Neural Networks and Deep Learning (week3) - Shallow Neural Networks
正式进入神经网络的学习. 当然, 我们先从简单的只有一个隐藏层的神经网络开始。
在学习完本周内容之后, 我们将会使用 Python 实现一个单个隐藏层的神经网络。
1. 常用符号与基本概念
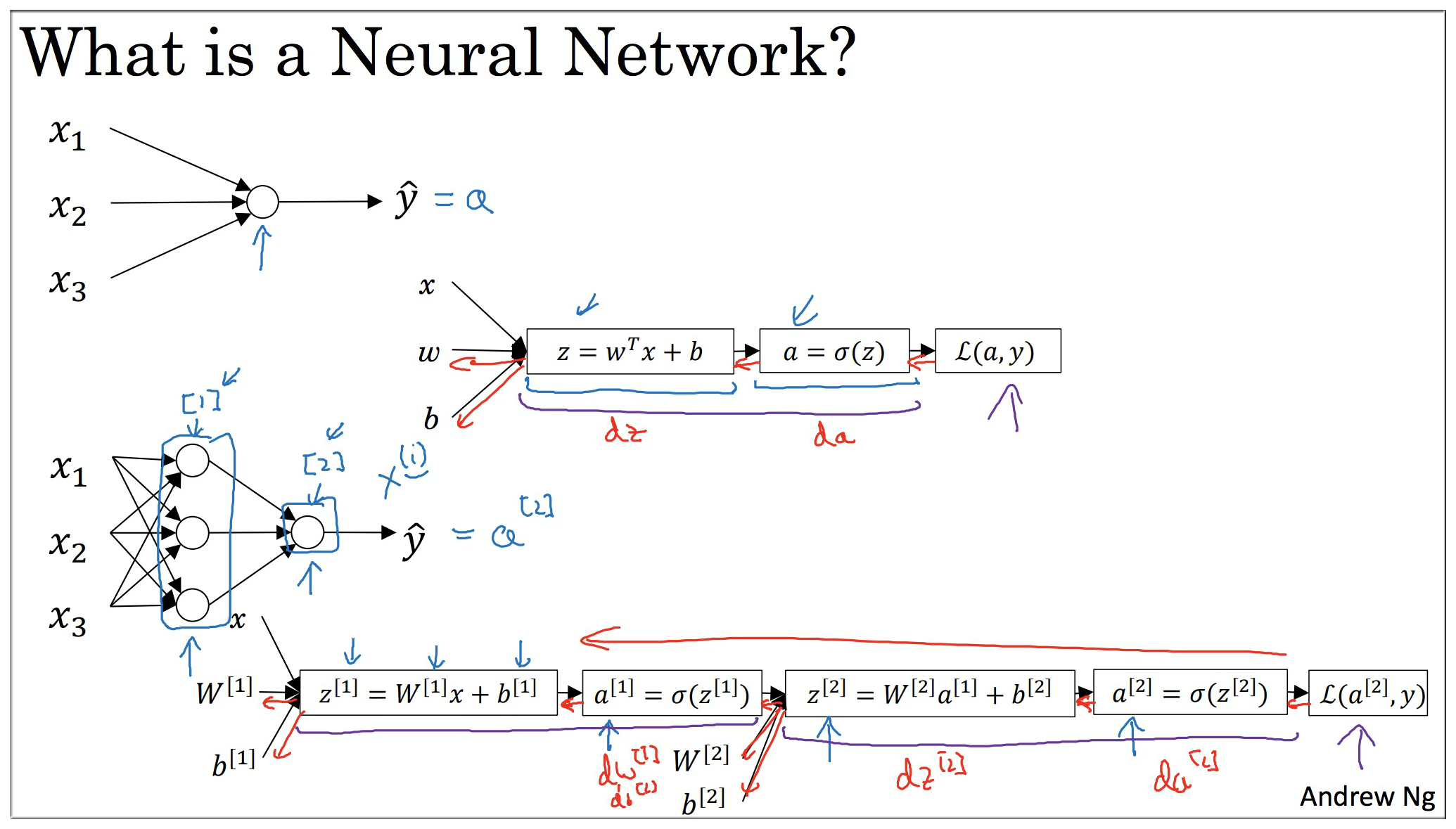
该神经网络完全可以使用上一周所讲的计算图来表示, 和 计算图的区别仅仅在于多了一个 和 的计算而已.
如果你已经完全掌握了上一周的内容, 那么其实你已经知道了神经网络的前向传播, 反向传播(梯度计算)等等.
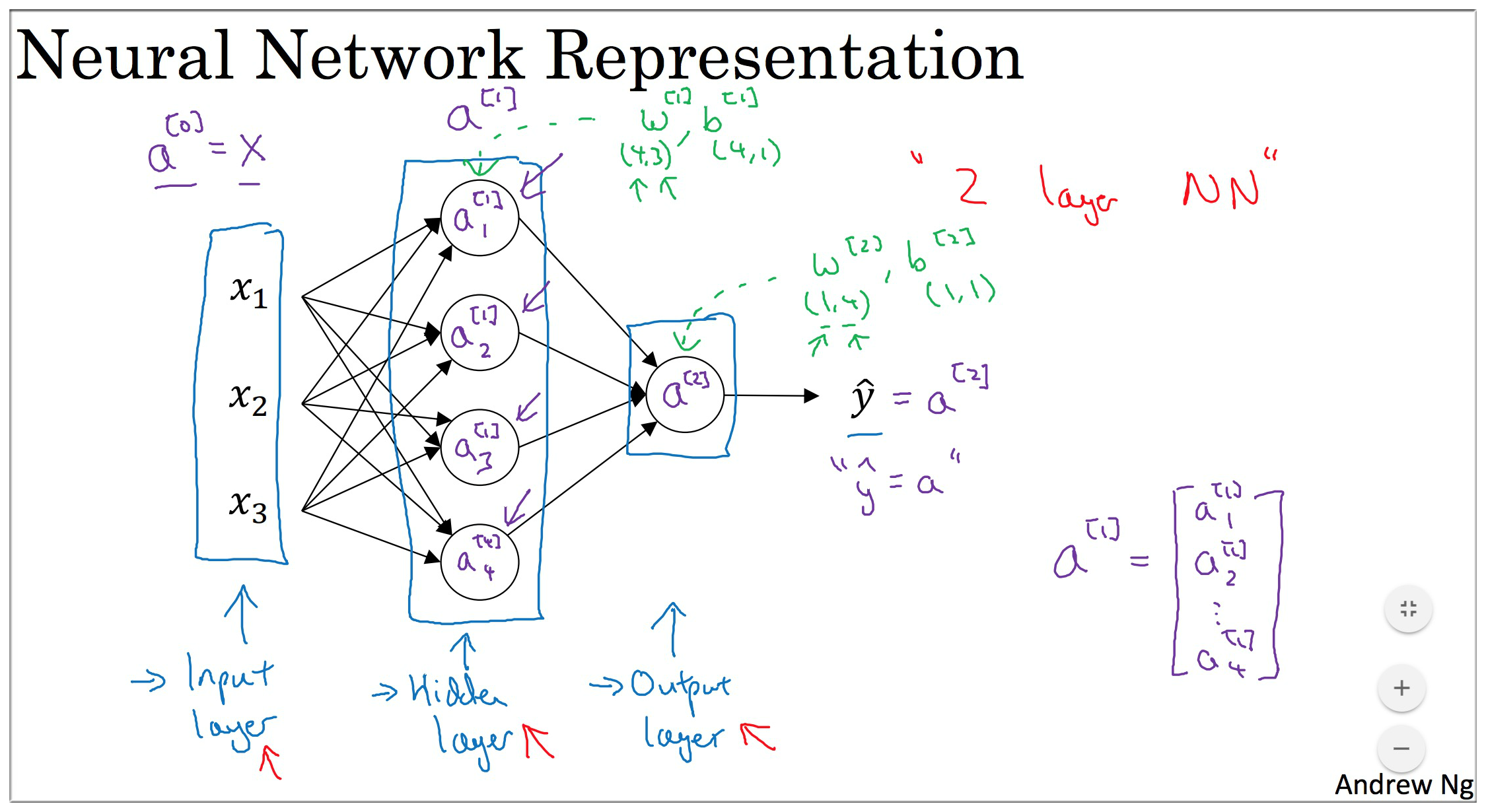
要注意的是各种参数, 中间变量 的维度问题. 关于神经网络的基本概念, 这里就不赘述了. 见下图回顾一下:
2. 神经网络中的前向传播
我们先以一个训练样本来看神经网络中的前向传播.
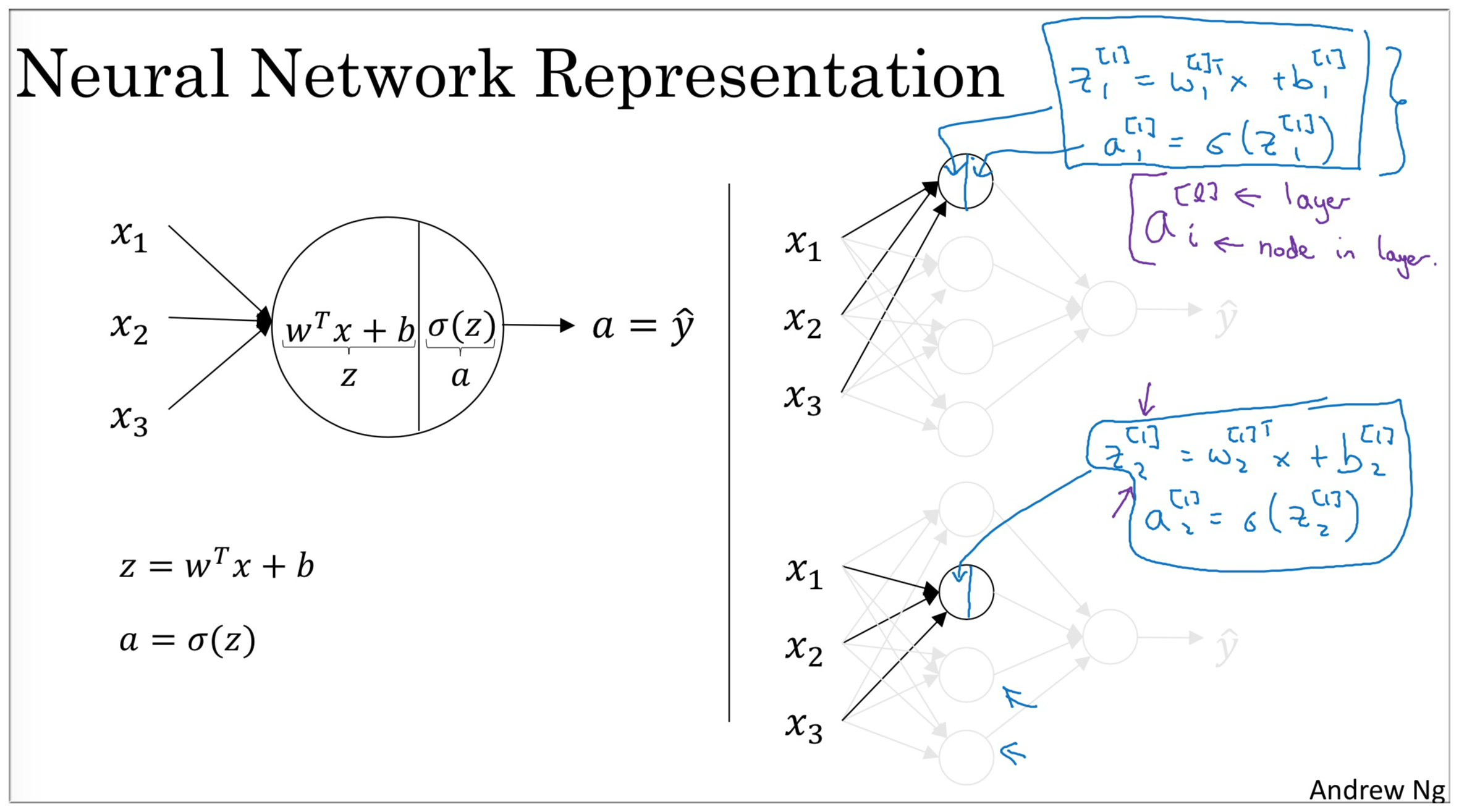
我们只看这个神经网络中的输入层和隐藏层的第一个激活单元(如下图右边所示). 其实这就是一个Logistic Regression.
- 神经网络中输入层和隐藏层 (不看输出层), 这就不就是四个LR放在一起吗?
- 在 LR 中 和 的计算我们已经掌握了, 那么在神经网络中 和 又是什么呢?
我们记隐藏层第一个 为 , 第二个 记为 以此类推.
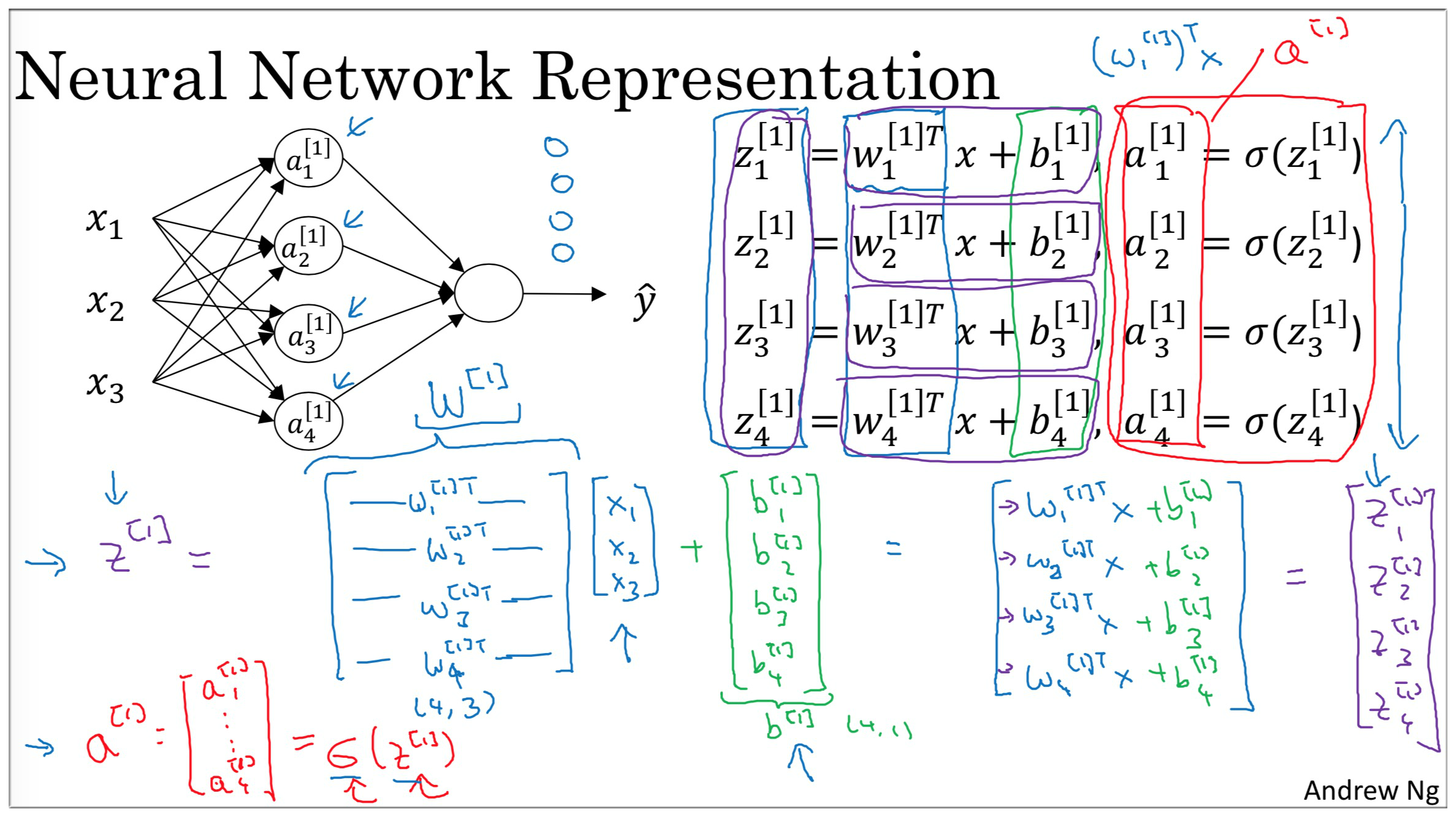
只要将这四个 纵向叠加在一起称为一个**列向量即可得到神经网络中这一层的 ** (同理).
那么这一层的 又是如何得到的? 别忘了, 对于参数 来说, 它本身就是一个列项量, 那么它是如何做纵向叠加的呢? 我们只需要将其转置变成一个横向量, 再纵向叠加即可.
得到隐藏层的 之后, 我们可以将其视为输入, 现只看神经网络的隐藏层和输出层, 我们发现这不就是个 嘛.
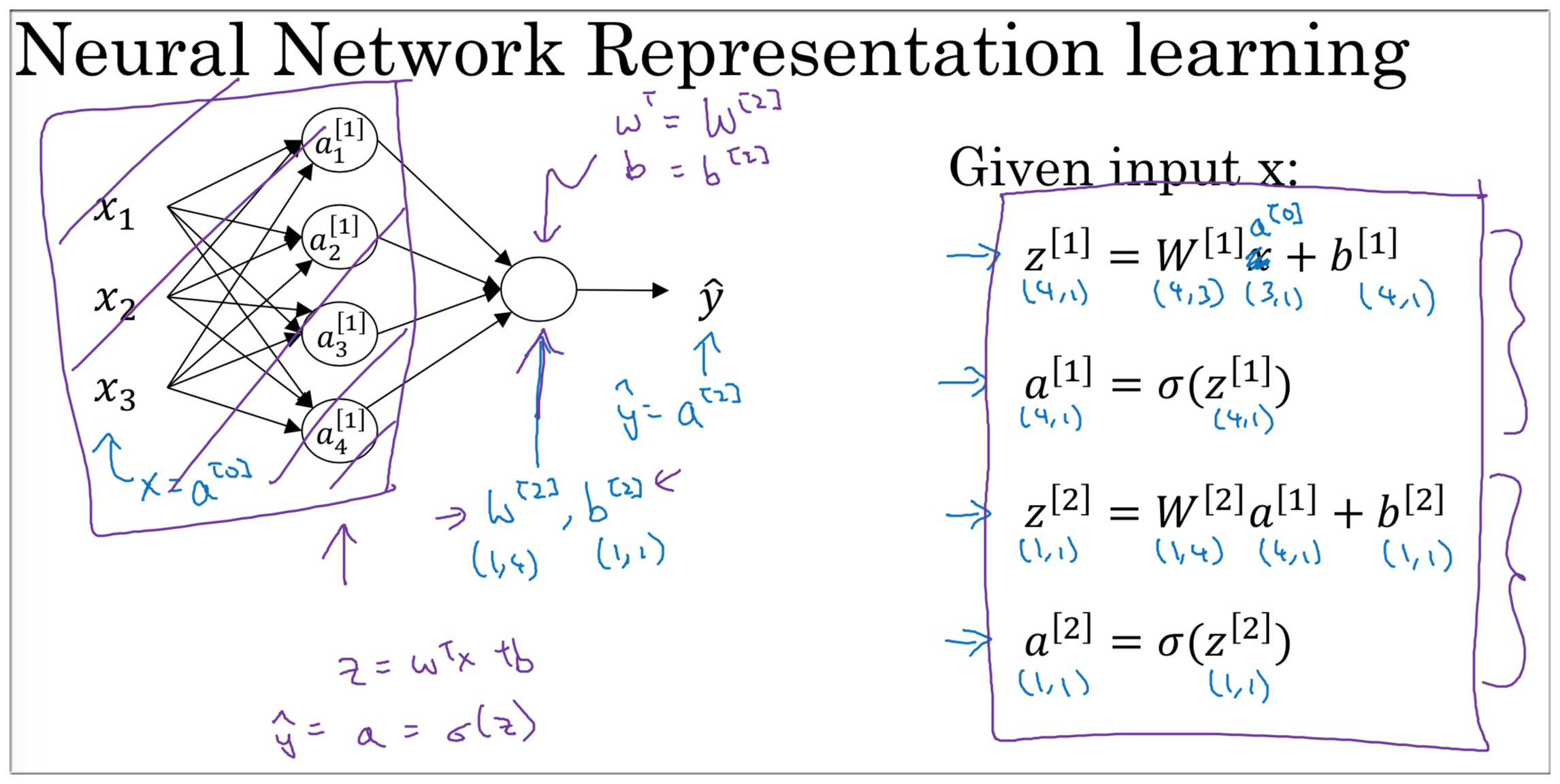
这里总结一下各种变量的维度 (注意: 这里是针对一个训练样本来说的, 代表的 层的节点个数):
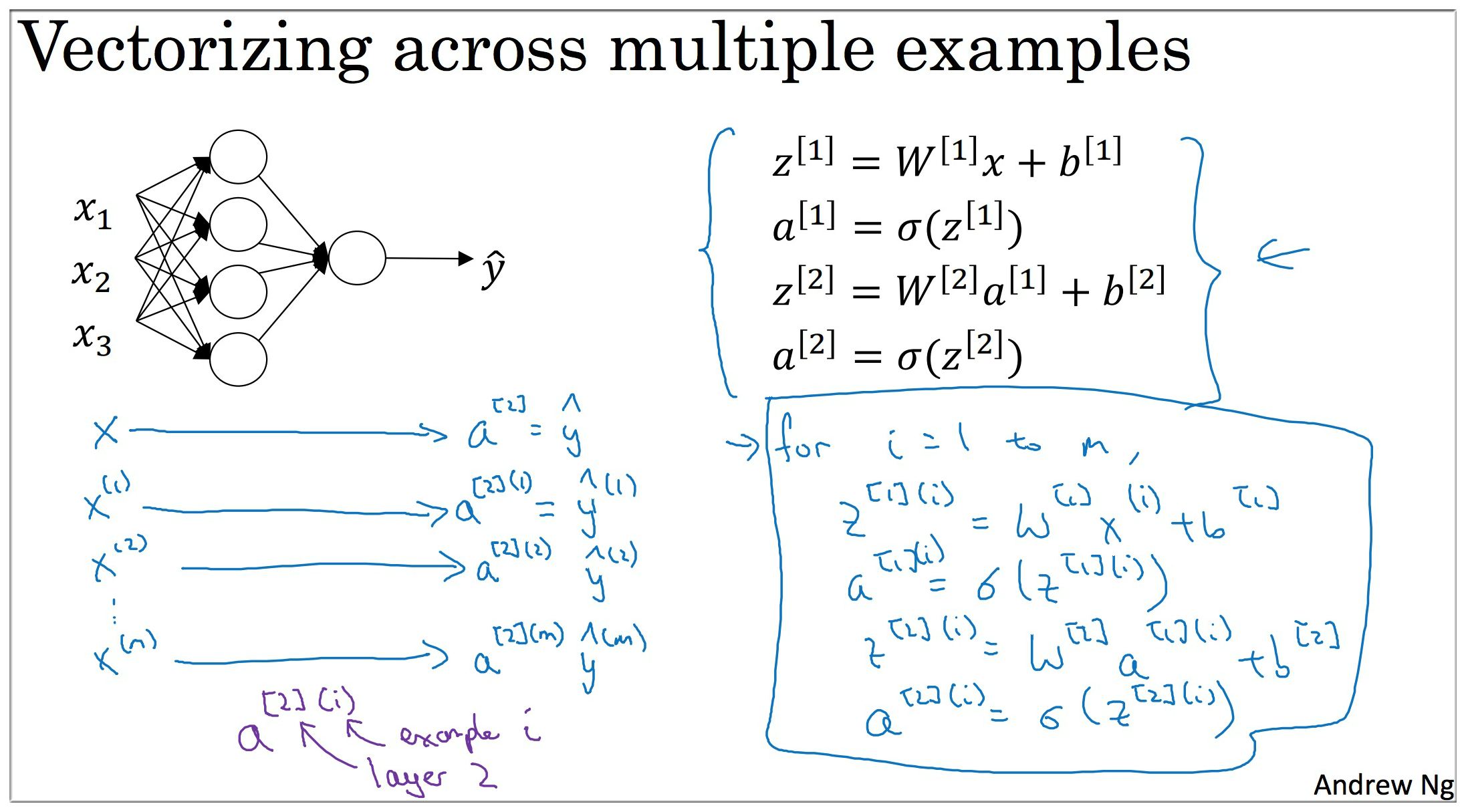
那么如果有 个训练样本这些变量的维度又是怎样的呢. 我们思考哪些变量的维度会随着样本数的变化而变化. 是参数显然它的维度是不会变的. 而输入每一个样本都会有一个 和 , 还记得 的形式吗? 同样地, 就是将每个样本算出来的 横向叠加(A同理). 具体计算过程如下图:


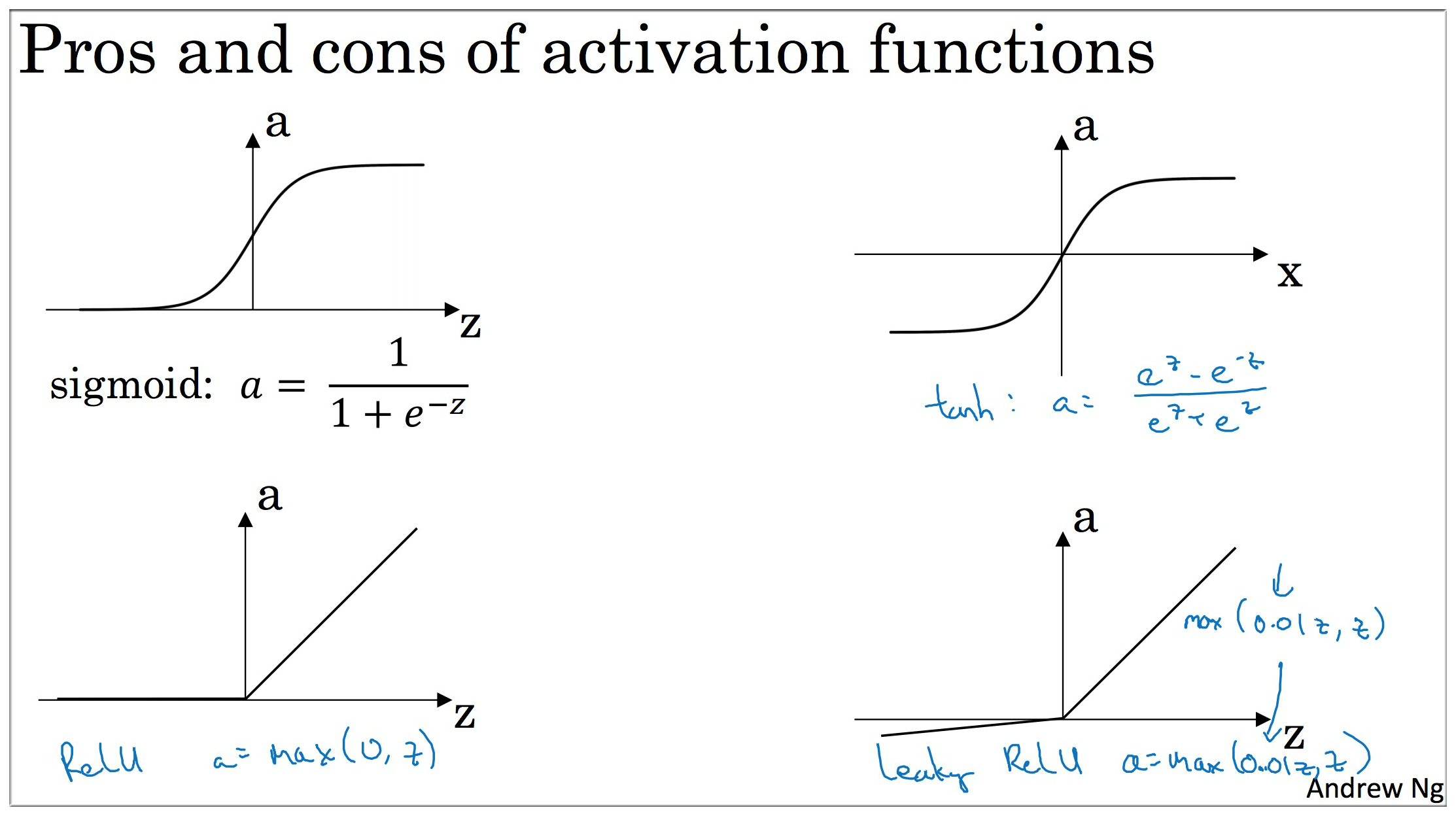
3. 神经网络中的激活函数
四种常用的激活函数: Sigmoid, Tanh, ReLU, Leaky ReLU.
其中 sigmoid 我们已经见过了, 它的输出可以看成一个概率值, 往往用在输出层. 对于中间层来说, 往往是ReLU的效果最好.
Tanh 数据平均值为 0,具有数据中心化的效果,几乎在任何场合都优于 Sigmoid
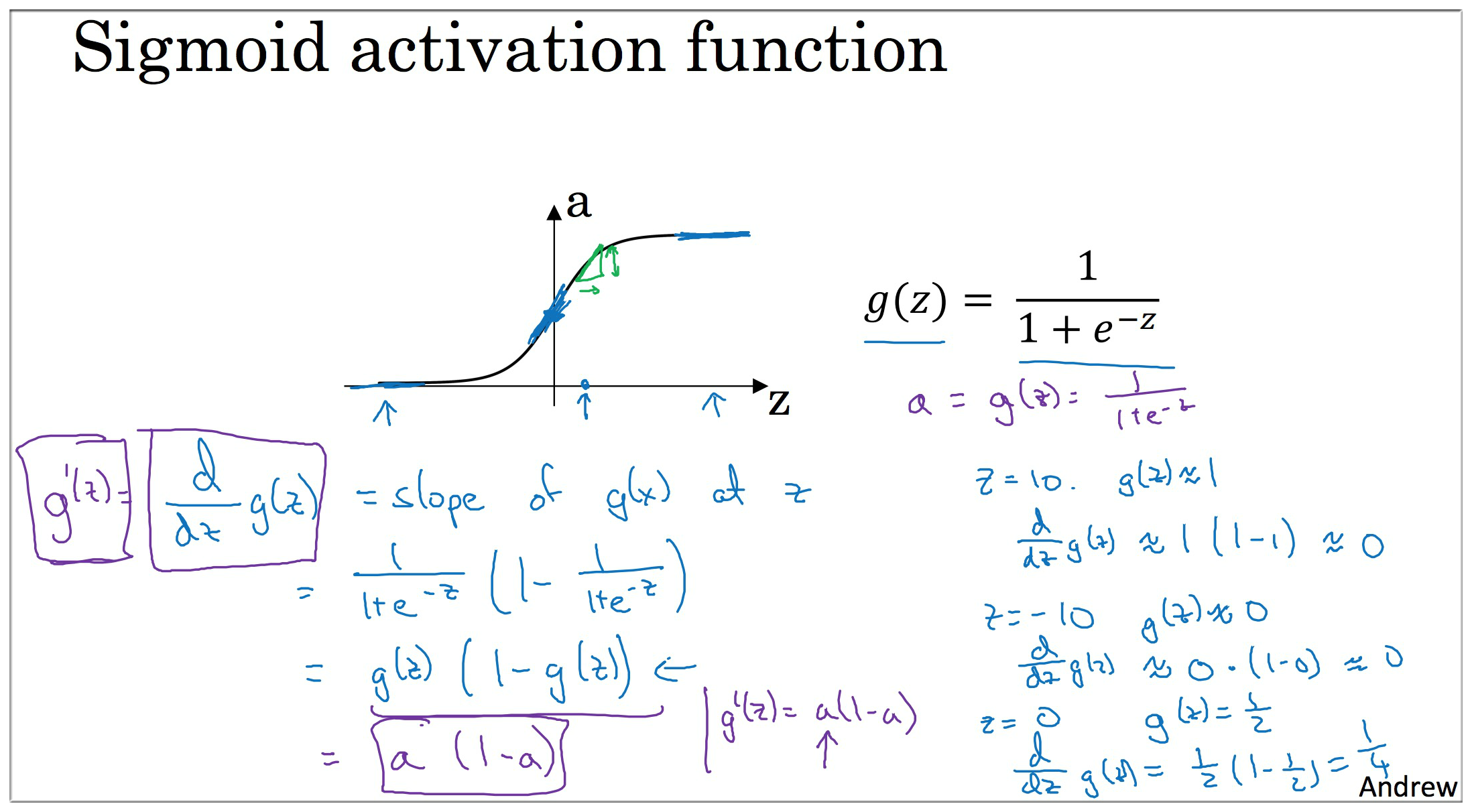
以上激活函数的导数请自行在草稿纸上推导.
derivative of
sigmoidactivation function
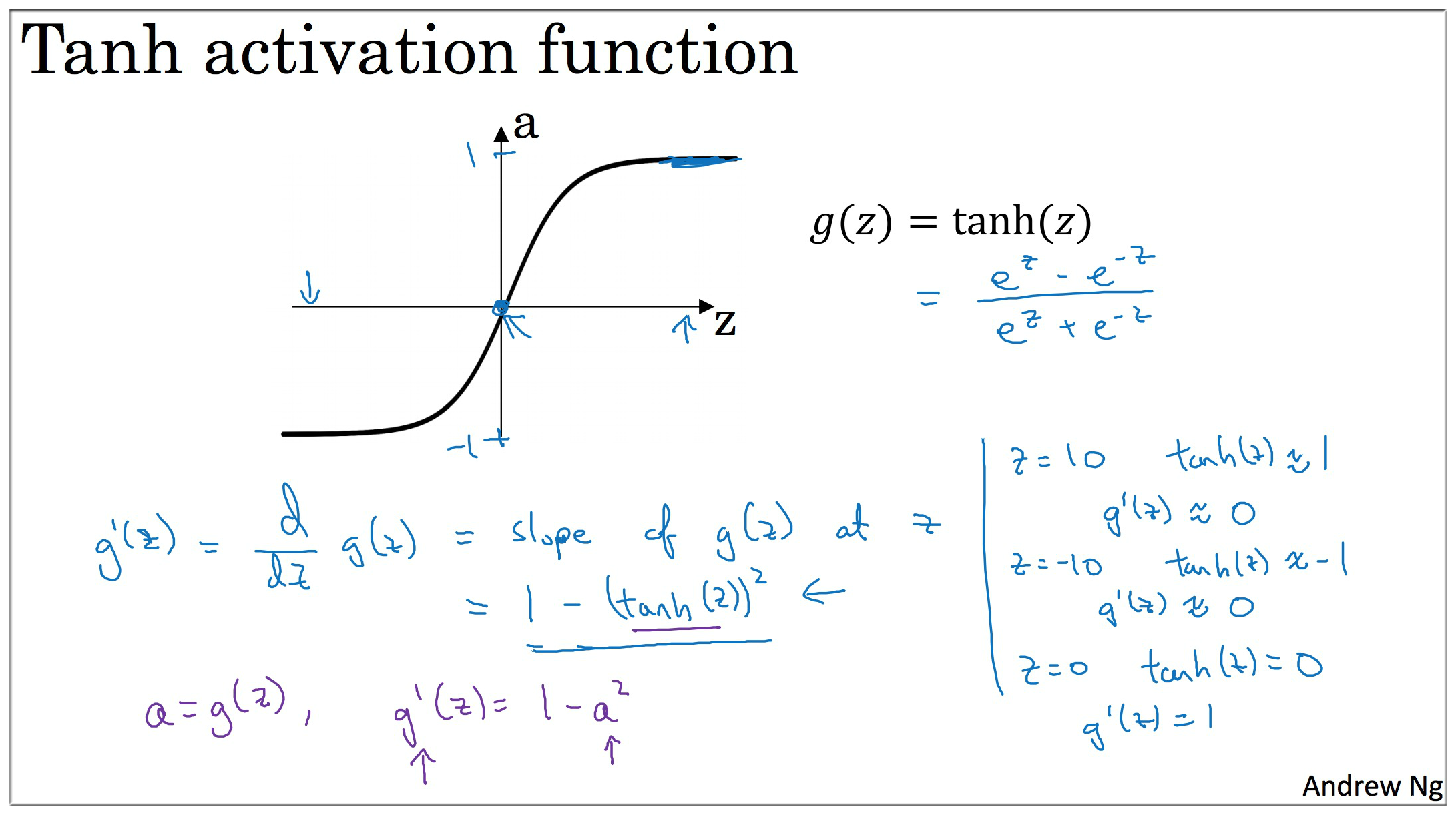
derivative of
tanhactivation function
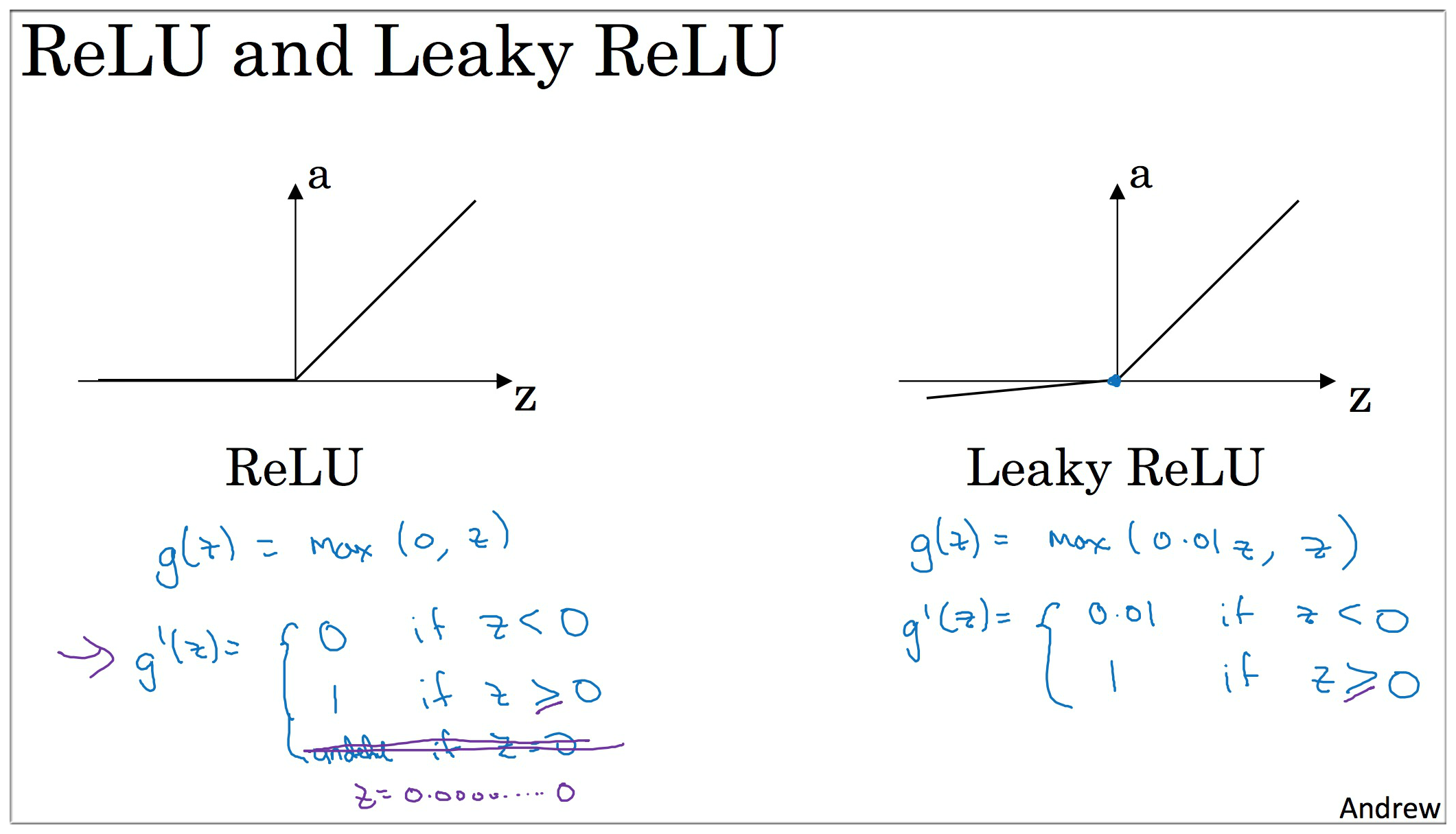
derivative of
ReLU and Leaky ReLUactivation function
为什么需要激活函数? 如果没有激活函数, 那么不论多少层的神经网络都只相当于一个LR. 证明如下:
it turns out that if you use a linear activation function or alternatively if you don’t have an activation function, then no matter how many layers your neural network has, always doing just computing a linear activation function, so you might as well not have any hidden layers.
so unless you throw a non-linearity in there, then you’re not computing more interesting functions.
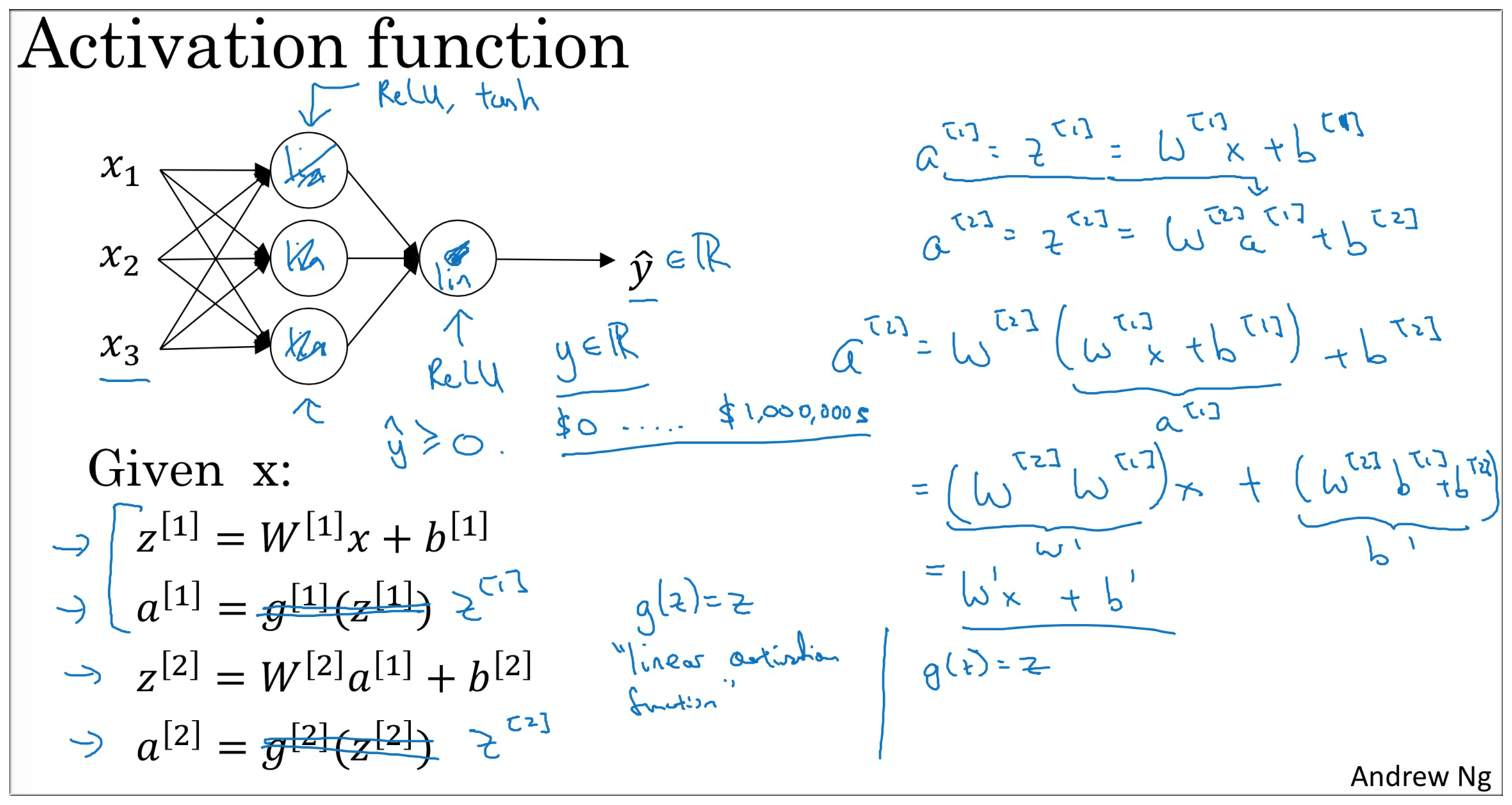
你可以在隐藏层用 tanh,输出层用 sigmoid,说明不同层的激活函数可以不一样。
现实情况是 : the tanh is pretty much stricly superior. never use sigmoid
ReLU (rectified linear unit 矫正线性单元)
tanh 和 sigmoid 都有一个缺点,就是 z 非常大或者非常小,函数的斜率(导数梯度)就会非常小, 梯度下降很慢.
the slope of the function you know ends up being close to zero, and so this can slow down gradient descent
ReLU (rectified linear unit) is well, z = 0 的时候,你可以给导数赋值为 0 or 1,虽然这个点是不可微的. 但实现没有影响.
虽然 z < 0, 的时候,斜率为0, 但在实践中,有足够多的隐藏单元 令 z > 0, 对大多数训练样本来说是很快的.
Notes:
so the one place you might use as linear activation function, others usually in the output layer.
4. 神经网络中的反向传播 back propagation
反向传播最主要的就是计算梯度, 在上一周的内容中, 我们已经知道了LR梯度的计算.
同样的方式, 我们使用计算图来计算神经网络中的各种梯度.
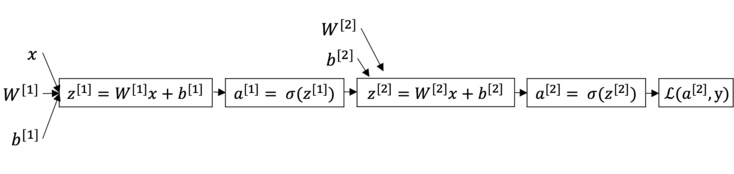
dz^{\[2\]} = \frac{dL}{dz}= \frac{dL}{da^{\[2\]}}\frac{da^{\[2\]}}{dz^{\[2\]}}=a^{\[2\]}-y
dW^{\[2\]}=\frac{dL}{dW^{\[2\]}}=\frac{dL}{dz^{\[2\]}}\frac{dz^{\[2\]}}{dW^{\[2\]}}=dz^{\[2\]}a^{\[1\]}
db^{\[2\]}=\frac{dL}{db^{\[2\]}}=\frac{dL}{dz^{\[2\]}}\frac{dz^{\[2\]}}{db^{\[2\]}}=dz^{\[2\]}
backward propagation :
dz^{\[1\]} = \frac{dL}{dz^{\[2\]}}\frac{dz^{\[2\]}}{da^{\[1\]}}\frac{da^{\[1\]}}{dz^{\[1\]}}=W^{\[2\]T}dz^{\[2\]}*g^{\[1\]’}(z^{\[1\]})
dW^{\[1\]}=\frac{dL}{dW^{\[1\]}}=\frac{dL}{dz^{\[1\]}}\frac{dz^{\[1\]}}{dW^{\[1\]}}=dz^{\[1\]}x^T
db^{\[1\]}=\frac{dL}{db^{\[1\]}}=\frac{dL}{dz^{\[1\]}}\frac{dz^{\[1\]}}{db^{\[1\]}}=dz^{\[1\]}
Notes: \frac{dL}{dz^{\[2\]}} = dz^{\[2\]} , \frac{dz^{\[2\]}}{da^{\[1\]}} = W^{\[2\]} , \frac{da^{\[1\]}}{dz^{\[1\]}}=g^{\[1\]’}(z^{\[1\]})
下图右边为在个训练样本上的向量化表达:

Notes:
- n^\[0\] = input features
- n^\[1\] = hidden units
- n^\[2\] = output units
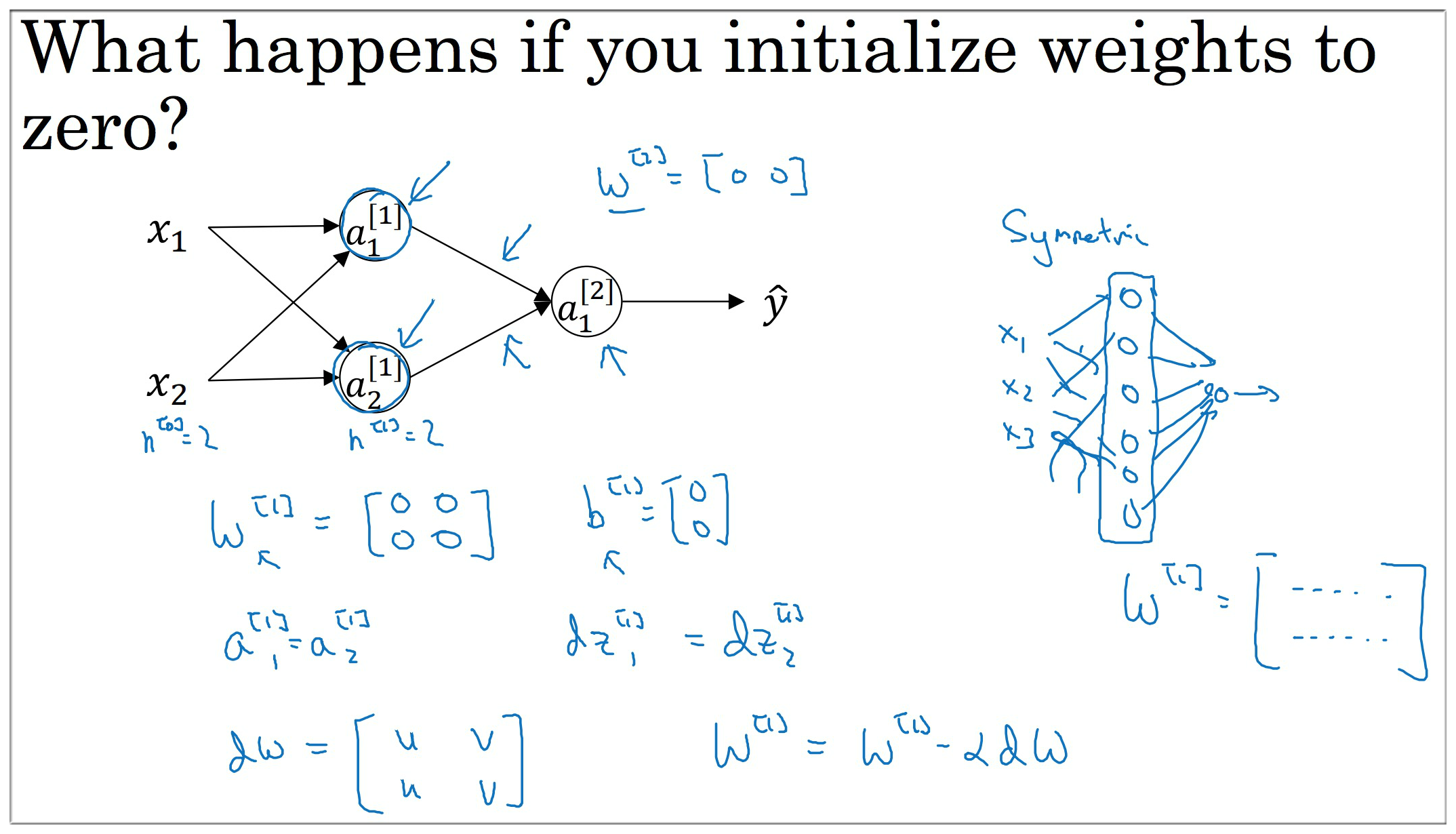
5. 神经网络中的参数初始化
在 LR 中我们的参数 初始化为 0, 如果在神经网络中也是用相同的初始化, 那么一个隐藏层的每个节点都是相同的, 不论迭代多少次. 这显然是不合理的, 所以我们应该 随机地初始化 从而解决这个 sysmmetry breaking problem. 破坏对称问题
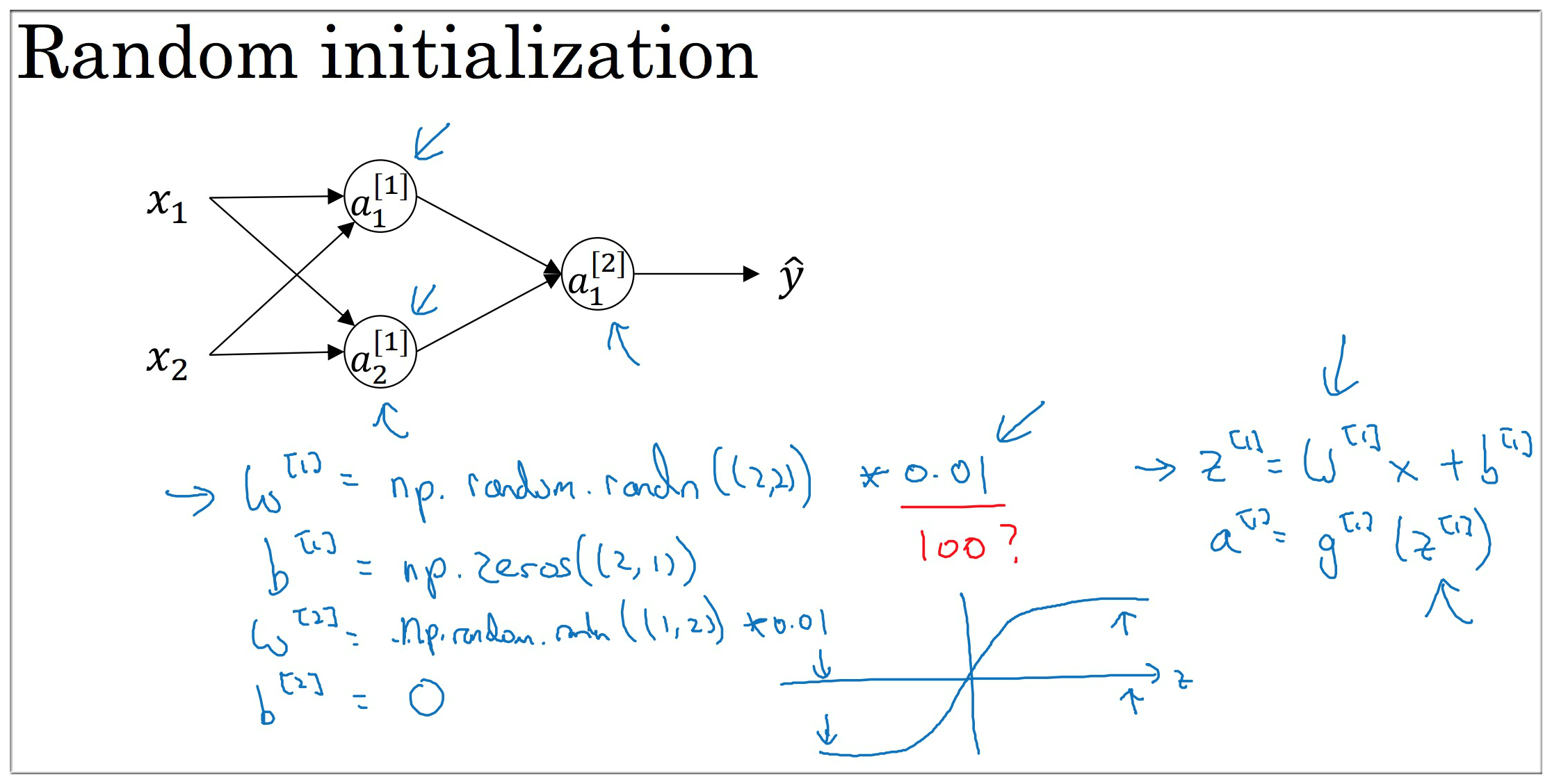
具体初始化代码可参见下图, 其中 乘以 0.01 是为了让参数 较小, 加速梯度下降
如激活函数为 tanh 时, 若参数较大则 也较大, 此时的梯度接近于 0, 更新缓慢. 如不是 tanh or sigmoid 则问题不大.
this is a relatively shallow neural network without too many hidden layers, so 0.01 maybe work ok.
finally it turns out that sometimes there can be better constants than 0.01.
并没有这个 sysmmetry breaking problem, 所以可以
6. 用Python搭建简单神经网络
使用Python+Numpy实现一个简单的神经网络. 以下为参考代码
1 | def sigmoid(z): |
1 | # Package imports |
7. 本周内容回顾
- 学习了神经网络的基本概念
- 掌握了神经网络中各种变量的维度
- 掌握了神经网络中的前向传播与反向传播
- 了解了神经网络中的激活函数
- 学习了神经网络中参数初始化的重要性
- 掌握了使用Python实现简单的神经网络
Reference
Neural Networks and Deep Learning (week4) - Deep Neural Networks
本周重点任务是使用Python要实现一个任意层的神经网络, 并在cat数据上测试. 1. 深度神经网络中的常用符号回顾 在上一周的内容中, 介绍了神经网络中的常用符号以及各种变量的维度. 不...
Neural Networks and Deep Learning (week2) - Neural Networks Basics
本周我们将要学习 Logistic Regression, 它是神经网络的基础. Logistic Regression 可以看成是一种只有输入层和输出层(没有隐藏层)的神经网络.
Checking if Disqus is accessible...