互联网金融风控中的数据科学 (part2) : 模型策略
反欺诈也是一种机器学习过程, 反欺诈建模中的数据科学
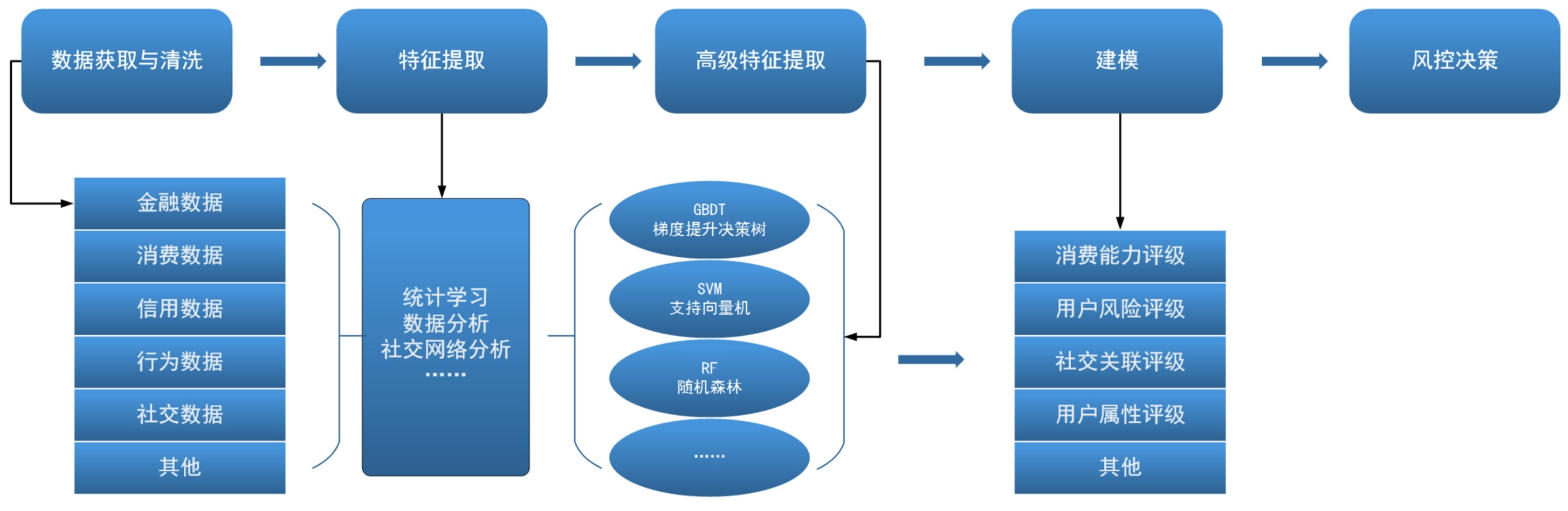
反欺诈也是一种机器学习过程
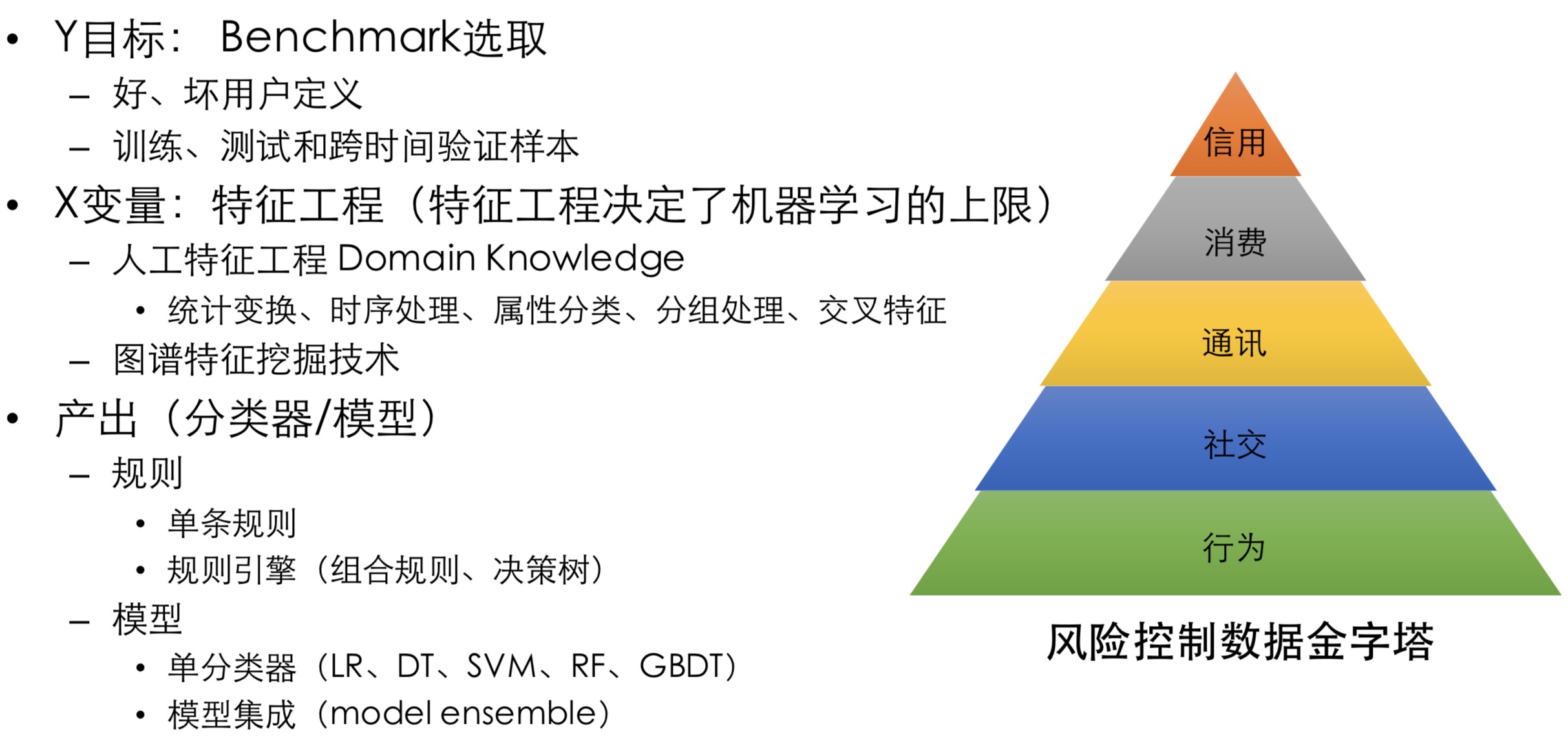
对于做互联网金融一般情况是 正负样本 是极度不平衡的(最高可以达到 100 : 1), 这样的情况对于 SVM 这种分类器是不合适的,所以在做金融的评分卡模型 或 欺诈模型 也好,这样对特征的处理 和 样本的非平衡处理是比较高的.
好坏用户的定义,一般是根据用户的贷后表现,来定义好坏用户的.
举个栗子🌰 :
用户借款 5W 元,可能是分期还款 12个月,这样每个月都会还一笔固定的额度.
信用风险 : 在挺长的时间可以按时还款.
欺诈风险 :
- 用户可能 第 1、2 期 是还的,之后是不还的.
(因为中介也越来越聪明,给他自己留出时间,躲避催收的手段,也躲避追踪等等)- 贷前审核 (触碰到拒贷规则)
- 造假行为 (信息资料造假)
- 调查员 调查出来是 中介 或者 有欺诈风向的,进入黑名单的.
- …
所以我们在定义模型负样本的话,我们可能定义为 m1+ 信用风险、m3+ (90天以上不还款的话),我们可以定义为欺诈风险
坏用户: 欺诈风险用户
好用户: 一天都不逾期还款
灰用户: m1+ 未还款,但是90天之内可以还款的 (不放在训练中,否则会给模型带来很多额外的信息,影响效果)
金融模型 和 CTR 预估的相比是 有一个周期性质的
- 广告点击的话,用户点击,立马有一个样本出现
- 做长期现金贷,选择样本是选择半年之前的用户,作为样本
模型策略

1. Linear Regression

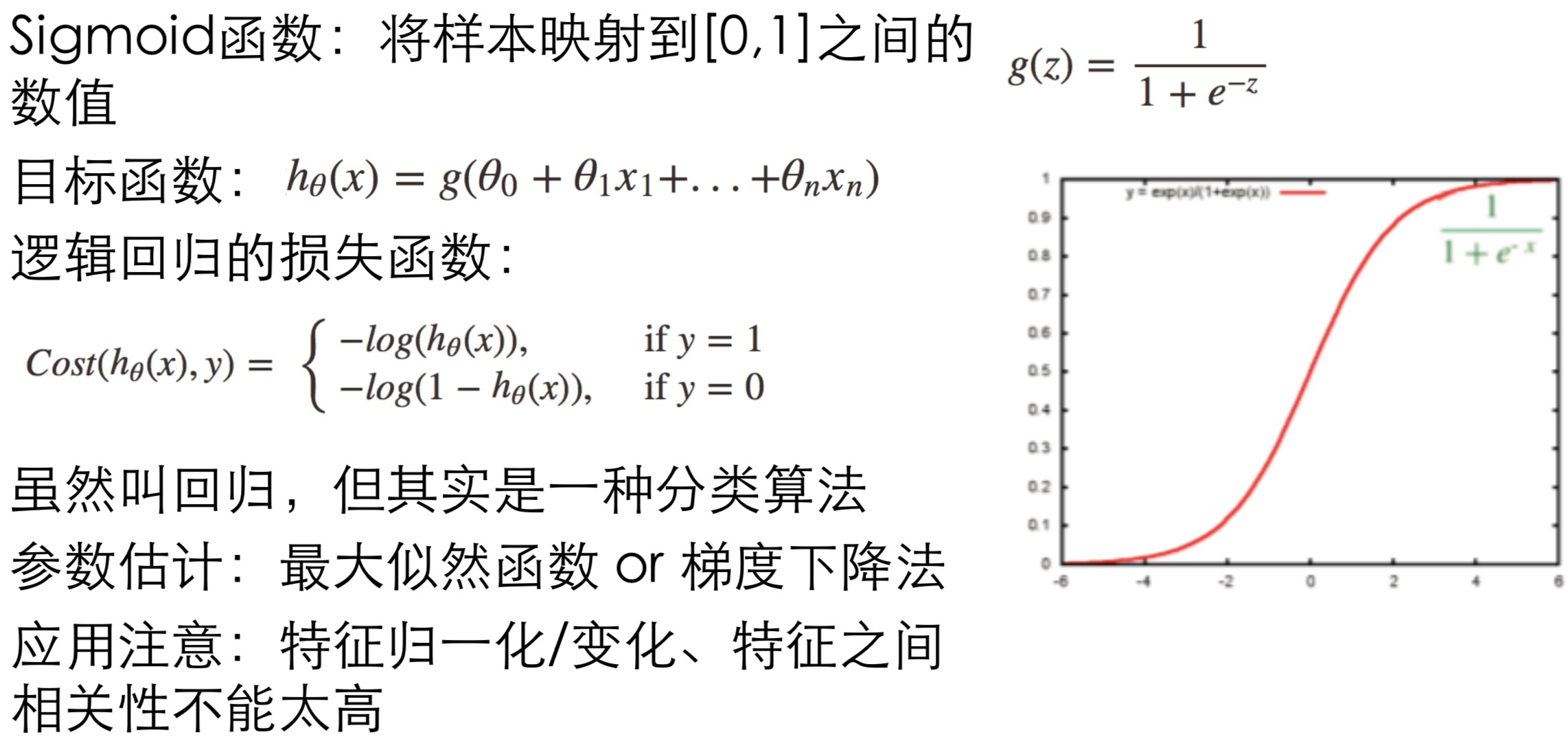
2 Logistic Regression
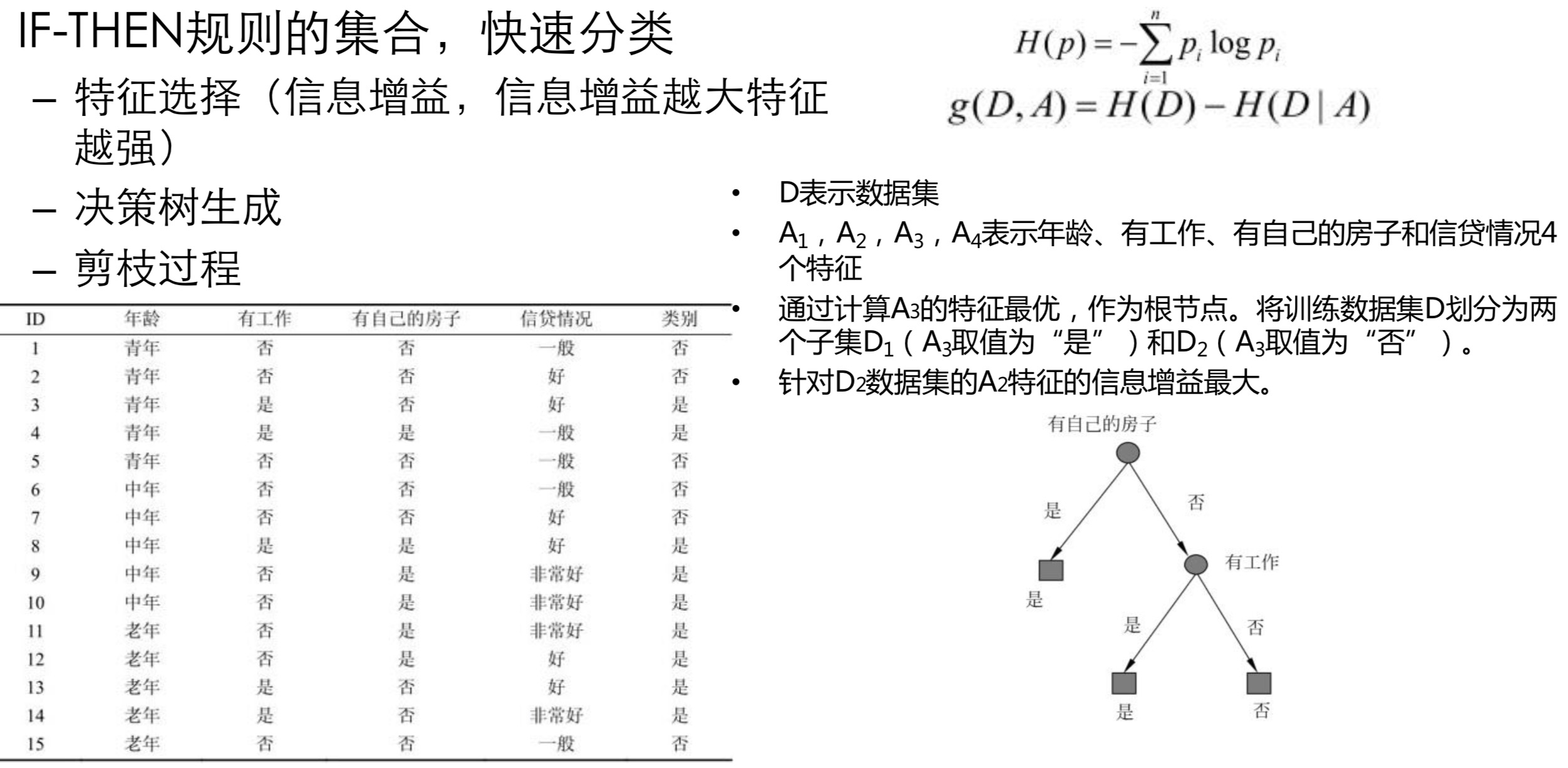
3. Decision Tree
4. Random Forest

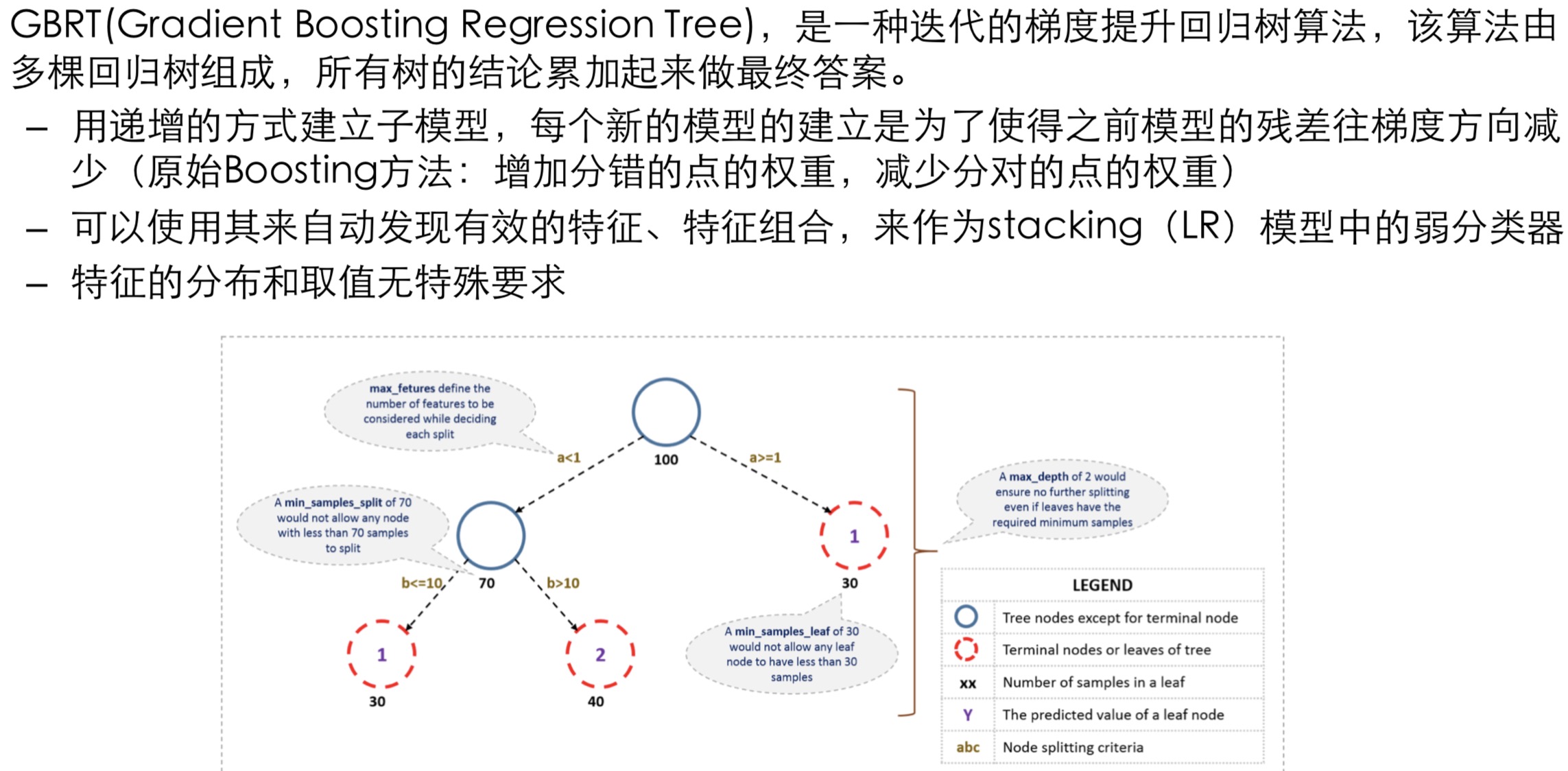
5. Gradient Boosting RT

结果评估-混淆矩阵
- Precision: 评估认定坏用户的精确度
- Recall: 评估坏用户的召回率
- F-Measure: 组合判断

Checking if Disqus is accessible...