Structured Machine Learning Projects (week2) - ML Strategy 2
如何进行 误差分析、标注错误数据、定位数据不匹配偏差与方差
知道如何应用端到端学习、迁移学习以及多任务学习
1. Carrying out error analysis
很多时候我们发现训练出来的模型有误差后,就会一股脑的想着法子去减少误差。想法固然好,但是有点 headlong 。。
这节视频中 Andrew Ng 介绍了一个比较科学的方法,具体的看下面的例子
还是以猫分类器为例,假设我们的模型表现的还不错,但是依旧存在误差,预测后错误标记的数据中有一部分狗图片被错误的标记成了猫。这个时候按照一般的思路可能是想通过训练出狗分类器模型来提高猫分类器,或者其他的办法,反正就是要让分类器更好地区分狗和猫。
但是现在的问题是,假如错误分类的100个样本中,只有5个狗样本被错误的标记成了猫,那么你费尽千辛万苦也最多只能提高一丢丢的准确度。所以对误差进行分析就显得比较重要,而且可以帮助我们在未来的工作中指明优化方向,节省时间。具体的方法按吴大大的说法是可以人工的对错误标记的样本进行再处理、分析。
下面以一个例子来介绍一下操作步骤
1. 人工标记
将错误标记样本以表格的形式列举出来,然后人工的标记处样本的分类,统计各分类(或者说错误标记的原因)所占比例.
| Image | Dog | Great cats(大型猫科动物,如狮子) | Blurry(图片模糊) | Comments |
|---|---|---|---|---|
| 1 | √ | |||
| 2 | √ | 眯着眼 | ||
| 3 | √ | √ | 在动物园,且下着雨 | |
| … | ||||
| % of total | 8% | 43% | 61% | - |
注意:上面的分类并不是互相独立的,只是举个例子。。。抄下 Andrew Ng 的PPT
2. 分析误差
上面的结果可以知道,误差样本中只有8%是狗狗的图片,而43%是大型猫科动物,61%是因为图片模糊。很显然此时你即使用毕生所学去优化区别狗和猫的算法,整个模型的准确率提升的空间也远不如后两个特征高。所以如果人手够的话,也是可以选择几个特征进行优化的。
2. Cleaning up Incorrectly labeled data
机器预测可能会出错,那么人当然也有可能会出错。所以如果训练集和验证集中认为添加的标签Y出现误差该怎么处理呢?
这里分两种情况:
1.随机误差
这种情况比较好,因为如果人为误差比较接近随机误差,那么可以睁一只眼闭一只眼,因为深度学习算法对于随机误差还是有一定的健壮性的
2.非随机误差
PS:不知道有没有非随机误差这个词。。我只是为了行文方便取的一个名字。
对于随机误差正常人可能都会问“what?我怎么知道是不是接近随机误差”,所以视频里 Andrew Ng 也给咱们提供了一个方法,这个方法和上一节中的表格法一样一样的:
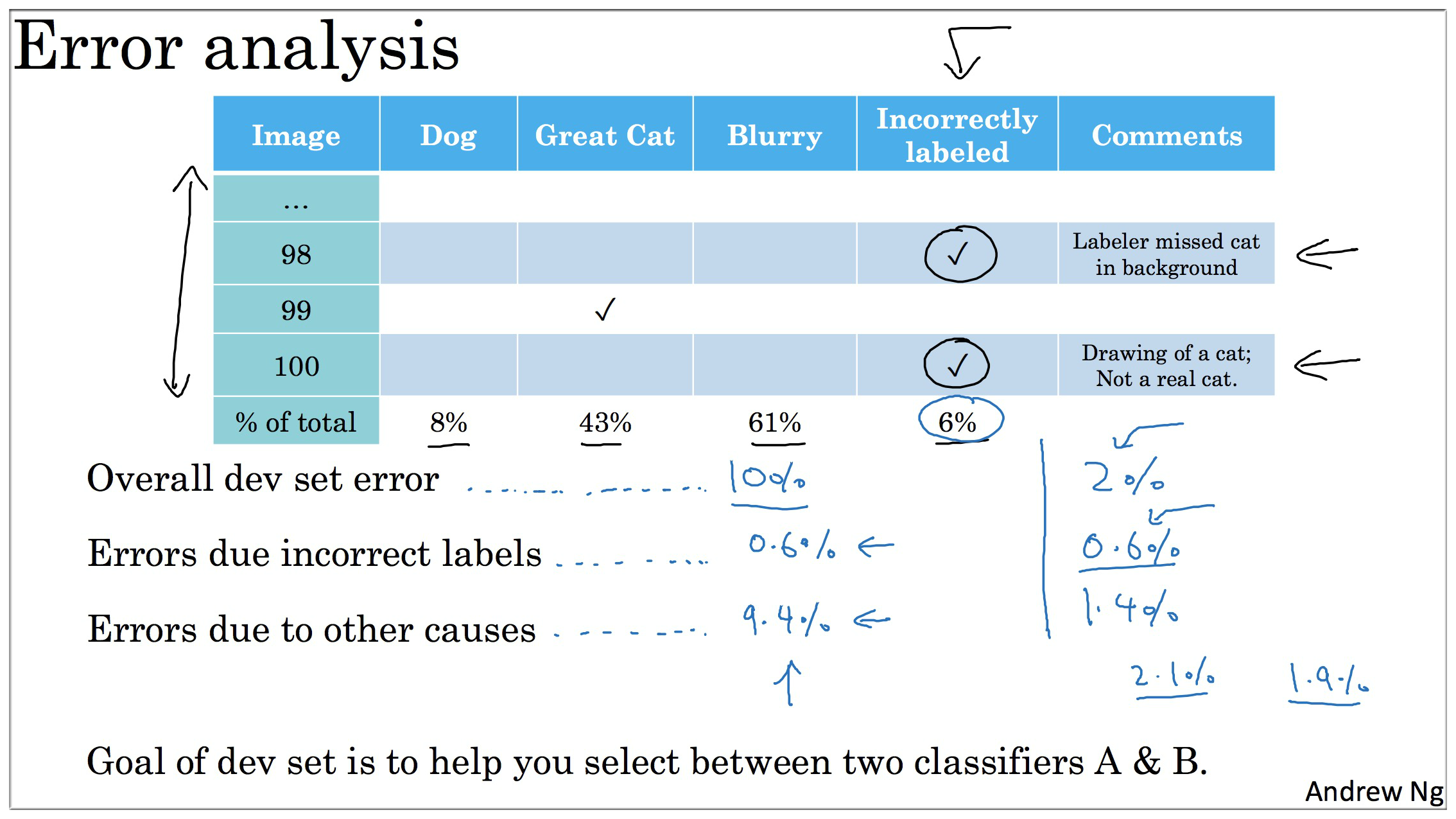
| Image | Dog | Great cats(大型猫科动物,如狮子) | Blurry(图片模糊) | Incorrectly labeled | Comments |
|---|---|---|---|---|---|
| 1 | √ | ||||
| 2 | √ | √ | 只是一只手画的的猫,不是真的猫 | ||
| 3 | √ | 背景的角落里有一只猫 | |||
| … | |||||
| % of total | 8% | 43% | 61% | 6% |
有了上面这个表格,那么问题来了,此时我还需要修正这6%标记错误的样本吗?还是举个例子:
假设我们有如下数据:
- 总体验证集误差:10%
- 由人工错误标记引起的错误样本比例: 0.6%
- 由其他原因引起的错误样本比例:10%-0.6%=9.4%
所以这种情况下我们应该集中精力找出引起9.4%误差的原因,并进行修正,当然如果有余力也还是可以休整一下人工错误标记的数据的。
假如你通过优化算法,减少了因其他原因引起的误差,并且使得总体验证集误差降到了2%,此时我们再分析一下:
很显然,因为并没有对人工误差进行优化,所以由人工错误标记引起的错误样本比例依旧是0.6%(这个数据可能有点不能理解,要注意这个0.6%是相对于整体验证集而言的,所以不会变), 那么人工误差在总误差中所占的比例则达到了0.6%/2%=30%,相比于之前的6%影响力打了不小哦,所以此时则应该考虑对人工误差动手了.
3. Build your first system quickly, then iterate
还是有一个步骤流程的:
- 建立训练集,验证集,测试集
- 迅速搭建初始化系统
- 使用前面提到的Bias/Variance分析和误差分析来确定接下来的优化方向
4. Training and testing on different distributions
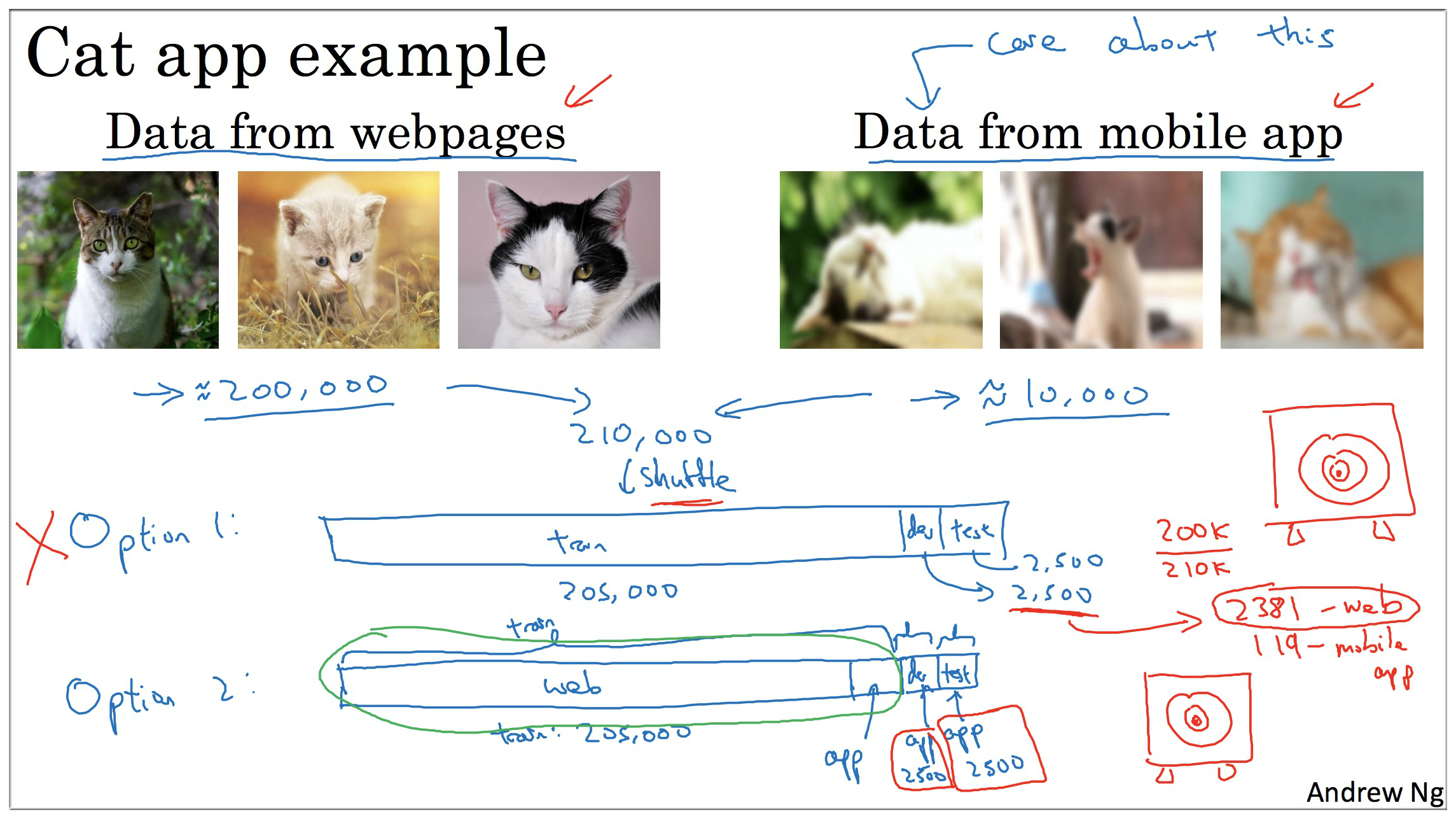
5. Bias and Variance with mismatched data distributions

对上面的PPT截图进行解释:
左边:
首先还是以喵咪分类器作为例子,假设人类的误差接近贝叶斯误差0%。而训练集误差和开发集误差分别为1%和10%,二者相差9%,而且如果两个数据集来自同一个分布,那么我们就可以说模型训练结果方差较大。
但是当两个数据集来自不同的分布时,我们就不能得出上面的结论了。另外,这9%的方差可能有两个原因导致的.
- 是我们自己实现的代码有问题
- 是数据分布不同,所以你很难确定哪个是更主要的原因.
因此为了找出是哪个原因我们做如下的事情:
创建Training-dev set(训练-开发集),其实就是从原来的训练集中抽取一部分数据出来,但是不喂给模型。(如上图所示)
右边:
那怎么操作呢?很简单,下面以几个例子来说明:
1.因为Training-dev set(训练-开发集)和Training set同分布,所以假设训练出来的结果如下:
- training error: 1%
- training-dev error: 9%
- dev error: 10%
此时可以看到来自同分布数据的训练误差和训练-开发误差存在较大的方差,所以我们就可以确定肯定是我们滴代码还需要完善.
2.假设训练出来的结果如下:
- training error: 1%
- training-dev error: 1.5%
- dev error: 10%
此时就可以说不是我程序员的问题了,而是发生了data mismatch(数据不匹配问题)
上图右下角:
1.假设人类的误差接近贝叶斯误差0,且训练误差如下:
- training error: 10%
- training-dev error: 11%
- dev error: 12%
此时我们会认为模型与人类误差相比存在较大的偏差。所以就朝着 减小偏差的方向努力 吧少年.
2.同样假设人类的误差接近贝叶斯误差0,且训练误差如下:
training error: 10%
training-dev error: 11%
dev error: 20%此时我们会认为存在两个问题:
- 高偏差
- 数据不匹配问题
祝福你,继续修改代码吧…
6. Addressing data mismatch

虽然我们使用数据合成已经在语音识别方面取得了不错的效果提升
可以使用数据合成,但是要注意你的神经网络可能过拟合,过分学习了你这小部分数据集了。
7. Transfer learning
简单的解释就是假如我们之前训练好了一个喵咪分类器,后来我们有了新任务 — 做一个海豚分类器,那么就可以将之前创建的喵咪分类器模型运用到新任务中去
举个栗子,假设我们对信号灯的红、绿灯进行了大量数据的学习,现在有了新任务,即需要识别黄灯,此时我们就不需要从头搭建模型,我们可以继续使用红绿灯网络框架,只需修改神经网络最后一层,即输出层,然后用已经训练好的权重参数初始化这个模型,对黄灯数据进行训练学习。
为什么可以这么做呢?因为尽管最后的标签不一致,但是之前学习的红绿灯模型已经捕捉和学习了很多有用的特征和细节,这对于黄灯的学习十分有帮助,而且这么做也可以大大的加快模型的构建速度。
想将
A模型运用到B模型, 一般来说是有条件限制的,如下:
- A 和 B 需要有相类似的输入数据集,例如要么都是图像识别,要么是语音识别
- A 的数据集要足够多,即远多于B
- A 中学到一些 low level features 要对 B 有所帮助
8. Multi-task learning
在 Transfer learning 中,整个过程是串行的,即咱们首先得实现A模型,然后在运用到B模型。
在 Multi-task learning 中,可以是同时开始学习.
举个🌰:
现在很火的无人驾驶汽车,在行驶路上需要识别很多类型的物体,如行人、红绿灯、指路标志等等,所以此时可以使用 Multi-task learning 来实现。神经网络示意图如下:
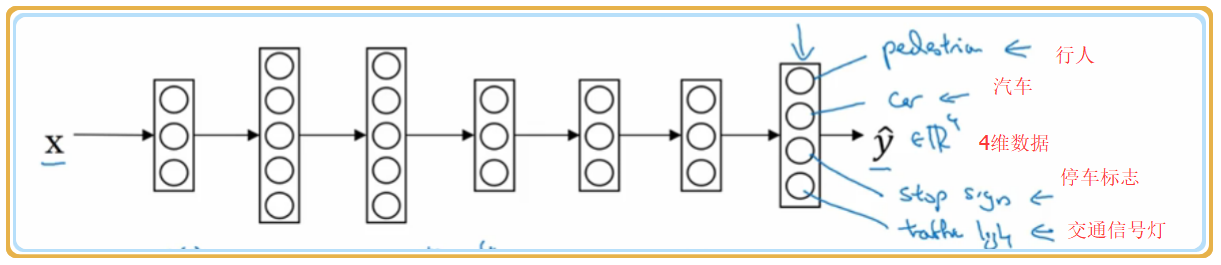
如图示,最后的 是一个有4元素的向量,假设分别是行人、汽车、停车标志、信号灯。如果识别出图片中有哪一个元素,对应位置则输出1。
注意:这要与softmax进行区分,softmax 只是一次识别一种物体,比如说识别出是行人,则输出[1,0,0,0],而不会说同时识别出行人和信号灯.
适用情况:
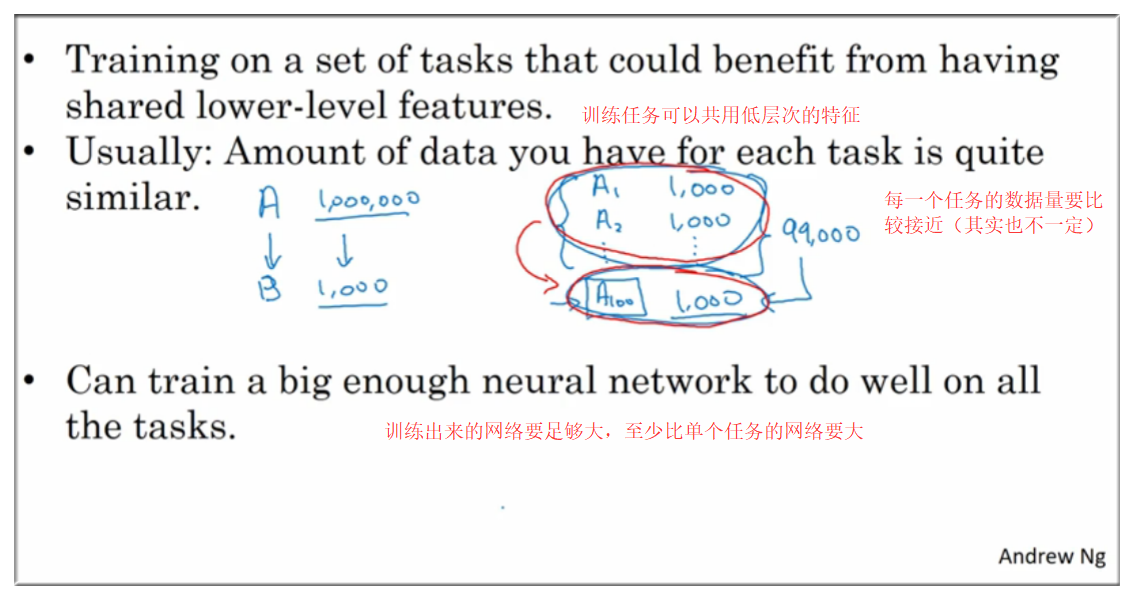
最后,Andrew Ng 说在实际中迁移学习使用频率要远高于多任务学习,有个例外就是视觉检测项目中多任务学习比较多.
9. End-to-end deep learning
首先以现在广泛使用的人脸识别技术解释一下什么是端到端的深度学习.
What is end-to-end learning?
假如咱们走进一个摄像头,最开始离得较远的时候摄像头捕捉到的是我们的全身,此时系统不会将这种照片喂给模型,而是通过算法找到人脸的位置,然后切割放大,最后喂给模型进行识别.
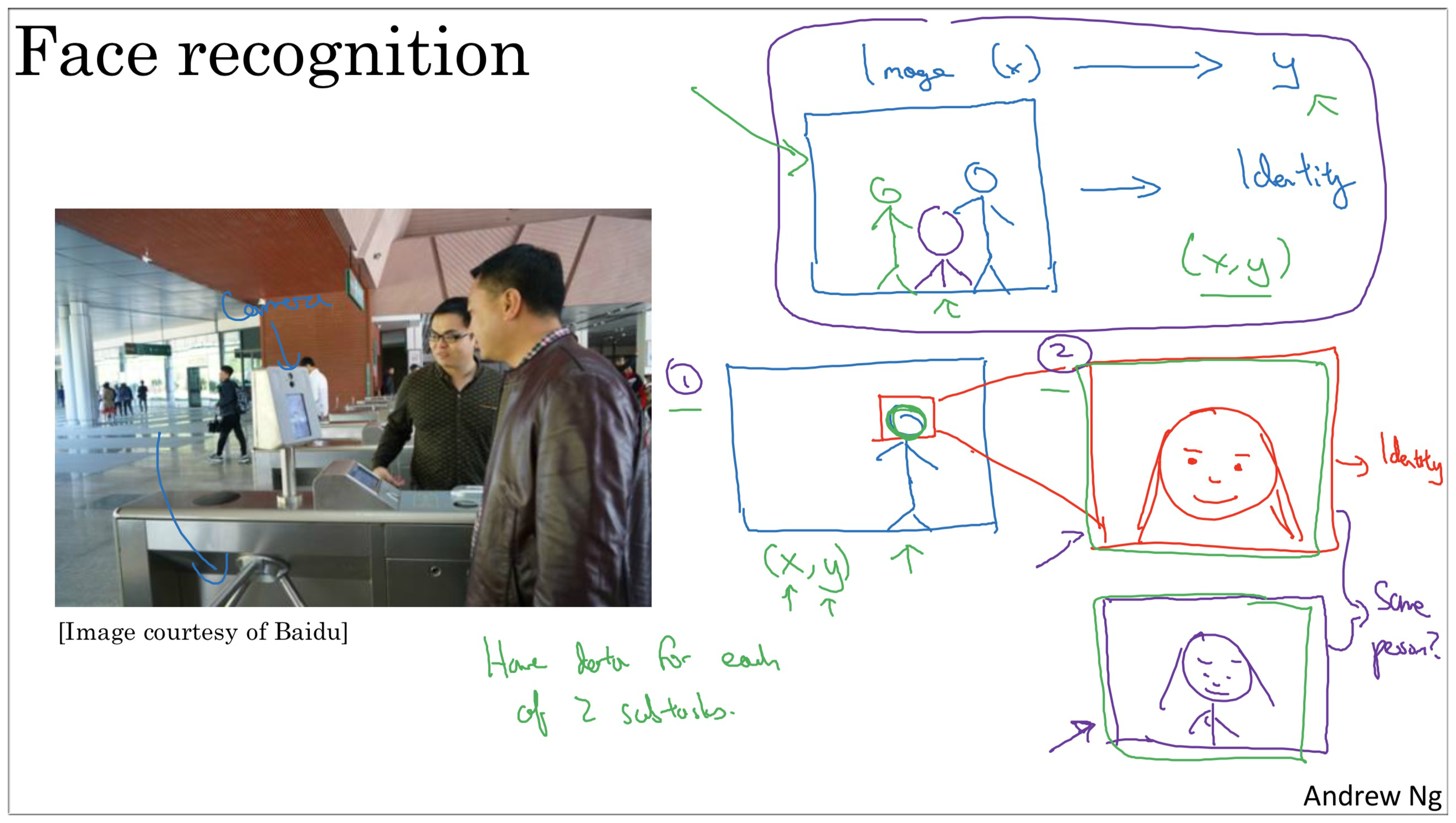
总结起来就是:
- 找人脸位置
- 将人脸图像切割放大,并喂给模型
Notes: 端到端的深度学习其实就不是像将问题细分化,流水线化,每个步骤各司其职,下一层依赖上一层
And you need a large data set before the end-to-end approach really shines. (你需要大量的数据,端到端的深度学习,才能发挥耀眼的光芒.)
10. Reference
Sequence Models (week1) - Recurrent Neural Networks
这次我们要学习专项课程中第五门课 Sequence Models. 第一周: Recurrent Neural Networks 已被证明在时间数据上表现好,它有几个变体,包括 LSTM、GR...
Structured Machine Learning Projects (week1) - ML Strategy 1
这次我们要学习专项课程中第三门课 Structured Machine Learning Projects 学完这门课之后,你将会: 理解如何诊断机器学习系统中的错误 能够优先减小误差最有效...
Checking if Disqus is accessible...