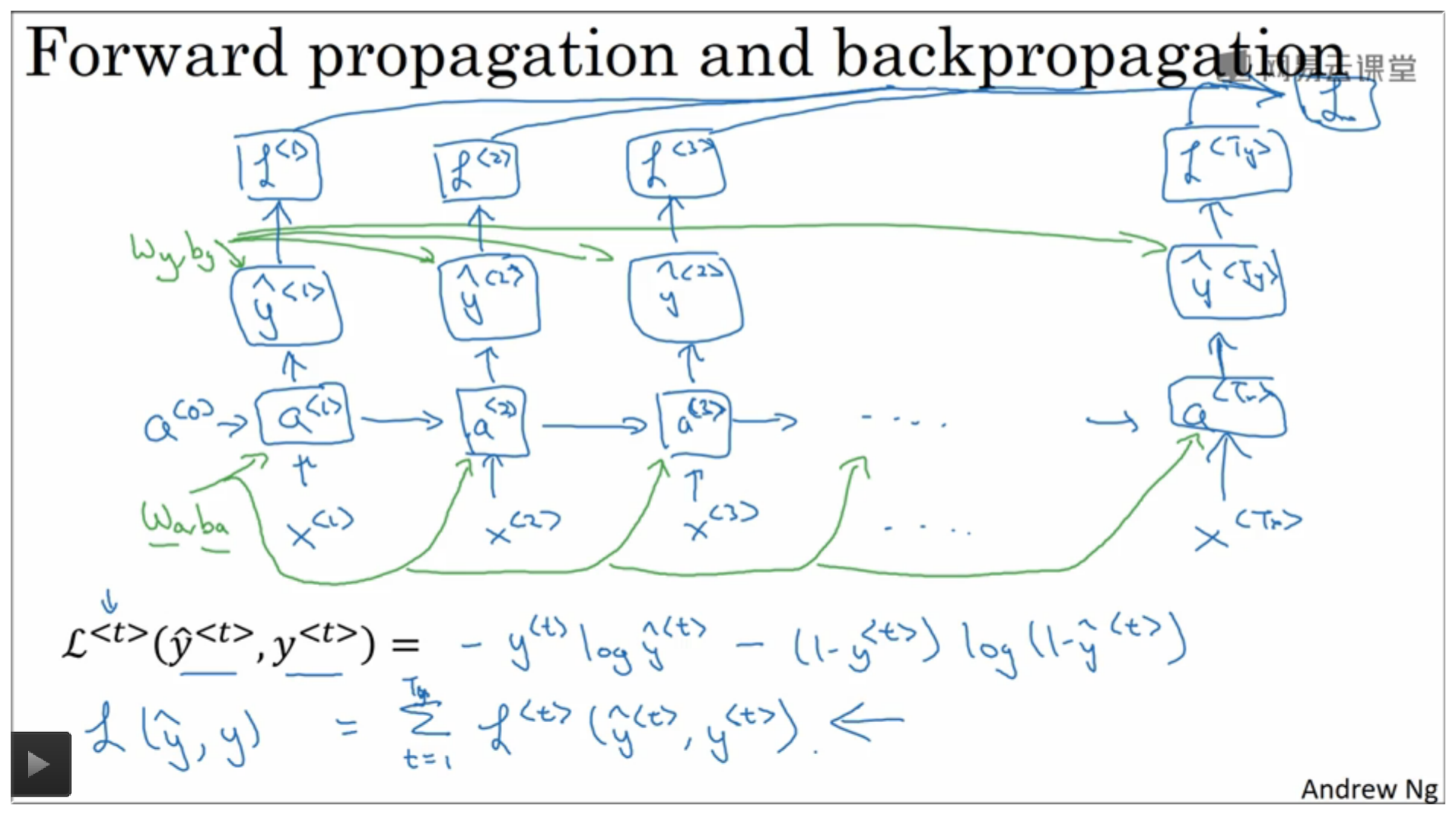
4.4 反向传播
4.5 整个流程图
5. Different types of RNNs
RNN 的不同应用领域:
序列模型对输入与输出的长度没有要求,在常见的例子中,机器翻译就是多个输入与多个输出,简称“多对多”, 语音识别可视为“单对多”, 它的反例是音乐生成-“多对单”。课程中介绍了多种可能的 RNN 模式,我们用下面一张图概括:
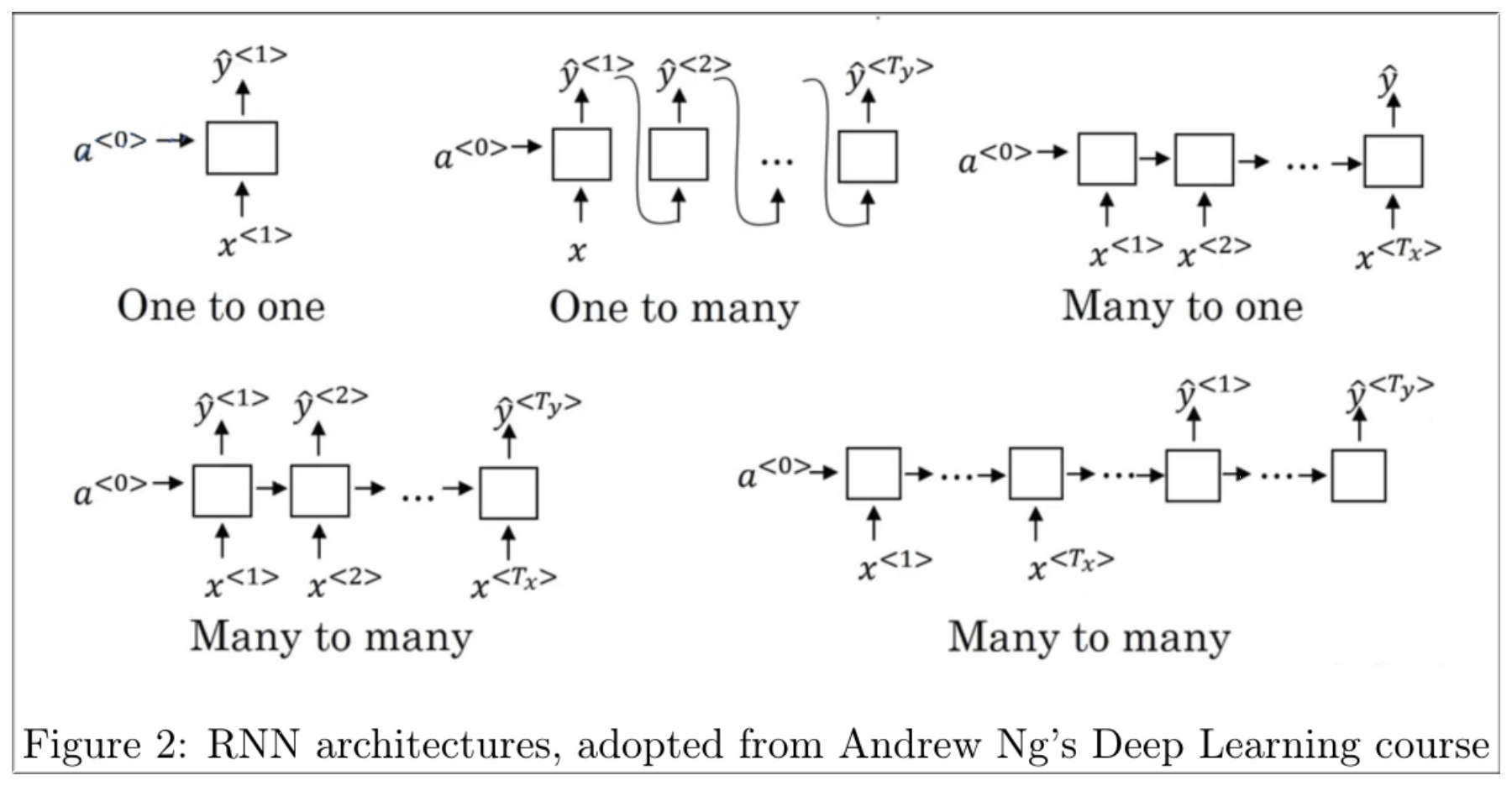
RNN 不同的结构给了我们更多的可能性.
6. Language model and sequence generation
语言模型和序列生成
6.1 什么是语言模型
凡事开头举个🌰,一切都好说:
假设一个语音识别系统听一句话得到了如下两种选择,作为正常人肯定会选择第二种。但是机器才如何做判断呢?

此时就需要通过语言模型来预测每句话的概率:

6.2 如何使用 RNN 构建语言模型
- 首先我们需要一个很大的语料库 (Corpus)
- 将每个单词字符化 (Tokenize,即使用One-shot编码) 得到词典,,假设有 10000 个单词
- 还需要添加两个特殊的单词
- end of sentence. 终止符,表示句子结束.
- UNknown, 之前的笔记已介绍过
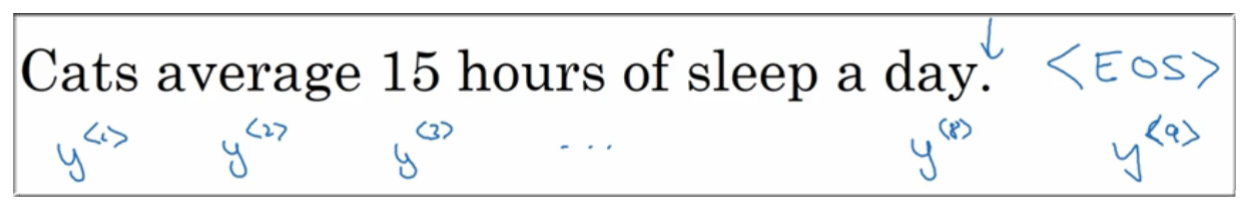
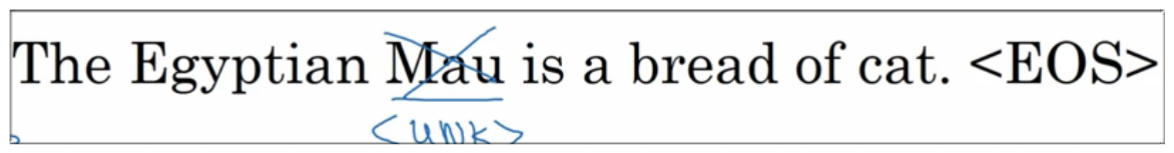
6.3 构建语言模型示例
假设要对这句话进行建模:Cats average 15 hours of sleep a day.
1. 初始化
这一步比较特殊,即 和 都需要初始化为 .
此时 将会对第一个字可能出现的每一个可能进行概率的判断,即 .当然在最开始的时候没有任何的依据,可能得到的是完全不相干的字,因为只是根据初始的值和激活函数做出的取样。
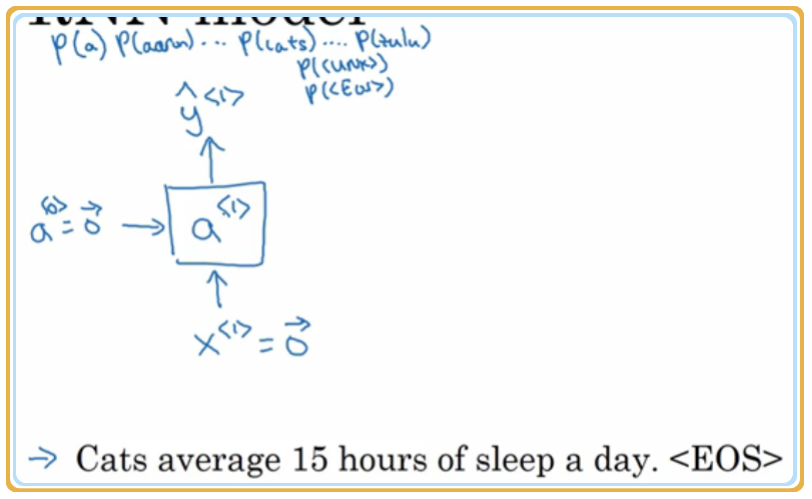
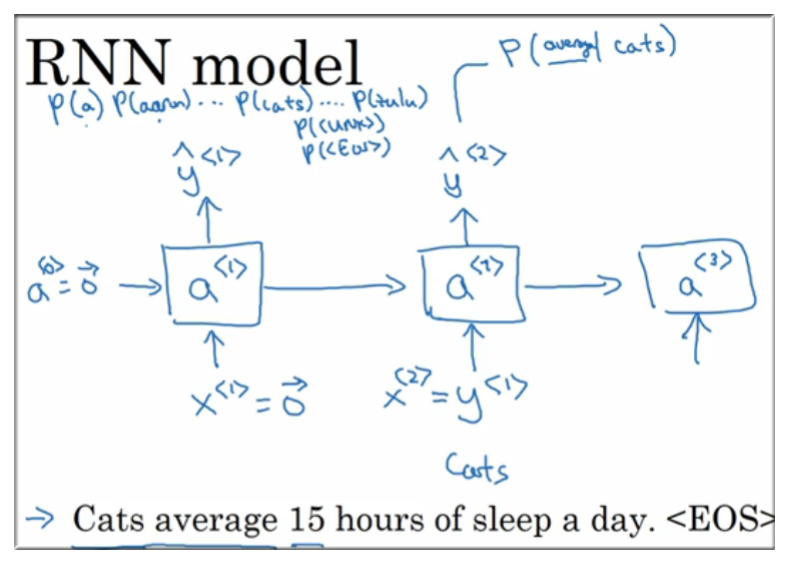
2. 将真实值作为输入值:
之所以将真实值作为输入值很好理解,如果我们一直传错误的值,将永远也无法得到字与字之间的关系
如下图示,将 所表示的真实值 Cats 作为输入,即 得到
此时的
同理有
另外输入值满足:
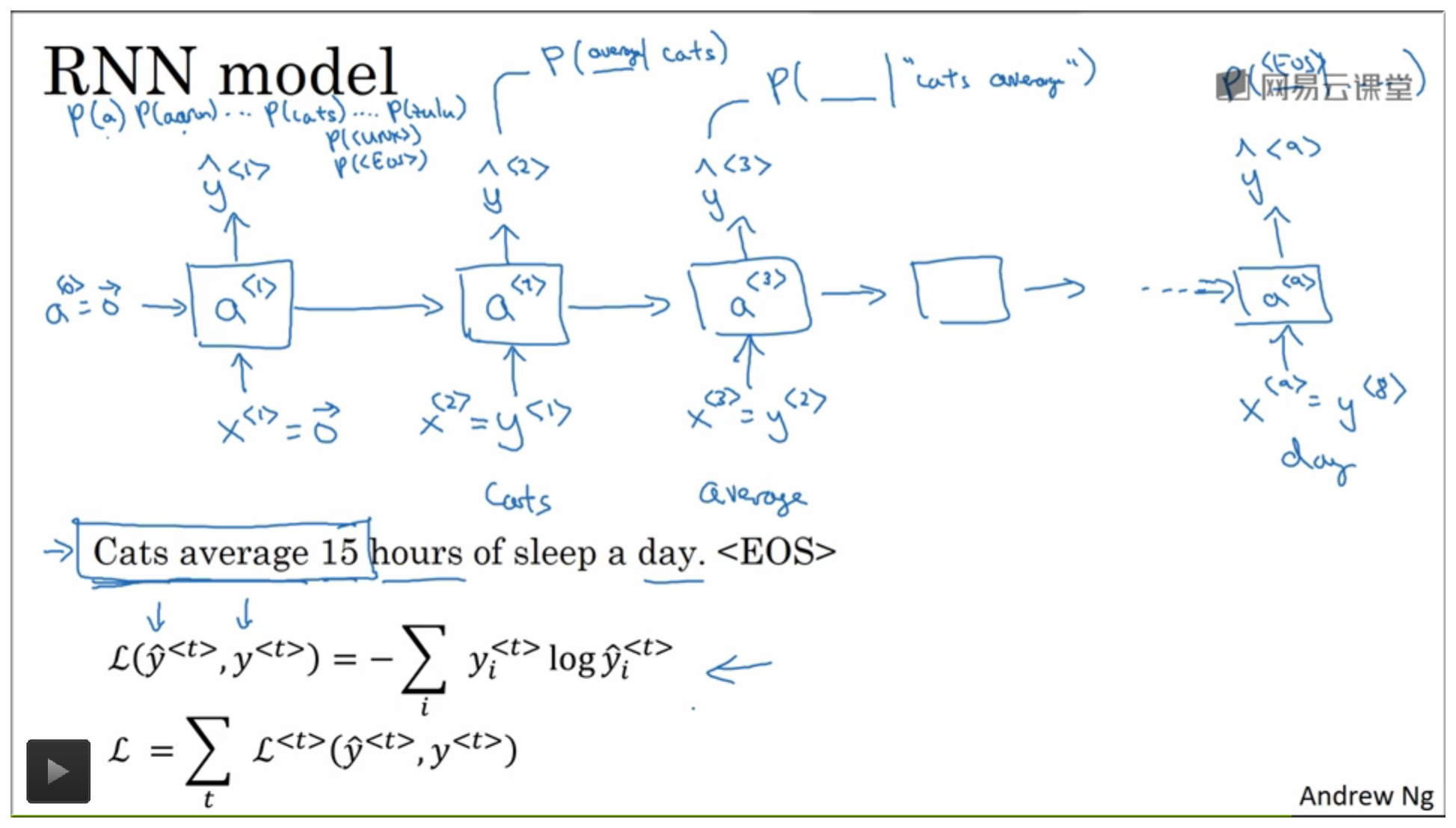
3. 计算出损失值:
下图给出了构建模型的过程以及损失值计算公式:
随着训练的次数的增多,或者常用词出现的频率的增多,语言模型便慢慢的会开始掌握简单的词语比如“平均”,“每天”,“小时”。一个完善的语言模型看到类似“ 10 个小”的时候,应该就能准确的判定下一个字是“时”。
(当然也许实际情况是“ 10 个小朋友”,所以通常会有更多的判断因素,这里只是一个例子)
7. Sampling novel sequences
当训练得到了一个模型之后,如想知道这个模型学到了些什么,一个非正式的方法就是对新序列进行采样。具体方法如下:
在每一步输出 时,通常使用 softmax 作为激活函数,然后根据输出的分布,随机选择一个值,也就是对应的一个字 或 英文单词。 然后将这个值作为下一个单元的 输入进去 (即 , 直到我们输出了终结符,或者输出长度超过了提前的预设值 n 才停止采样.
上述步骤具体如图示:
下图给出了采样之后得到的效果:
- 左边是对训练得到新闻信息模型进行采样得到的内容;
- 右边是莎士比亚模型采样得到的内容.

8. Vanishing gradients with RNNs
现在你已经学会了 基本的 RNN 如何应用在 比如 语言模型 还有 如何用反向传播来训练你的 RNN 模型, 但是还有一个问题就是 梯度消失 与 梯度爆炸 问题.
目前这种基本的 RNN 也不擅长捕获这种长期依赖效应.
梯度爆炸可以用梯度消减解决、梯度消失就有点麻烦了,需要用 GRU 来解决.
RNN 的梯度消失、爆炸问题:
梯度值在 RNN 中也可能因为反向传播的层次太多导致过小 或 过大
- 当梯度值过小的时候,神经网络将无法有效地调整自己的权重矩阵导致训练效果不佳,称之为**“梯度消失问题”(gradient vanishing problem)**;
- 过大时可能直接影响到程序的运作因为程序已经无法存储那么大的值,直接返回 NaN ,称之为**“梯度爆炸问题”(gradient exploding problem)**
当梯度值过大的时候有一个比较简便的解决方法,每次将返回的梯度值进行检查,如果超出了预定的范围,则手动设置为范围的边界值.
1 | if (gradient > max) { |
但梯度值过小的解决方案要稍微复杂一点,比如下面两句话:
“The cat,which already ate apple,yogurt,banana,…, was full.”
“The cats,which already ate apple,yogurt,banana,…, were full.”
重点标出的 cat(s) 和 be 动词(was, were) 是有很重要的关联的,但是中间隔了一个 which 引导的定语从句,对于前面所介绍的基础的 RNN网络 很难学习到这个信息,尤其是当出现梯度消失时,而且这种情况很容易发生.
我们知道一旦神经网络层次很多时,反向传播很难影响前面层次的参数。所以为了 解决梯度消失 问题,提出了 GRU单元,下面一节具体介绍.
将在接下来的两个章节介绍两种方法来解决 梯度过小 问题,目标是当一些重要的单词离得很远的时候,比如例子中的 “cat” 和 “was”,能让语言模型准确的输出单数人称过去时的 “was”,而不是 “is” 或者 “were”. 两个方法都将引入“记忆”的概念,也就是为 RNN 赋予一个记忆的功能.
9. GRU - Gated Recurrent Unit
GRU(Gated Recurrent Unit)是一种用来解决梯度值过小的方法,首先来看下在一个时刻下的 RNN单元,激活函数为 tanh
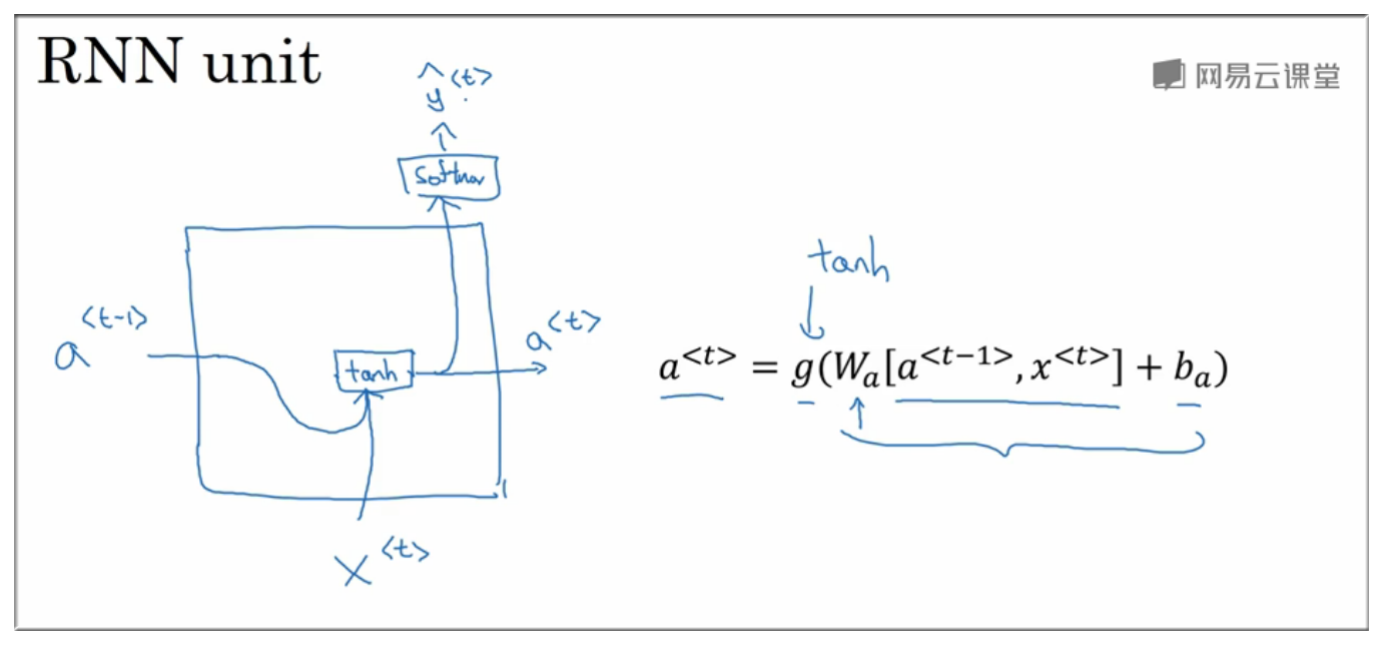
9.1 回顾普通 RNN单元 的结构
如图示,输入数据为 和 , 与参数 进行线性运算后再使用 函数 转化得到 . 当然再使用 softmax 函数处理可以得到预测值.
9.2 GRU结构
记忆细胞:
在 GRU中 会用到 “记忆细胞(Memory cell)” 这个概念, 我们用变量C表示。这个记忆细胞提供了记忆功能,例如它能够帮助记住 cat 对应 was, cats 对应 were.
而在 时刻,记忆细胞所包含的值其实就是 Activation function 值,即
注意:在这里两个变量的值虽然一样,但是含义不同。
另外在下节将介绍的 LSTM 中,二者值的大小有可能是不一样的,所以有必要使用这两种变量进行区分
为了更新记忆细胞的值,我们引入 来作为候选值从而来更新 ,其公式为:
更新门 (update gate):
更新门是 GRU 的核心概念,它的作用是用于判断是否需要进行更新.
更新门用 表示,其公式为:
如上图示, 值的大小大多分布在 0 或者 1,所以可以将其值的大小粗略的视为 0 或者 1。这就是为什么我们就可以将其理解为一扇门,如果 , 就表示此时需要更新值,反之不用.
时刻记忆细胞:
有了更新门公式后,我们则可以给出 时刻 Memory cell 的值的计算公式了:
c^{<{t}>} = \Gamma\_u \* \tilde{c} + (1-\Gamma\_u) \* c^{<{t-1}>}
注意:上面公式中的 * 表示元素之间进行乘法运算,而其他公式是 矩阵运算
公式很好理解,如果 ,那么 时刻 记忆细胞的值就等于候选值 , 反之等于前一时刻记忆细胞的值.
下图给出了该公式很直观的解释:
在读到 “cat” 的时候 ,其他时候一直为 0,知道要 输出 “was” 的时刻我们仍然知道 “cat” 的存在,也就知道它为单数了
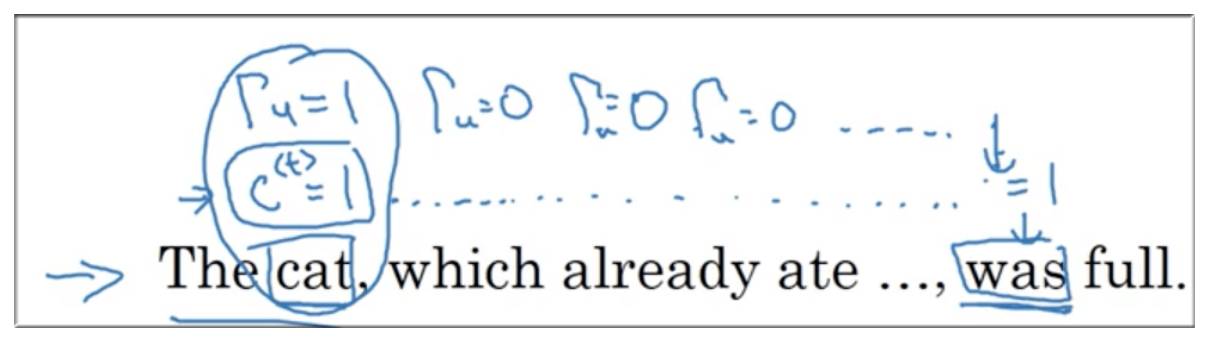
GRU 结构示意图
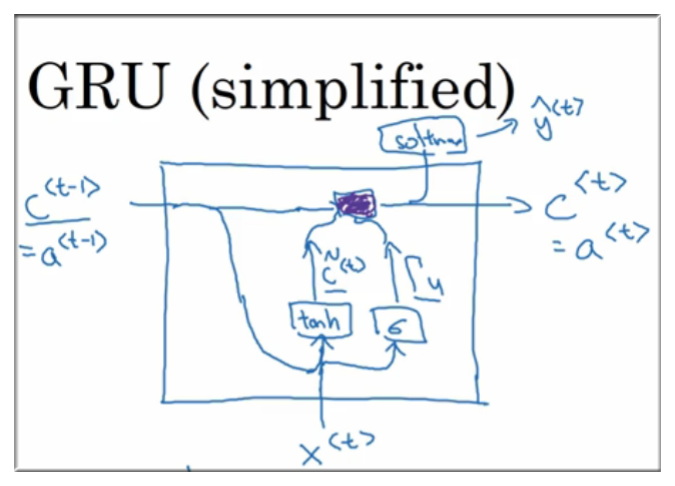
9.3 完整版 GRU
上简化了的 GRU,在完整版中还存在另一个符号 ,这符号的意义是控制 和 之间的联系强弱,完整版公式如下:
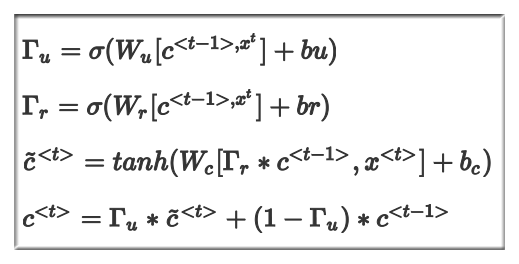
注意,完整公式中多出了一个 , 这个符号的作用是控制 和 之间联系的强弱.
10. LSTM(long short term memory)unit
介绍完 GRU 后,再介绍 LSTM 会更加容易理解。下图是二者公式对比:
GRU 只有两个门,而 LSTM 有三个门,分别是更新门 (是否需要更新为 ,遗忘门 (是否需要丢弃上一个时刻的值),输出门 (是否需要输出本时刻的值)


虽然 LSTM 比 GRU 更复杂,但是它比 GRU 更早提出哇😄。另外一般而言 LSTM 的表现要更好,但是计算量更大,毕竟多了一个门嘛。而 GRU 实际上是对 LSTM 的简化,它的表现也不错,能够更好地扩展到深层网络。所以二者各有优势。
下图是 LSTM 的结构示意图:
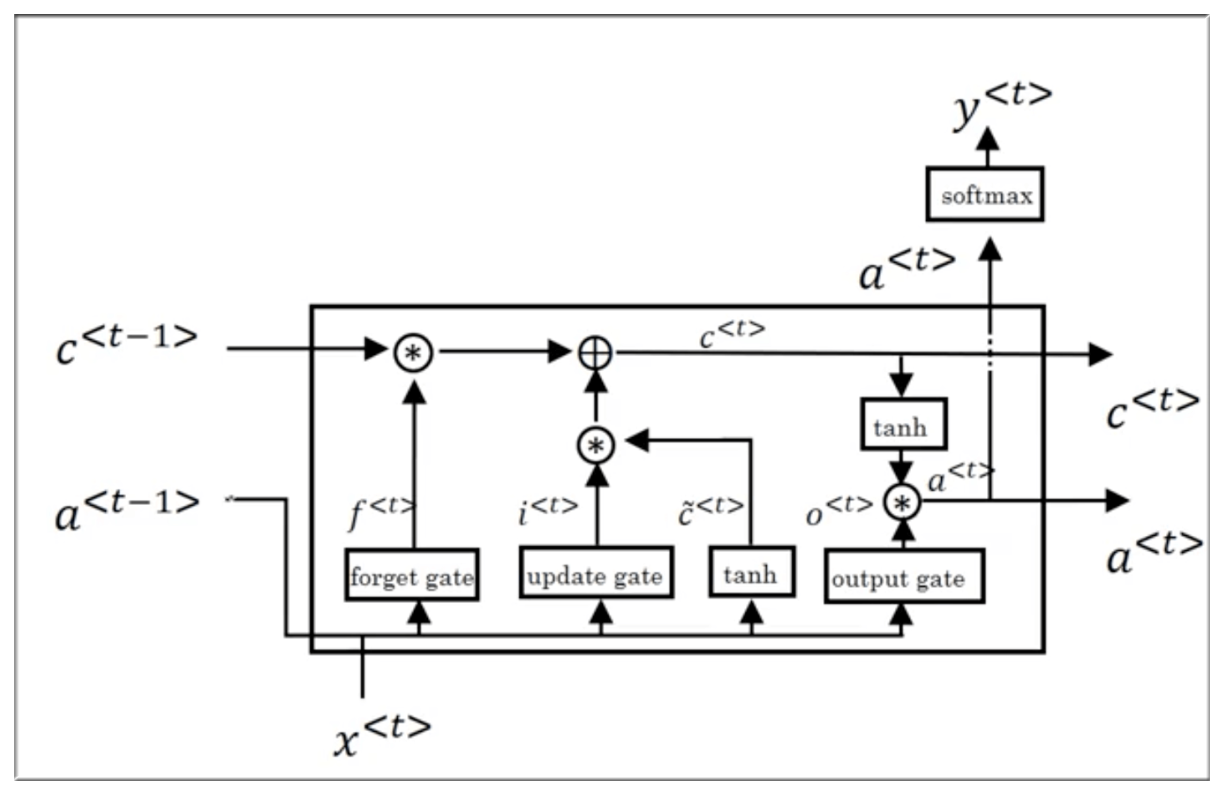
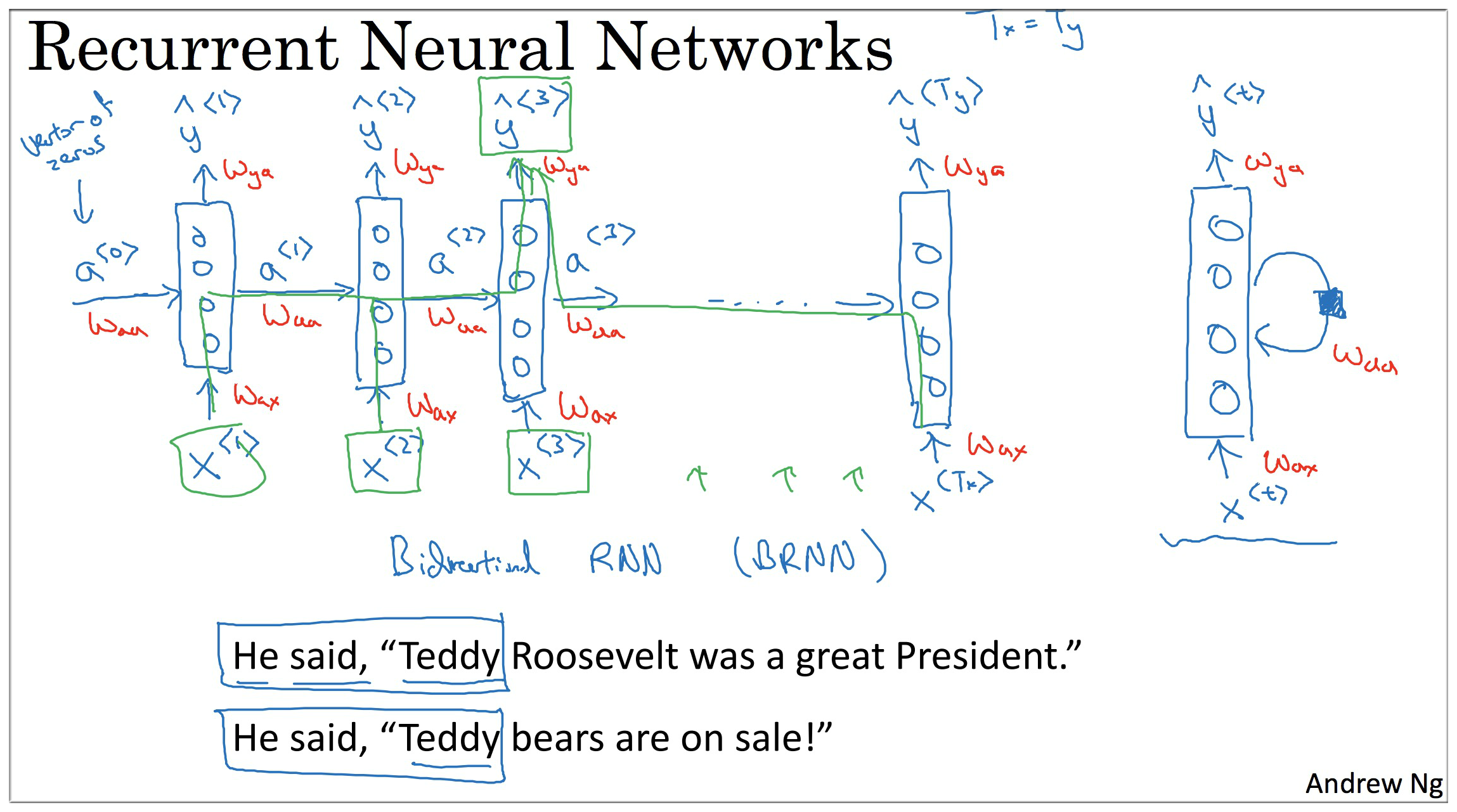
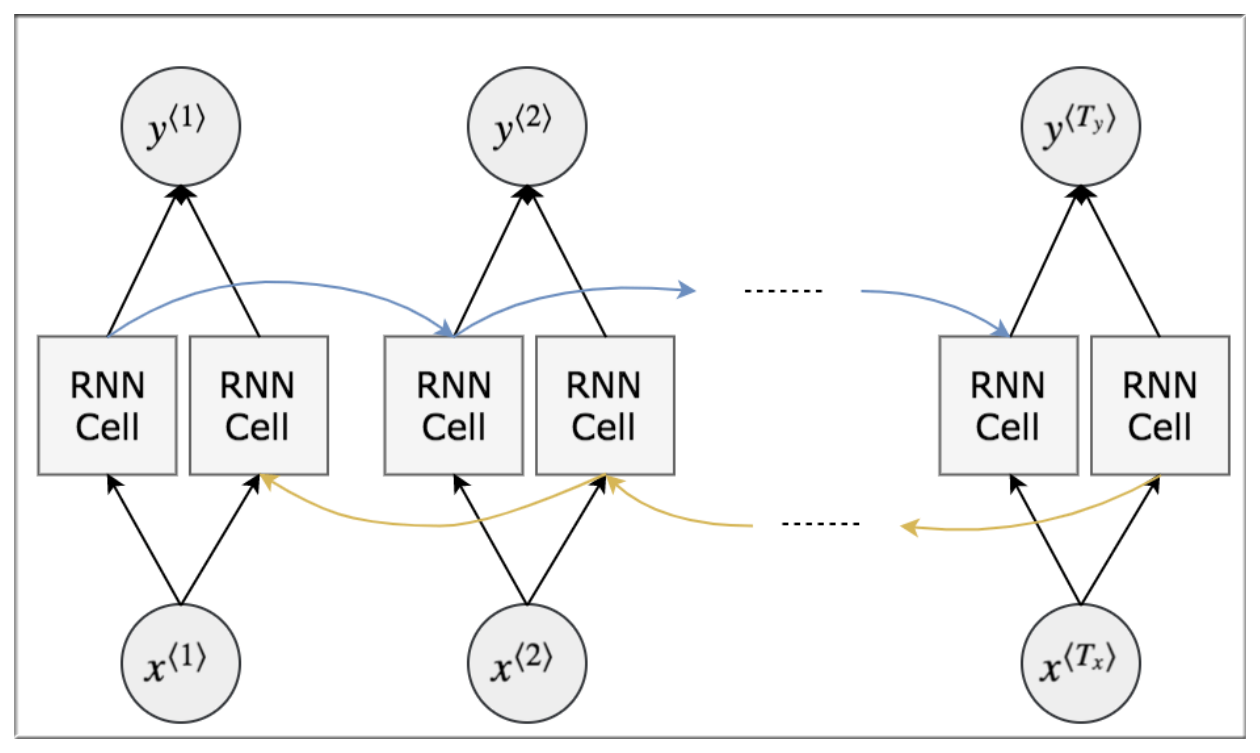
11. Bidirectional RNN
前面介绍的都是单向的 RNN 结构,在处理某些问题上得到的效果不尽人意
如下面两句话,我们要从中标出人名:
Hesaid, “Teddy Roosevelt was a great President”.
Hesaid, “Teddy bears are on sale”.
- 第一句中的 Teddy Roosevelt 是人名
- 第二句中的 Teddy bears 是泰迪熊,同样都是单词 Teddy 对应的输出在第一句中应该是 1,第二句中应该是 0
像这样的例子如果想让我们的序列模型明白就需要借助不同的结构比如 - 双向递归神经网络(Bidirectional RNN).
该神经网络首先从正面理解一遍这句话,再从反方向理解一遍.
双向递归神经网络结构如下:
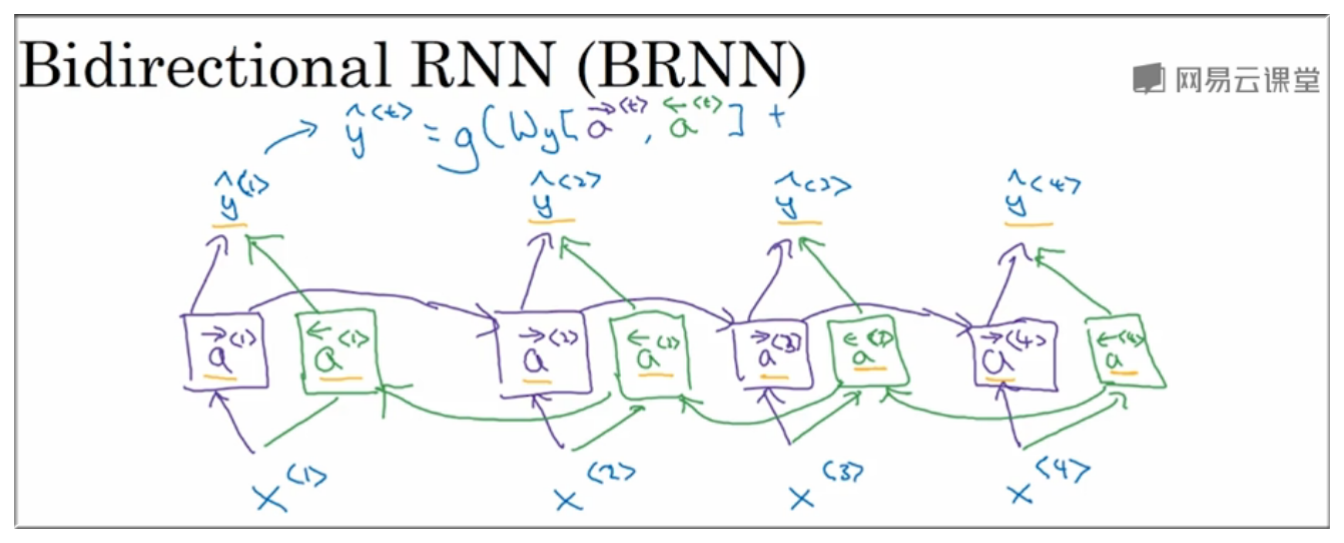
下图摘自大数据文摘整理
12. Deep RNNs
深层,顾名思义就是层次增加。如下图是深层循环神经网络的示意图
横向表示时间展开,纵向则是层次展开。
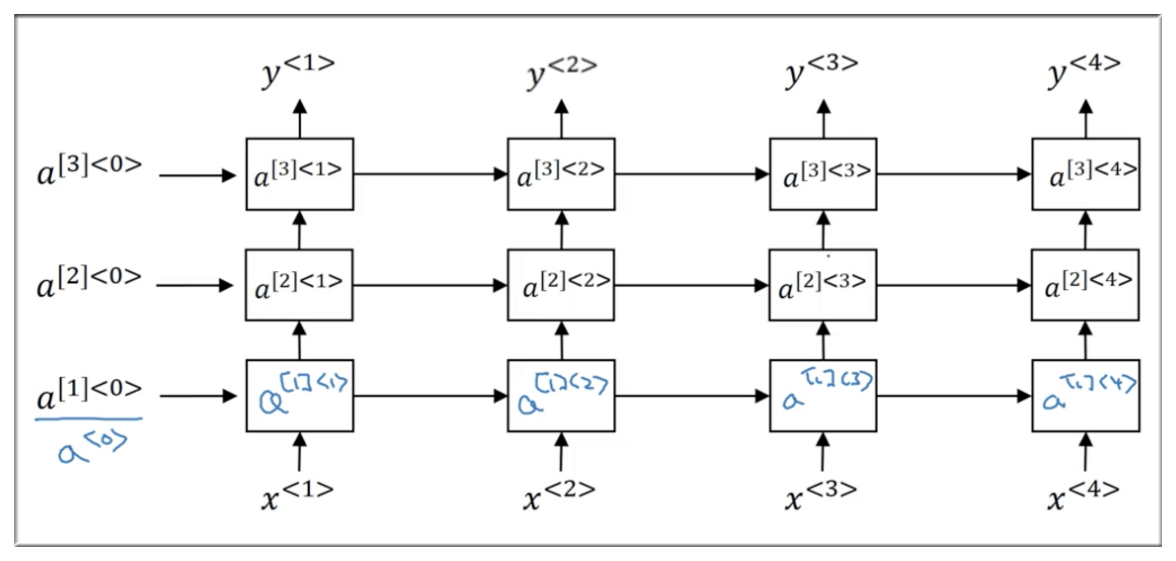
注意激活值的表达形式有所改变,以 a^{\[1\]<0>} 为例进行解释:
- 1 表示第一层
- <0> 表示第一个激活值
另外各个激活值的计算公式也略有不同,以 a^{\[2\]<3>} 为例,其计算公式如下:
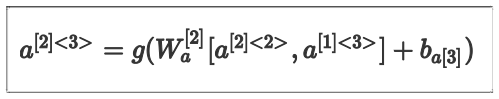
Checking if Disqus is accessible...