Ensemble Learning (part1)
Ensemble learning(集成学习):是目前机器学习的一大热门方向,所谓集成学习简单理解就是指采用多个分类器对数据集进行预测,从而提高整体分类器的泛化能力。
- Bootstraping
- Bagging、Boosting、Stacking
Bootstraping
Bootstraping的名称来自成语 “pull up by your own bootstraps”,意思是依靠你自己的资源,它是一种有放回的抽样方法.
注:Bootstrap本义是指高靴子口后面的悬挂物、小环、带子,是穿靴子时用手向上拉的工具。“pull up by your own bootstraps”即“通过拉靴子让自己上 升”,意思是“不可能发生的事情”。后来意思发 生了转变,隐喻“不需要外界帮助,仅依靠自身力 量让自己变得更好”
bootstraping 的思想和步骤如下:
举个🌰:我要统计鱼塘里面的鱼的条数,怎么统计呢?假设鱼塘总共有鱼1000条,我是开了上帝视角的,但是你是不知道里面有多少。
步骤:
- 承包鱼塘,不让别人捞鱼(规定总体分布不变)。
- 自己捞鱼,捞100条,都打上标签(构造样本)
- 把鱼放回鱼塘,休息一晚(使之混入整个鱼群,确保之后抽样随机)
- 开始捞鱼,每次捞100条,数一下,自己昨天标记的鱼有多少条,占比多少(一次重采样取分布)。
- 重复3,4步骤n次。建立分布。
假设一下,第一次重新捕鱼100条,发现里面有标记的鱼12条,记下为12%,放回去,再捕鱼100条,发现标记的为9条,记下9%,重复重复好多次之后,假设取置信区间95%,你会发现,每次捕鱼平均在10条左右有标记,所以,我们可以大致推测出鱼塘有1000条左右。其实是一个很简单的类似于一个比例问题。这也是因为提出者Efron给统计学顶级期刊投稿的时候被拒绝的理由–“太简单”。这也就解释了,为什么在小样本的时候,bootstrap效果较好,你这样想,如果我想统计大海里有多少鱼,你标记100000条也没用啊,因为实际数量太过庞大,你取的样本相比于太过渺小,最实际的就是,你下次再捕100000的时候,发现一条都没有标记,,,这TM就尴尬了。。
Bootstrap 经典语录
Bootstrap是现代统计学较为流行的一种统计方法,在小样本时效果很好。通过方差的估计可以构造置信区间等,其运用范围得到进一步延伸。
就是一个在自身样本重采样的方法来估计真实分布的问题
当我们不知道样本分布的时候,bootstrap方法最有用。
Ensemble learning
了解 boosting 和 bagging 之前,先了解一下什么是 ensemble,一句话,三个臭皮匠顶个诸葛亮,一箭易折十箭难折,千里之堤溃于蚁穴 …😄😄😄 ,在分类的表现上就是,多个弱分类器组合变成强分类器。
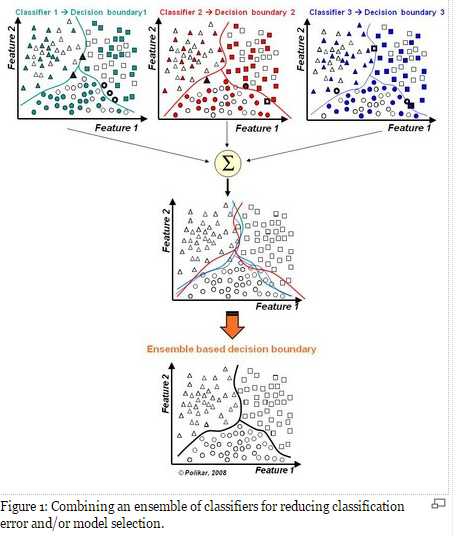
假设各弱分类器间具有一定差异性(如不同的算法,或相同算法不同参数配置),这会导致生成的分类决策边界不同,也就是说它们在决策时会犯不同的错误。将它们结合后能得到更合理的边界,减少整体错误,实现更好的分类效果。
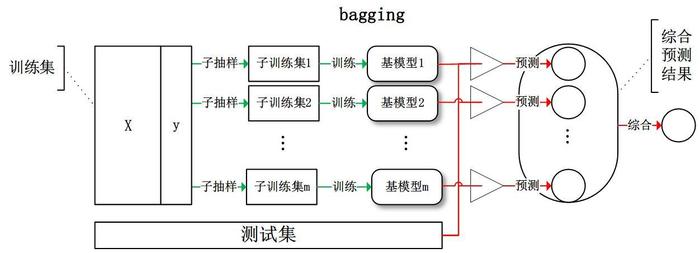
Bagging (bootstrap aggregation)
bagging:从训练集从进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合产生最终的预测结果,至于为什么叫bootstrap aggregation,因为它抽取训练样本的时候采用的就是bootstrap的方法!
Bagging 策略过程 😄 :
- 从样本集中重采样(有重复的)选出n个样本
- 在所有属性上,对这n个样本建立分类器 (ID3、C4.5、CART、SVM、Logistic回归等)
- 重复以上两步m次,即获得了m个分类器
- 将数据放在这m个分类器上,最后根据这m个分类器的投票结果,决定数据属于哪一类.
- 投票机制 (多数服从少数, 民主政治) 看到底分到哪一类(分类问题)
Bagging 代表算法 - Random Forest
随机森林,它不仅可以用来做分类,也可用来做回归即预测,一般随机森林机由多个决策树构成,相比于单个决策树算法,它分类、预测效果更好,不容易出现过度拟合的情况。
1.训练样本选择方面的Random:
Bootstrap方法随机选择子样本
2.特征选择方面的Random:
属性集中随机选择k个属性,每个树节点分裂时,从这随机的k个属性,选择最优的(如何选择最优又有各种最大增益的方法,不在本文讨论范围内)。
决策树
决策树对训练样本有良好的分类能力,只要我们的层数不加限制,我们甚至可以把它分的没有任何误差,这样可能导致你的泛化能力很弱。 缓解的方法就是 1. 剪枝 2. 随机森林
剪枝 我还没用过,所以我们看常用的 随机森林 Romdom Forest
决策树 : 特征选择
- ID3 仅具有教学价值
- gini 系数,作为指标比较多,在实践当中
Random Forest 构造流程
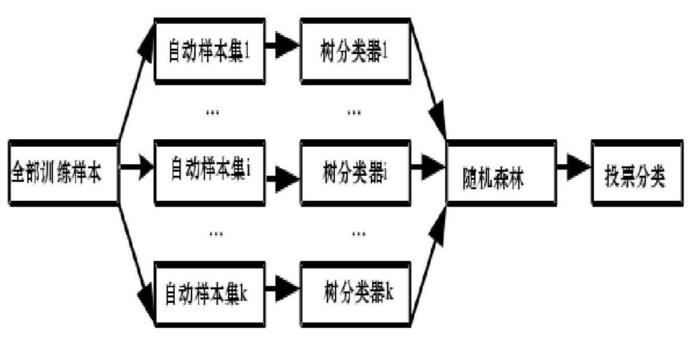
- 用 Random(训练样本用Bootstrap方法,选择分离叶子节点用上面的2)的方式构造一棵决策树(CART)
- 用1的方法构造很多决策树, 不剪枝, 许多决策树构成一片森林,决策树之间没有联系
- 测试数据进入每一棵决策树,每棵树做出自己的判断,然后投票选出最终所属类别(默认每棵树权重一致)
Random Forest 优点
- 不容易出现过拟合,因为选择训练样本的时候就不是全部样本。
- 既可处理属性为离散值的量,比如ID3算法来构造树,也可以处理属性为连续值的量,比如C4.5算法来构造树
- 对于高维数据集的处理能力令人兴奋,它可以处理成千上万的输入变量,并确定最重要的变量,因此被认为是一个不错的降维方法。该模型能够输出变量的重要性程度,这是一个非常便利的功能。
- 分类不平衡的情况时,随机森林能够提供平衡数据集误差的有效方法
Random Forest 缺点
- 随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合。
- 对于许多统计建模者来说,随机森林给人的感觉像是一个黑盒子——你几乎无法控制模型内部的运行,只能在不同的参数和随机种子之间进行尝试。
优缺点,需要与杰神商讨再?
Checking if Disqus is accessible...