Structured Machine Learning Projects (week1) - ML Strategy 1
这次我们要学习专项课程中第三门课 Structured Machine Learning Projects
学完这门课之后,你将会:
- 理解如何诊断机器学习系统中的错误
- 能够优先减小误差最有效的方向
- 理解复杂ML设定,例如训练/测试集不匹配,比较并/或超过人的表现
- 知道如何应用端到端学习、迁移学习以及多任务学习
很多团队浪费数月甚至数年来理解这门课所教授的准则,也就是说,这门两周的课可以为你节约数月的时间
1. Why ML Strategy?

如上图示,假如我们在构建一个喵咪分类器,数据集就是上面几个图,训练之后准确率达到90%。虽然看起来挺高的,但是这显然并不具一般性,因为数据集太少了。那么此时可以想到的ML策略有哪些呢?总结如上图中
Ideas.
2. Orthogonalization
Orthogonalization [ɔ:θɒɡənəlaɪ’zeɪʃn] 正交化
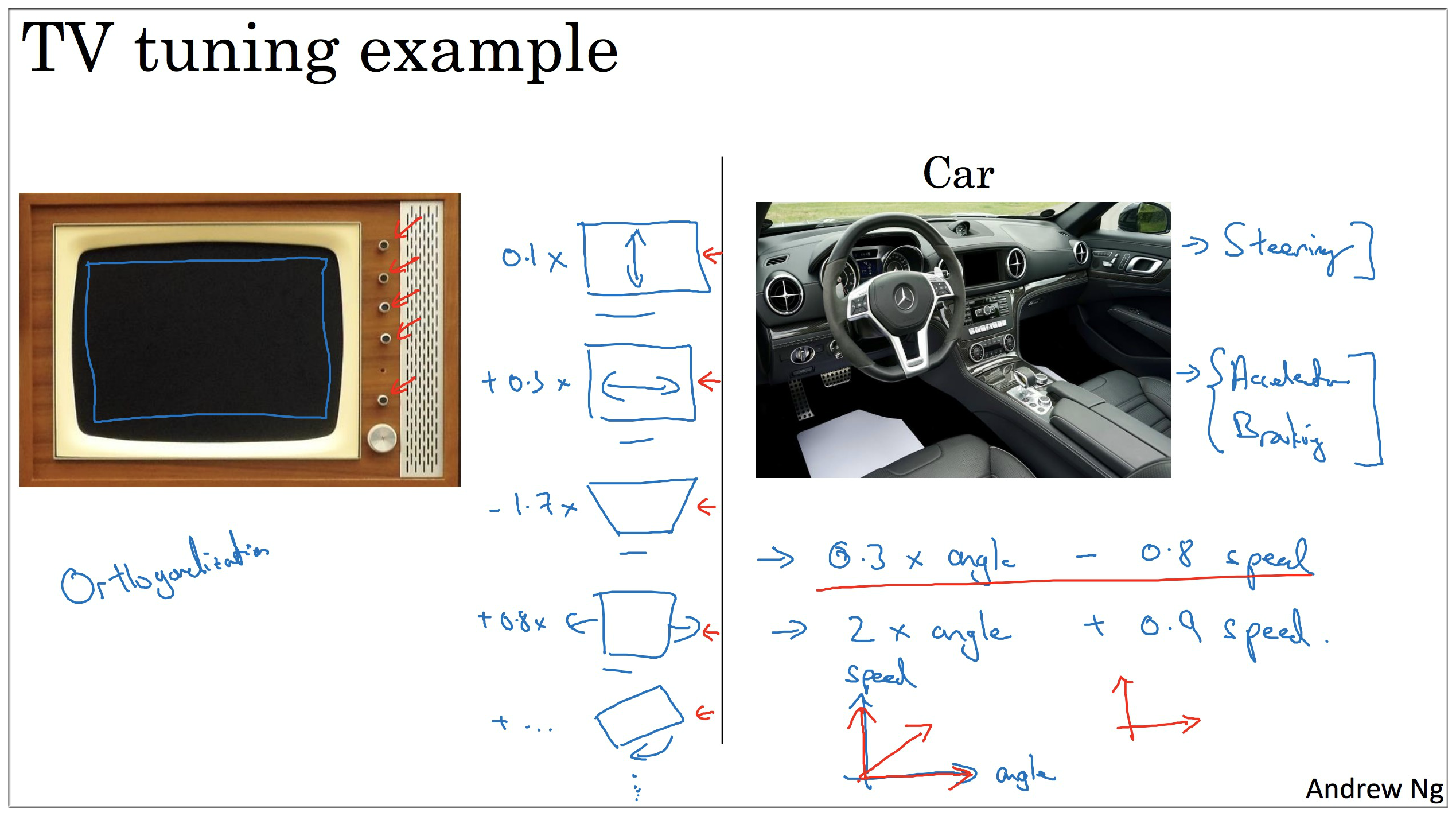
And when I train a neural network,I tend not to use early shopping.
因为 Early Stropping,这个按钮能同时影响两件事情. 就像一个按钮同时影响电视机的宽度和高度. 如果你有更多的正交化(Orthogonalization)的手段,用这些手段调网络会简单不少.
When a supervised learning system is design, these are the 4 assumptions that needs to be true and orthogonal.

| No. | strategy | solutions |
|---|---|---|
| 1. | Fit training set well in cost function | If it doesn’t fit well, the use of a bigger neural network or switching to a better optimization algorithm might help. |
| 2. | Fit development set well on cost function | If it doesn’t fit well, regularization or using bigger training set might help. |
| 3. | Fit test set well on cost function | If it doesn’t fit well, the use of a bigger development set might help |
| 4. | Performs well in real world | If it doesn’t perform well, the development test set is not set correctly or the cost function is not evaluating the right thing |
3. Single number evaluation metric
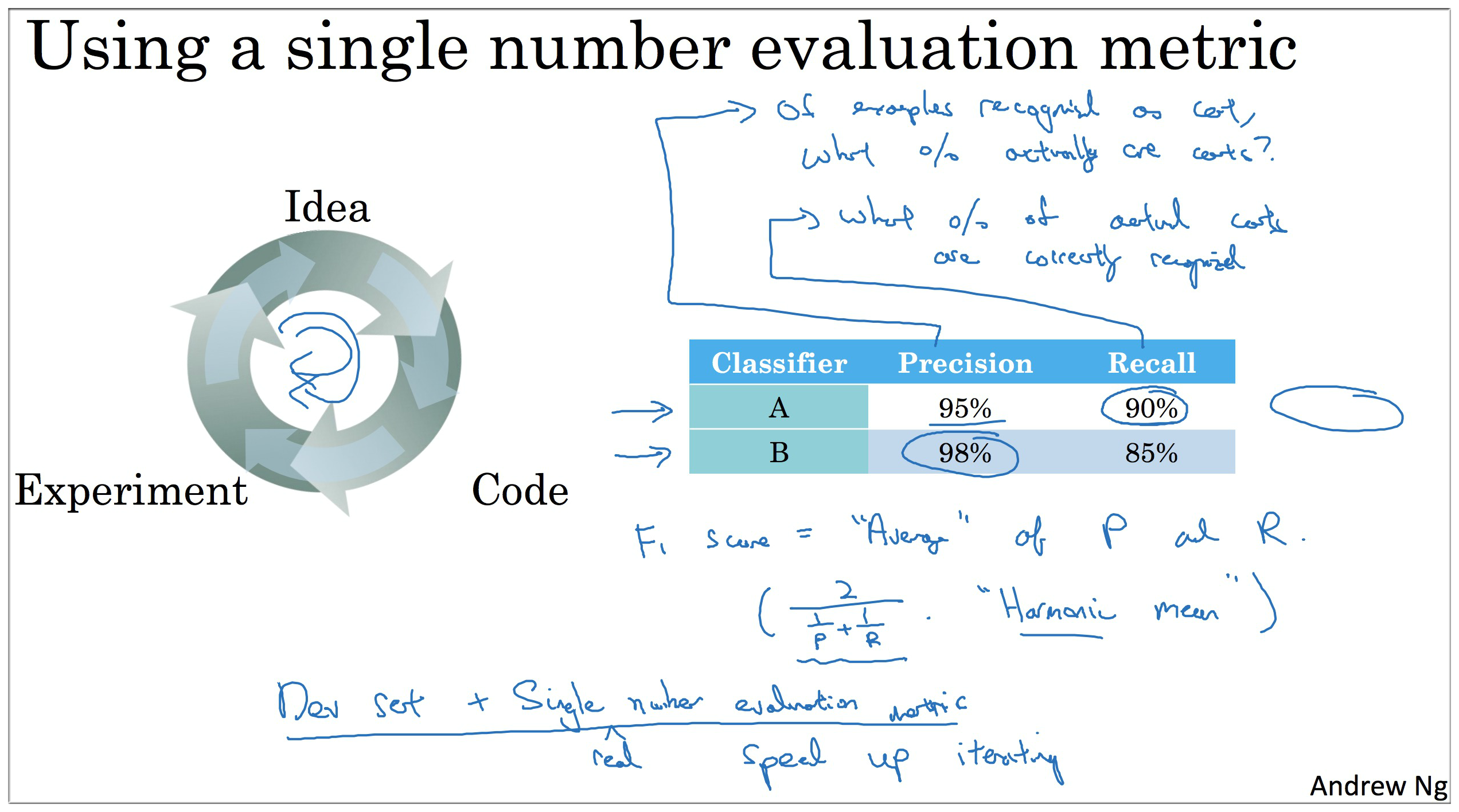
大致的思想就是首先按照单一数字评估指标对模型进行评价和优化。以精确率和召回率为例,这二者一般来说是一个不可兼得的指标,所以为了更好的衡量模型的好坏,引入F1算法来综合精确率和召回率对模型进行评估.
因此在实际操作过程中,我们可以以人类准确率为指标来评判我们训练的模型好坏程度

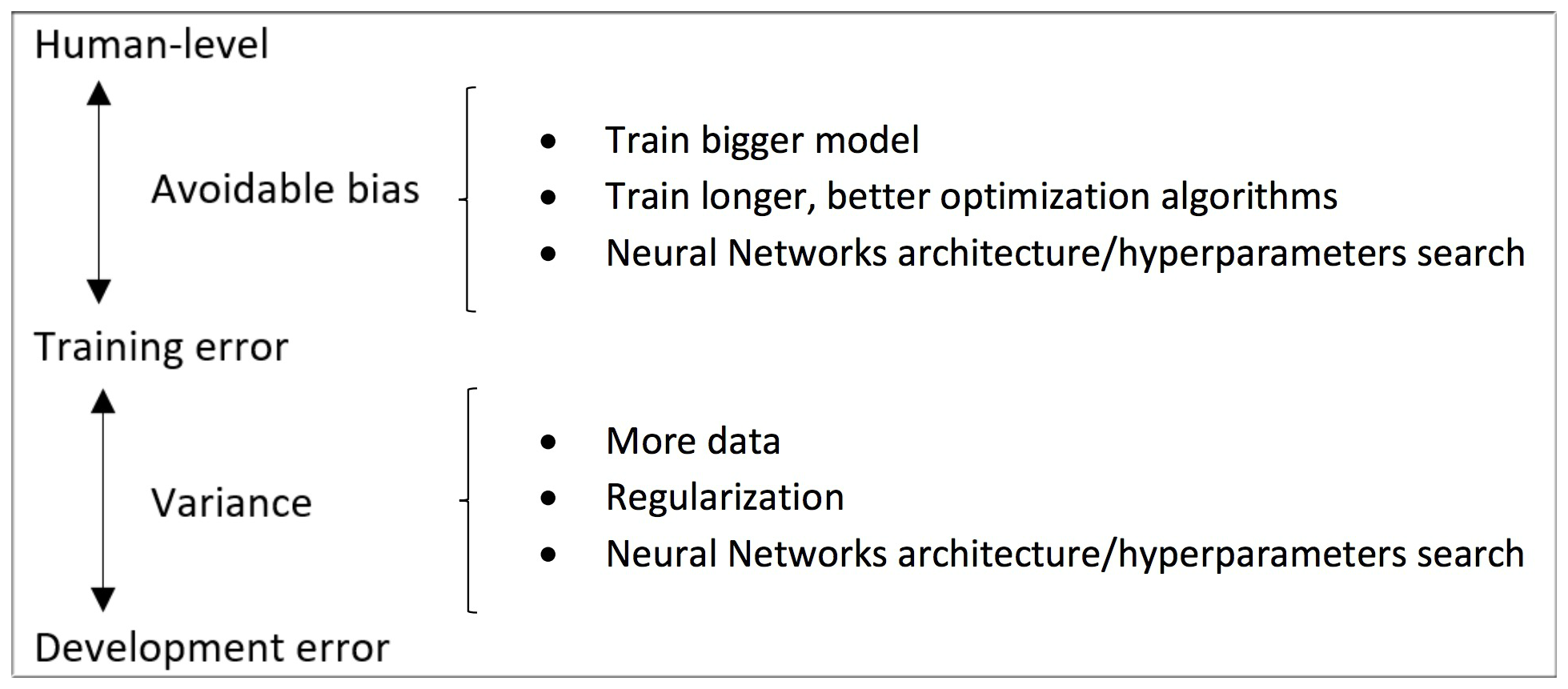
9. Avoidable bias

Humans error 与 Training Error 之间的差距我们成为 Avoidable bias
Training Error 与 Dev Error 之间的差距我们成为 Variance
10. Understanding human-level performance
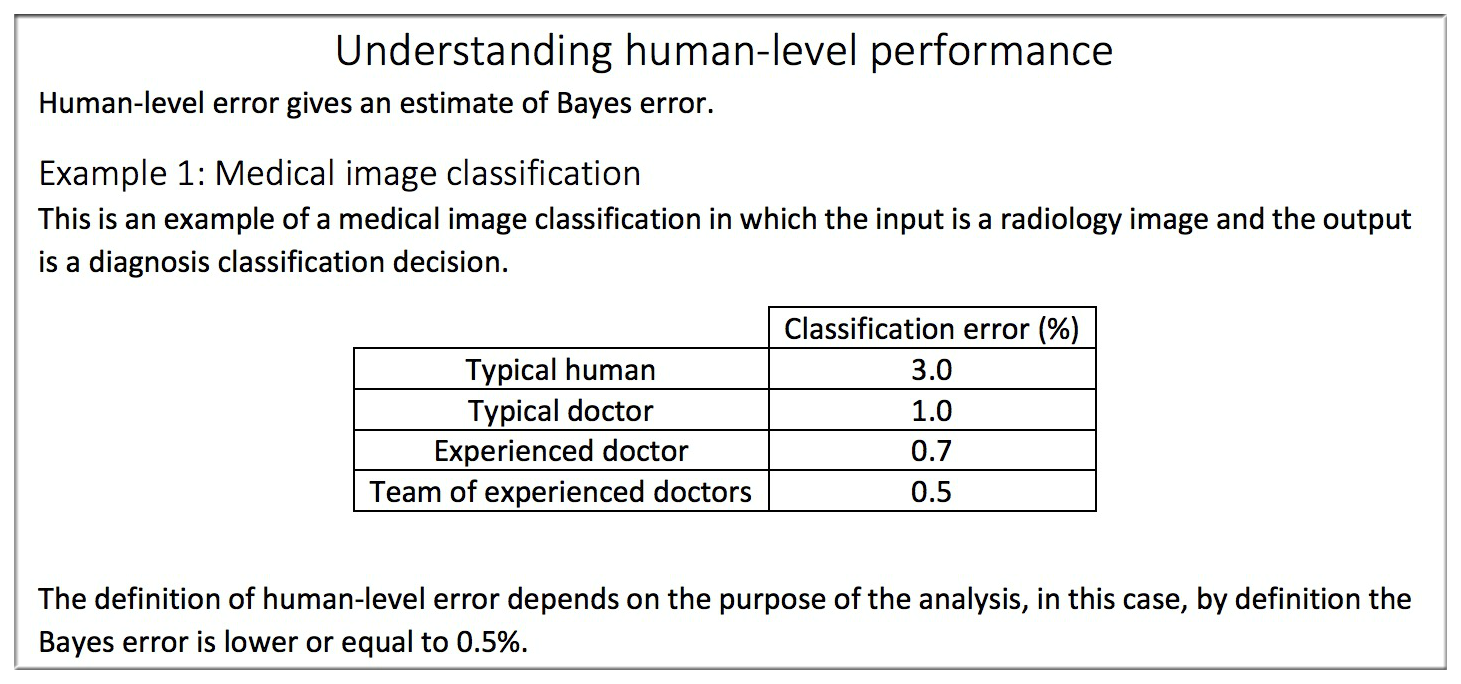
解释说明 Example 1:
假如一个医院需要对一个医学影像进行分类识别,普通人,普通医生,有经验的医生和一群有经验的医生识别错误率分别为3%,1%,0.7%,0.5%。上一节中提到过Human Error,那此时的该如何确定Human Error呢?你可能会说取平均值,只能说Too Naive!当然是取最好的结果啦,也就是由一群经验丰富的医生组成的团体得到的结果作为Human Error。另外贝叶斯误差一定小于0.5%。
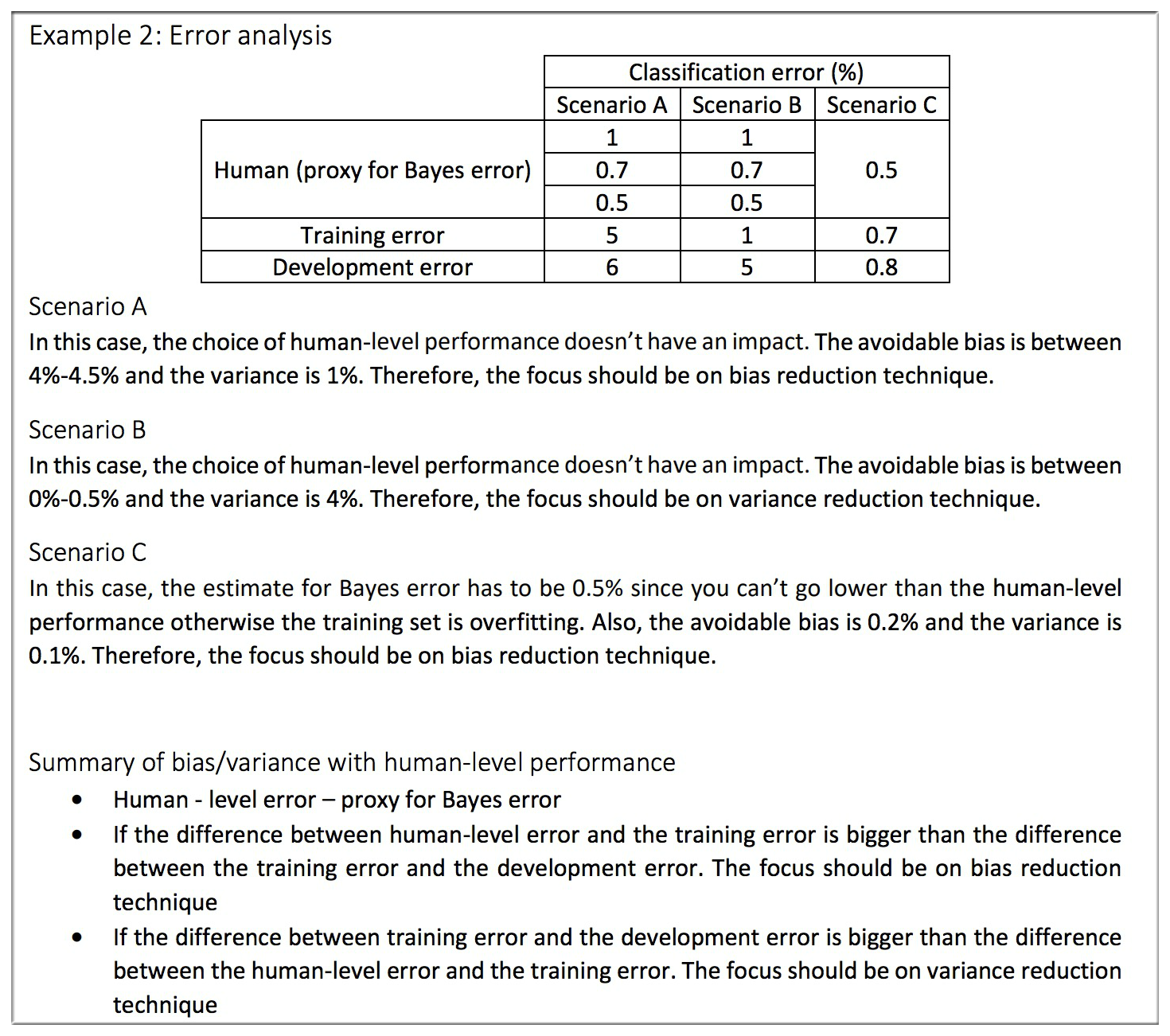
解释说明 Example 2:
还是以医学影像分类识别为例,假如现在分成了三种情况:
Scenario A
让三类人群来划分后得到的误差分别为1%,0.7%,0.5%,而训练集和测试集误差分别为5%,6%。很显然此时的Avoidable Bias=4%~4.5%,Variance=1%,bias明显大于variance,所以此时应该将重心放到减小bias上去。
Scenario Bayse
同理此情况下的Avoidable Bias=0%~0.5%,Variance=4%,所以需要减小variance。
Scenario C
Avoidable Bias=0.2%,Variance=0.1%,二者相差无几,但是此时训练的模型准确率还是不及人类,所以没办法咱们还得继续优化,都说枪打出头鸟,所以继续优化bias~
11. Surpassing human-level performance
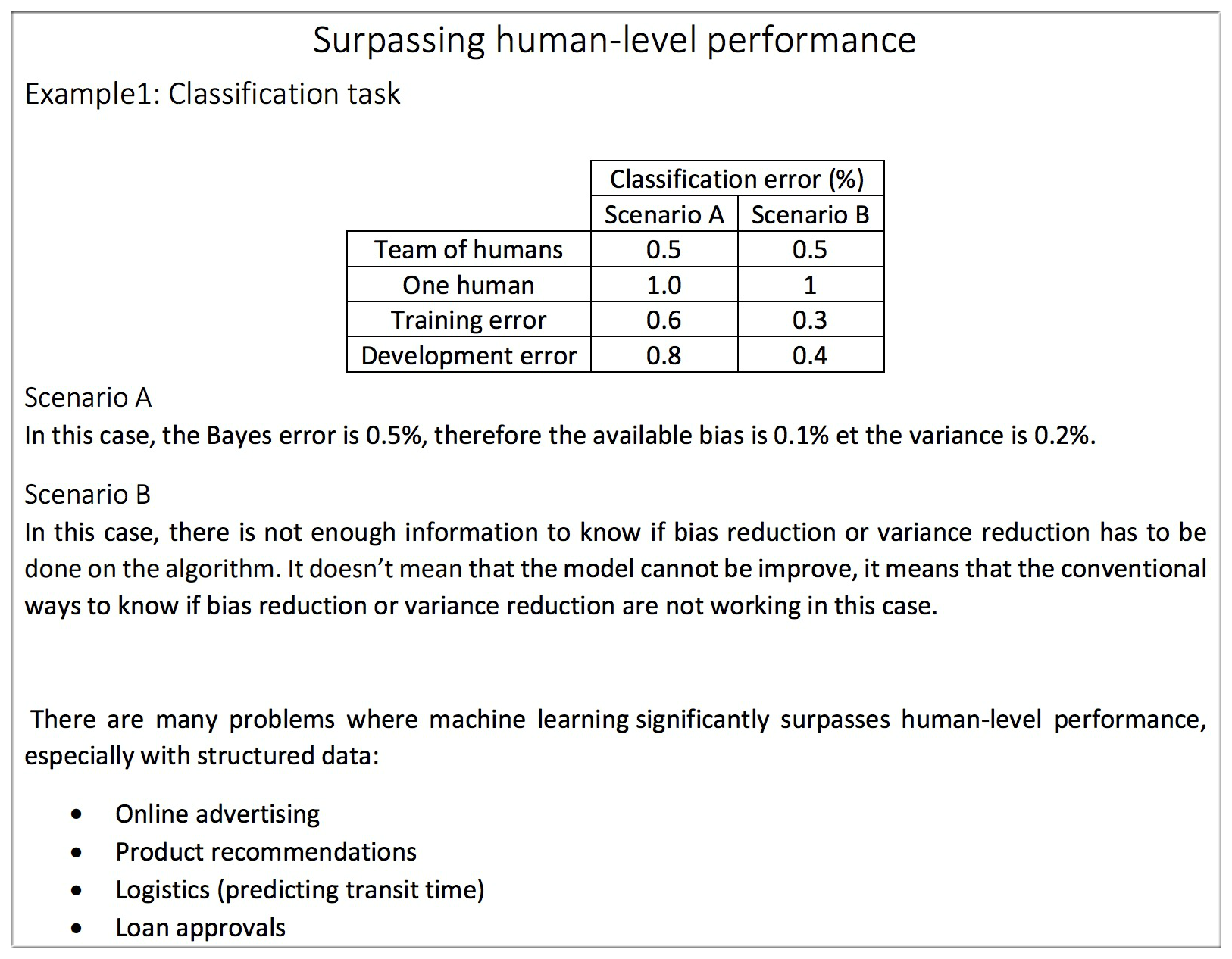
Scenario A
- Avoidable Bias=0.1%,Variance=0.2%,所以此时应该将重心放到减小Variance上去
Scenario B
- Avoidable Bias=-0.2%,Variance=0.1%.乍一看可能会有点不知所措,而且训练集准确度也超过了人的最好成绩,不知道应该选择优化哪一项了,或者说这是不是就说明可以不用再优化了呢?
(还是可以继续优化的。不可否认在图像识别方面人类的确其优于机器的方面,但是在其他方面,如在线广告推送,贷款申请评测等方面机器人要远远比人类优秀,所以如果是在上面课件中提到的一些领域,即使机器准确度超过了人类,也还有很大的优化空间。具体怎么优化。。。以后再探索。。。)
12. Improving your model performance
13. Reference
Structured Machine Learning Projects (week2) - ML Strategy 2
如何进行 误差分析、标注错误数据、定位数据不匹配偏差与方差 知道如何应用端到端学习、迁移学习以及多任务学习 1. Carrying out error analysis 很多时候我们发现训...
Improving DNN (week3) - Hyperparameter、Batch Regularization
Hyperparameter Tuning process、Normalizing Activations in a network Fitting Batch Norm into a neur...
Checking if Disqus is accessible...