Sklearn DataSets
Sklearn 中的 data sets,很多而且有用,可以用来学习算法模型
要点
eg: boston 房价, 糖尿病, 数字, Iris 花。
也可以生成虚拟的数据,例如用来训练线性回归模型的数据,可以用函数来生成
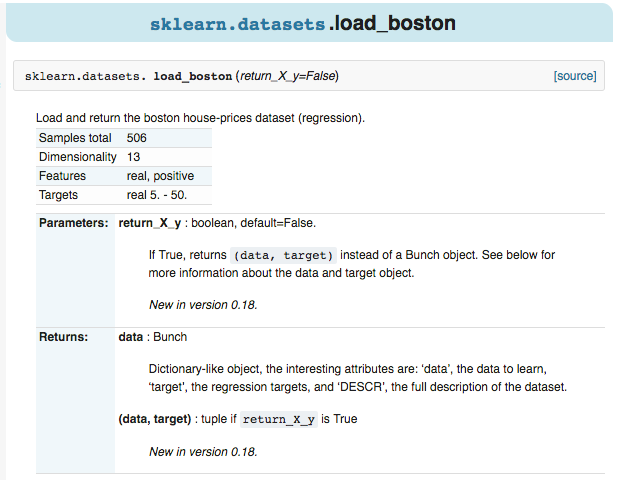
例如,点击进入 boston 房价的数据,可以看到 sample 的总数,属性,以及 label 等信息
如果是自己生成数据,按照函数的形式,输入 sample,feature,target 的个数等等。
1 | sklearn.datasets.make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)[source] |
接下来用代码练习…
导入模块
导入 datasets 包,以 Linear Regression 为例
1 | from __future__ import print_function |
导入数据-训练模型
用 datasets.load_boston() 的形式加载数据,并给 X 和 y 赋值,这种形式在 Sklearn 中都是高度统一的
1 | loaded_data = datasets.load_boston() |
[ 0.00632 0.02731 0.02729 0.03237]
[ 24. 21.6 34.7 33.4]
定义模型
可以直接用默认值去建立 model,默认值也不错,也可以自己改变参数使模型更好。 然后用 training data 训练模型
1 | model = LinearRegression() |
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
再打印出预测值,这里用 X 的前 4 个来预测,同时打印真实值,作为对比,可以看到是有些误差的
1 | print(model.predict(data_X[:4, :])) |
[ 30.00821269 25.0298606 30.5702317 28.60814055]
[ 24. 21.6 34.7 33.4]
为了提高准确度,可以通过尝试不同的 model,不同的参数,不同的预处理等方法,入门的话可以直接用默认值
创建虚拟数据-可视化
下面是创造数据的例子。
用函数来建立 100 个 sample,有一个 feature,和一个 target,这样比较方便可视化。
1 | X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=3) |
用 scatter 的形式来输出结果
1 | plt.scatter(X, y) |

可以看到用函数生成的 Linear Regression 用的数据。
noise 越大的话,点就会越来越离散,例如 noise 由 10 变为 50.
1 | X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=50) |

Checking if Disqus is accessible...