Recommendation System - CF
recommendation system and application
推荐算法
- 基于内容的推荐
- 协同过滤 CF
- 矩阵分解 与 隐语义模型
1. 推荐系统 What?
1.1 数学定义
- 设 C 为全体用户集合
- 设 S 为全部商品/推荐内容集合
- 设 u 是评判把 $s_i$ 推荐 $c_i$ 的好坏评判函数
推荐是对于 $c∈C$ ,找到 $s∈S$ ,使得 $u$ 最大
1.2 人话版本
根据用户的 :
- 历史行为
- 社交关系
- 兴趣点
- 上下文环境
- …
去判断用户的当前需求 / 感兴趣的 Item
2. 推荐系统 Why?
Infomation Overload
用户需求不明确
2.1 对用户
- 找到好玩的东西
- 发现新鲜事物 Surprise
2.2 对商家
- 个性化服务、提高粘性
- 增加营收
3. 评定标准
- 准确度
- 覆盖度
- 多样性
- 评估标准
3.1 准确度 Top N
设 $R(u)$ 为根据训练建立的模型在测试集上的推荐, $T(u)$ 为测试集上用户的选择。
Recall 说明 : 用户看的 80 篇新闻,你到底给我
推出来多少篇
3.2 覆盖率
表示对物品长尾的发掘能力 (推荐系统希望消除马太效应)
覆盖率是对平台所有物品所言,淘宝推荐等会关切这个指标。
非常独特的商品和新闻, 被看到的量, 是一条下滑曲线
希望个性化推荐,把小众的商品 也推荐展示出来
3.3 多样性
表示推荐列表中物品两两之间的不相似性.
全是牛仔裤的话,用户审美疲劳, tag(纯棉 0,圆领 1) 连衣裙, 计算 vector 距离。品类不同,相似度设为 0.
3.4 评估标准
- 新颖度 : 给用户 Surprise
- 惊喜度 : 推荐和用户历史兴趣不相似,却满意的
- 信任度 : 提供可靠的推荐理由
- 实时性 : 实时更新程度 (context, session …)
- …
4. 相似度/距离定义
- 欧氏距离
- Jaccard 相似度
- 余弦相似度
- Pearson 相似度
4.1 欧氏距离
4.2 Jaccard 相似度
适用于 top N 推荐,要么 看,要么 没看
4.3 余弦相似度
4.4 Pearson 相似度
(5, 6, 9)
(1, 2, 6)
5. 推荐算法
- 基于内容的推荐
- 协同过滤CF
- 隐语义模型
5.1 基于内容推荐
- 基于用户喜欢的 Item 的属性 / 内容进行挖掘
- 基于分析内容,无需考虑当前user与其他user的行为的交互关联等
- 通常使用在
文本相关的产品上进行推荐 - Item 通过内容 (比如 关键词) 关联
在推荐电影中,也可以使用,但是效果不见得好. 你需要手动对 Item 进行离线挖掘,拿出 tag
电影题材 : 爱情 / 探险 / 动作 / 喜剧
标志特征 : 黄晓明 / 王宝强
年代 : 1995, 2016 …
关键词
两个Item根据 tag 的分值,进行求 距离.
举例文本挖掘 :
One : 对于每个要推荐的内容,我们需要建立一份资料 :
比如词 $k_i$ 在文档 $d_j$ 中的权重 $w_{ij}$ (常用的方法比如 TF-IDF)
有一个词表 Item [$w_1$, $w_2$, … ,$w_{4000}$], 对每个 document 建立一个词表 vector。
Two : 需要对用户也建立一份资料 :
比如说定义一个权重向量 ($w_{c1},…,w_{ck}$) , 其中 $w_{ci}$ 表示第 $k_i$ 个词对用户 $c$ 的重要度
user 之前有看过的 小说 或 文档。(看过的文档放在一起搞一个doc_vector,或者 将 doc_vector 加权平均)
Three : 计算匹配度
余弦距离公式
总结三步 :
- 对 每个 document 建立 vector
- 对 每个 user 建立 vector
- 比对 user 向量,与 该user 没有看过的 document 向量 之间的相似度
TF-IDF : 评估一个 word 对当前 document 的重要性。 当前升高而升高,所有doc中,升高而下降。
Sample Example : 基于书名进行书推荐
一个用户对《Building data mining applications for CRM》感兴趣,从以下书中进行推荐 :
Building data mining applications for CRM- Accelerating Customer Relationships: Using CRM and Relationship Technologies
- Mastering Data Mining: The Art and Science of Customer Relationship Management
- Data Mining Your Website
- Introduction to marketing
- Consumer behavior
- marketing research, a handbook
- Customer knowledge manag

TF-IDF Normed Vectors 值 (0.187、0.316) 代表
Data对于当前标题的重要程度.根据 TF-IDF,当前书名 与 图书馆所有书名 出现的次数, (去掉停用词, 如 and) 计算出来的权重。
所以
《Building data mining applications for CRM》已经有一个列 vector, 与 其他所有 书 计算 相似度,相似度 高的,为推荐最好的。This is only a sample show example, not the real method of thing.
计算这本书和其余7本书的相似度,推荐最近的,这里结果为 :
rank 1 : Data Mining Your Website
rank 2 : Accelerating Custom Relationships: Using CRM …
rank 3 : Mastering Data Mining: The Art and Science… …
结论 : 基于内容的推荐,无需用户行为的交互关联。
5.2 协同过滤 (User-based)
找到和 User 最近的 其他 User , 找到他们 看/买过但当前 User 没看/买过的 item,根据距离加权打分
找得分最高的推荐
不需要提前挖掘 Item, 找品味接近的 5 个 friends。
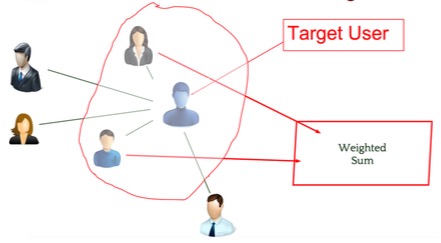
近邻怎么找 ?
| U | a | b | c | d | e |
|---|---|---|---|---|---|
| A | 5 | 1 | 5 | 3 | 2 |
| B | 4 | 3 | 1 | 1 |
5.3 协同过滤 (Item-based)
据现有 User 对 Item 的评级情况,来计算 Item 之间的某种相似度。已有Item 相似的 Item 被用来生成一个综合得分,而该得分用于评估未知物品的相似度。
根据 User 对 Item 的行为,计算 item 和 item 相似度,找到和当前 item 最近的进行推荐。
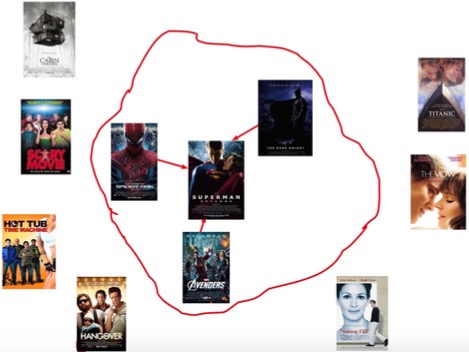
Collaborative filtering 基于 近邻 的思想
CF (Item-based) Summary :
- 一个 User List ($u_i$, i = 1, …, n), 一个 Item List ($p_j$, j = 1, …, m)
- 一个 $n * m$ 矩阵 W, 每个元素 $W_{ij}$, 表示 ${User}_i$ 对 ${Item}_j$ 的打分
- 计算 item 和 item 之间的相似度
- 选取 Top K 推荐 或 加权预测得分
Item-based Collaborative Filtering
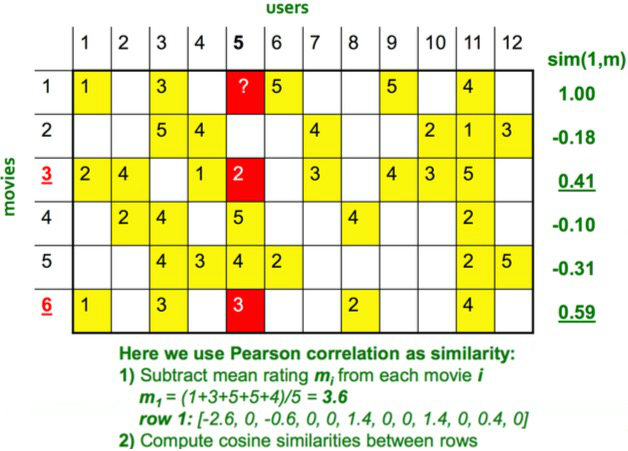
1 与 4 之间的相似度-0.10不对, 应该是 -0.83 等,数据有误。(按照 Pearson overlap 计算).
$r_{1.5}$ = (0.41*2 + 0.59*3) / (0.41 + 0.59) = 2.6
基于 Top N 来计算,这里是 Top 2.
User CF vs Item CF
| 属性 | UserCF | ItemCF |
|---|---|---|
性能 |
User多,计算User相似度矩阵代价很大 | Item多,计算Item相似度矩阵代价很大 |
领域 |
User 个性化兴趣不太明显的领域 | 长尾物品丰富,用户个性化需求强烈的领域 |
实时性 |
用户有新行为,不一定推荐结果马上变化 | 用户有新行为,会导致推荐结果实时变化 |
冷启动 |
新用户行为,不能立即进行个性化推荐 (用户相似度是每隔一段时间离线计算的) |
新用户对物品有行为,就可以给他推荐和该物品相关物品 |
推荐理由 |
很难提供令用户信服的推荐解释 | 利用用户的历史行为给用户做推荐解释 |
CF 优缺点
| 优点 | 缺点 |
|---|---|
| 基于用户行为,因此对推荐内容无需先验知识 | 需要大量的显性 / 隐性用户行为 (冷启动) |
| 只需要用户和商品关联矩阵即可,结构简单 | 需要完全相同的商品关联,相似的不同 |
| 在用户行为丰富的情况下,效果好 |
(a, c) (b, c) 通过传递关系,可以近似的计算出来 (a, b) 相似度,矩阵稀疏的二度关联。
6. 冷启动问题
6.1 New User
- 推荐 非常 热门 的商品,收集一些信息
- 用户注册的时候,收集信息,或者互动游戏,确定你喜欢否
6.2 New Item
- 根据本身属性,求与原来 Item 相似度
- Item-based CF 可推荐出去
Checking if Disqus is accessible...