互联网金融风控中的数据科学 (part3) : Lending Club 的数据试验
用户全流程欺诈⻛险评分体系
反欺诈是一种机器学习过程
对于做互联网金融一般情况是 正负样本 是极度不平衡的(最高可以达到 100 : 1), 这样的情况对于 SVM 这种分类器是不合适的,所以在做金融的评分卡模型 或 欺诈模型 也好,这样对特征的处理 和 样本的非平衡处理是比较高的.
好坏用户的定义,一般是根据用户的贷后表现,来定义好坏用户的.
举个栗子🌰 :
用户借款 5W 元,可能是分期还款 12个月,这样每个月都会还一笔固定的额度.
信用风险 : 在挺长的时间可以按时还款.
欺诈风险 :
- 用户可能 第 1、2 期 是还的,之后是不还的.
(因为中介也越来越聪明,给他自己留出时间,躲避催收的手段,也躲避追踪等等)- 贷前审核 (触碰到拒贷规则)
- 造假行为 (信息资料造假)
- 调查员 调查出来是 中介 或者 有欺诈风向的,进入黑名单的.
- …
所以我们在定义模型负样本的话,我们可能定义为 m1+ 信用风险、m3+ (90天以上不还款的话),我们可以定义为欺诈风险
坏用户: 欺诈风险用户
好用户: 一天都不逾期还款
灰用户: m1+ 未还款,但是90天之内可以还款的 (不放在训练中,否则会给模型带来很多额外的信息,影响效果)灰用户不放在模型中,这样训练出的模型对好坏用户的区分程度也越高.
金融模型 和 CTR预估 相比是 有一个周期性质的
- 广告点击的话,用户点击,立马有一个样本出现
- 做长期现金贷,选择样本是选择半年之前的用户,作为样本
正负样本
真实场景正负样本比例 (10~30) :1 (成熟平台的风险是越来越小的,所以我们拿到的 正负样本比例是逐步增加的).
数据的不平衡处理 : 降采样、过采样、SMOTE
- 降采样 : 正负样本成 3:1, 5:1 来做一个模型, 坏样本是全部取的, (一般这种情况 做评分卡的时候是需要做的)
- 过采样 : 实际用的不多,如果负样本实在是过少 都 <100 个, 那么可以考虑 减低我们的观察周期, 或者 欺诈定义的并不是一个很严格 来放进来多一些的 负样本过来来做训练,或者在拒贷里面找一些人过来.
- SMOTE : 在分布上模拟一些数据,模拟完的数据可做训练,比较经典拿真实的数据做训练是更贴近真实的情况.
做模型 如 GBRT、RF 等,他们对不平衡的数据是有容忍的,这种直接用真实数据进行训练,也能得到很好的效果.
模型选型
对于做评分卡的模型 或者 LR 的话,样本的平衡要在 10:1 范围内, LR 对变量相关性的筛选 和 数据平衡 有要求
做模型,至少要用 RF 来做模型, 或者 GBDT、GBRT,这种 Boosting 的模型,对于样本的不平衡容忍度更高一些,他们对于学习 更小而细微 的特征和变量 可以学习的更深一些.
Lending Club
Lending Club 创立于 2016年, 主要做一个提供 P2P 贷款的平台中介服务,2016年底在 纽交所上市,后来爆出来很多丑闻,创始人离职,股价下跌. 但是不管怎么样,它的数据在我们做反欺诈等是非常有重要的.
Lending Club 2016 的借贷数据,Q3,Q4 可以一起做一下,半年的数据做训练是更好的.
1. Data
Lending Club 2016年Q3数据:https://www.lendingclub.com/info/download-data.action
参考:http://kldavenport.com/lending-club-data-analysis-revisted-with-python/
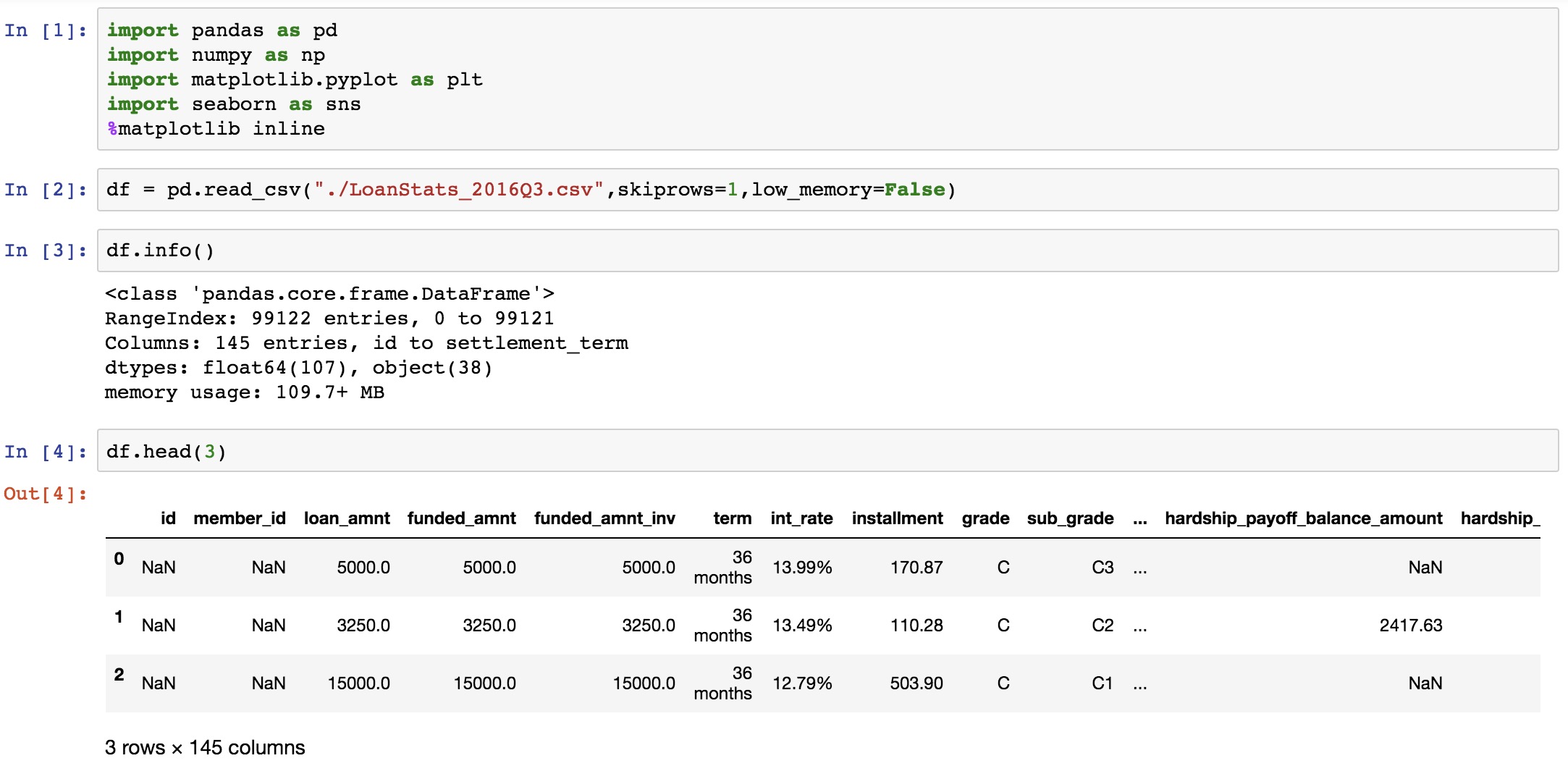
看下数据,其实我也不能完全了解这些所有字段的含义
- int_rate 利率
- term 待多少期
- grade 等级 C、B、D,7个等级吧
- sub_grade 会分为更细的等级.
- 后面这些是从 FICO 获取的数据吧…
我们的目的是判断,来了一个用户,之后输入该用户的这些特征,我们判断他是不是一个欺诈用户
如果用户填写假资料
用户贷款之后的表现,如果填的真假我们不了解,填写的是假资料,但是之后还款表现好那么它还是一个好用户.
数据上
我只取了2016年Q3数据,9W+ 的数据,列数 122 列。数据有 99124行, 去掉表头,有 99123 行
2. Keep what we need
我们初步做特征筛选…, 我们在看的时候,可以分片分片的看这 122 个列…
2.1 特征分析 part1
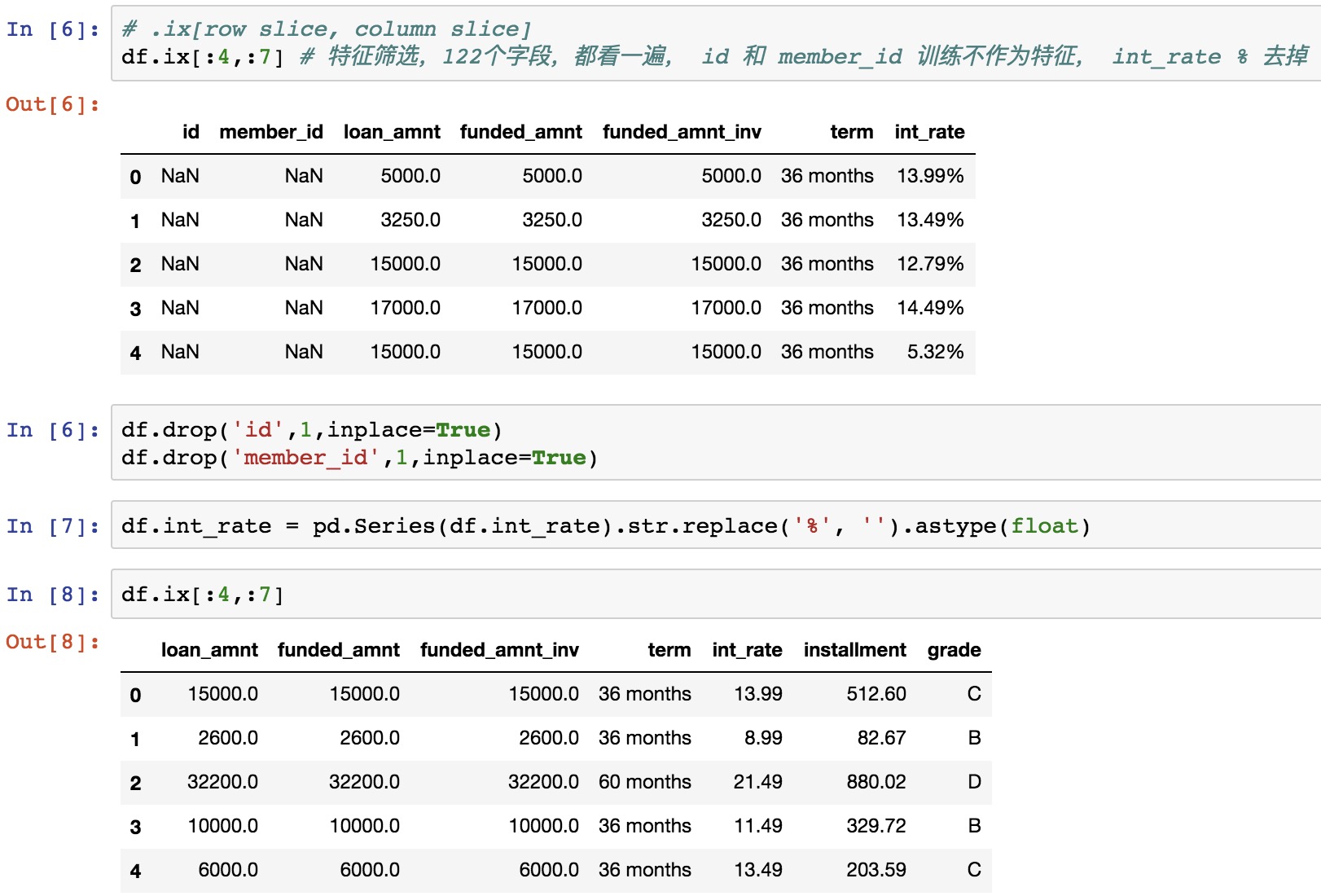
id 和 member_id 不作为特征,可以直接去掉, int_rate 带 % 的可以直接去掉 %, 变为 float 的
Loan Amount Requested Verus the Funded Amount
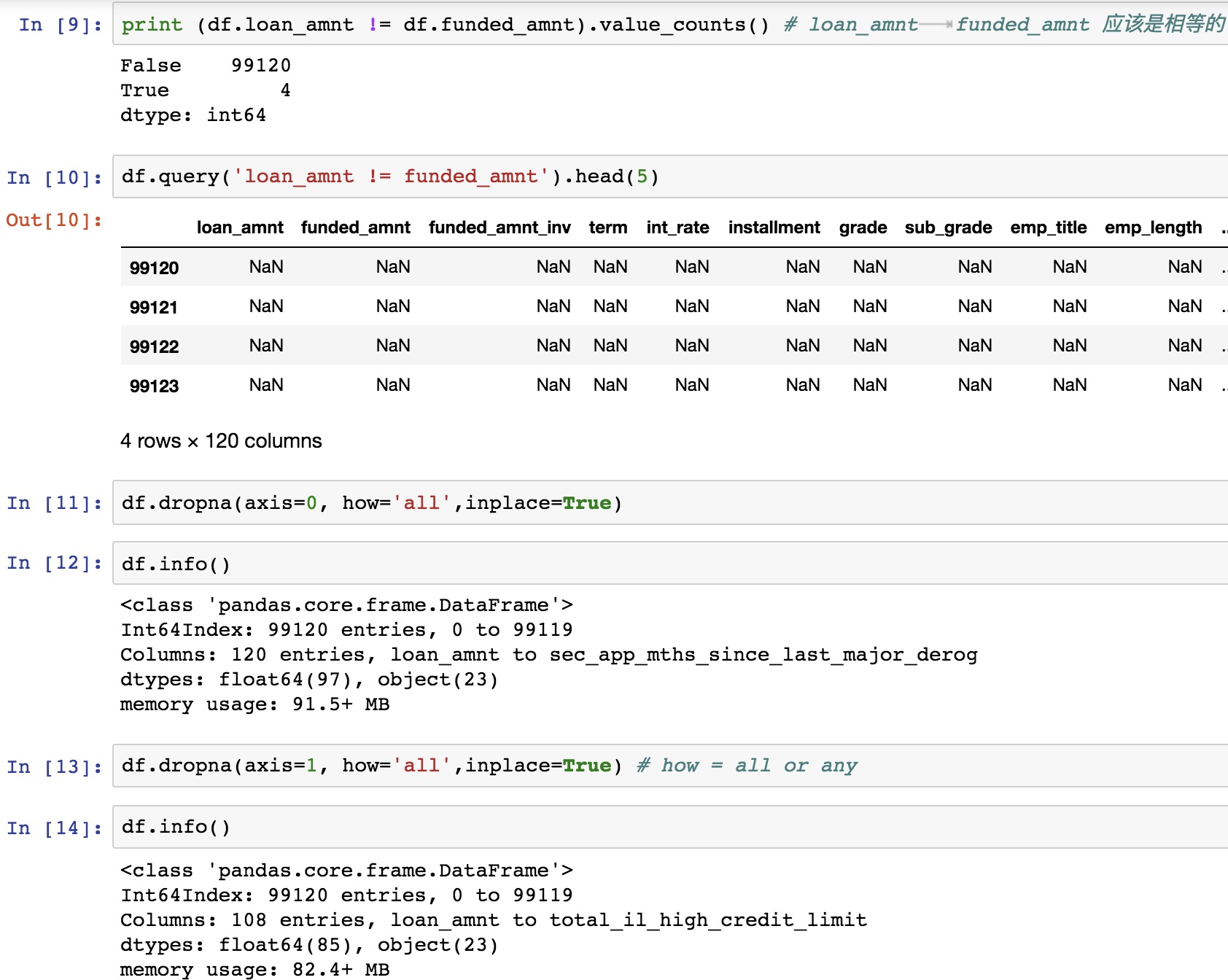
2.2 特征分析 part2
1 | df.ix[:5,8:15] |
1 | df.drop(['emp_title'],1, inplace=True) |
employment title
3. 总结
删不删除变量,需要看模型,LR 需要删除,GBRT 不用删除也可以.
LR 做评分卡模型,变量 一定是强变量,20个左右,不会几百个,有个变量可以训练处系数
出来 0 ~ 1 概率,拉一下橡皮筋, 分数映射,拉到 300 ~ 900 分,可以做一个评分卡,600分 可能是好用户:坏用户,可能是 50:1
评分卡的阶梯可能是增加。
模型不同 0 ~ 1 的概率可能是不同的,那么我增加50分,风险水平会降低一半
550 25:1
评分卡分的映射和模型是没有关系的,是样本里人群的好坏是有关系的,所以模型的参数做映射,是不需要重新训练的。
lending club 要求 FICO 是个特定的评分方法,是一个固定的评分方法。
比如 芝麻信用都是用自己的模型,自己算出来的
如果人群变了
模型的稳定性非常重要,当前要评估的人群已经和去年下半年的用户已经不一样的,所以训练的时候要尽可能提升模型的稳定性,如果训练时模型稳定性非常差,那么一上线就崩溃了。
如何提高模型稳定性,2种方法
-
特征筛选的时候,我会去把特征从样本的时间开始,2016.06 开始每个月我一直在看它的均值和方差的变化是否在容忍的范围内,比如我去年这个月这个特征是30,当前 2017.06 这个特征变为了 100,那么这个特征变化太大,是不能用的,超过50%, 太不稳定了,其实这个变量,或者做评分卡,反欺诈等是不合适的,直接扔掉。
-
尽量做模型融合,单模型的模型稳定性是不好的,随着月份的变化,你的预测是有变化的,波动的范围是有点低,ensemble 集成学习,
三种方法 (bagging、boosting,Stacking)
2.1 Bagging 比如 RF,每个模型取一样的权重,进行评估
2.2 Boosting 根据模型训练出不同权重,给予不同的权重
2.3 Stacking 我在用一个分类器,去处理我要集成的这3,4种模型,训练出一个参数
这三种方法,都能提高模型的稳定性
让你在线上运行 3~6 个月,信贷产品比较长的话,2个月更新一次比较好,贷款周期短的话,周更新都可以
有做 KS 比较高的话,会送大家小礼品,
我们线上有用 spark streaming 也有处理实时特征,但是目前体量,一般单机和离线处理就够了。
9W 个用户,100多个变量,那根本不需要用分布式来计算了。
半年的样本数据,把数据取出来之后,你要定义你的好坏样本,会把一些灰色地段的用户给他摘除掉,只留下最好或者最坏的用户,这些用户提特征之后,在做训练,样本内的验证和跨时间的验证 ,就是说我的时间段是完全不一样的,那么能够验证模型的稳定性,那么最好就要拿 2017年,1和2月的数据,在做一个跨时间的验证,跨时间的验证才是你真正上线之后的效果,因为你在时间窗口内训练或者test的话,它的 ks 可能 30 多,如果跨时间验证的话,你的人群可能会偏移,那么ks可能会下降,ks就变为20,如果差别控制在 15%,差别大稳定性就很不好,是不能上线的。
模型的话,你现在开始做模型,你一定取的是 去年 下半年的是数据,做验证的话是拿去年1月份的数据,一个月的数据还有5,6,7个还款表现,基本上等你做完模型,你做跨时间验证的话,刚刚好,你花2个礼拜做一个模型,上线的时候,你就不需要重新训练了。除非你到9月份上线,那么时间久了,就需要重新训练,一般是不需要重新训练的。
欺诈模型的稳定性评价指标: 1. 对比训练集 与 跨时间验证集 的 KS 偏差,一般偏差大不大的话,觉得这个模型是可以在时间维度上hold住的,那么可以模型上线。另外指标金融上比较常用的指标是 psi,这个是验证不同人群的偏移程度,以后可以自己查查资料。
Checking if Disqus is accessible...